Building Quantum Computers: A Practical Introduction by Shayan Majidy, Christopher Wilson, and Raymond Laflamme has been published by Cambridge University Press and will be released in the US on September 30. The authors invited me to write a Foreword for the book, which I was happy to do. The publisher kindly granted permission for me to post the Foreword here on Quantum Frontiers.
Foreword
The principles of quantum mechanics, which as far as we know govern all natural phenomena, were discovered in 1925. For 99 years we have built on that achievement to reach a comprehensive understanding of much of the physical world, from molecules to materials to elementary particles and much more. No comparably revolutionary advance in fundamental science has occurred since 1925. But a new revolution is in the offing.
Up until now, most of what we have learned about the quantum world has resulted from considering the behavior of individual particles — for example a single electron propagating as a wave through a crystal, unfazed by barriers that seem to stand in its way. Understanding that single-particle physics has enabled us to explore nature in unprecedented ways, and to build information technologies that have profoundly transformed our lives.
What’s happening now is we’re learning how to instruct particles to evolve in coordinated ways that can’t be accurately described in terms of the behavior of one particle at a time. The particles, as we like to say, can become entangled. Many particles, like electrons or photons or atoms, when highly entangled, exhibit an extraordinary complexity that we can’t capture with the most powerful of today’s supercomputers, or with our current theories of how nature works. That opens extraordinary opportunities for new discoveries and new applications.
Most temptingly, we anticipate that by building and operating large-scale quantum computers, which control the evolution of very complex entangled quantum systems, we will be able to solve some computational problems that are far beyond the reach of today’s digital computers. The concept of a quantum computer was proposed over 40 years ago, and the task of building quantum computing hardware has been pursued in earnest since the 1990s. After decades of steady progress, quantum information processors with hundreds of qubits have become feasible and are scientifically valuable. But we may need quantum processors with millions of qubits to realize practical applications of broad interest. There is still a long way to go.
Why is it taking so long? A conventional computer processes bits, where each bit could be, say, a switch which is either on or off. To build highly complex entangled quantum states, the fundamental information-carrying component of a quantum computer must be what we call a “qubit” rather than a bit. The trouble is that qubits are much more fragile than bits — when a qubit interacts with its environment, the information it carries is irreversibly damaged, a process called decoherence. To perform reliable logical operations on qubits, we need to prevent decoherence by keeping the qubits nearly perfectly isolated from their environment. That’s very hard to do. And because a qubit, unlike a bit, can change continuously, precisely controlling a qubit is a further challenge, even when decoherence is in check.
While theorists may find it convenient to regard a qubit (or a bit) as an abstract object, in an actual processor a qubit needs to be encoded in a particular physical system. There are many options. It might, for example, be encoded in a single atom which can be in either one of two long-lived internal states. Or the spin of a single atomic nucleus or electron which points either up or down along some axis. Or a single photon that occupies either one of two possible optical modes. These are all remarkable encodings, because the qubit resides in a very simple single quantum system, yet, thanks to technical advances over several decades, we have learned to control such qubits reasonably well. Alternatively, the qubit could be encoded in a more complex system, like a circuit conducting electricity without resistance at very low temperature. This is also remarkable, because although the qubit involves the collective motion of billions of pairs of electrons, we have learned to make it behave as though it were a single atom.
To run a quantum computer, we need to manipulate individual qubits and perform entangling operations on pairs of qubits. Once we can perform such single-qubit and two-qubit “quantum gates” with sufficient accuracy, and measure and initialize the qubits as well, then in principle we can perform any conceivable quantum computation by assembling sufficiently many qubits and executing sufficiently many gates.
It’s a daunting engineering challenge to build and operate a quantum system of sufficient complexity to solve very hard computation problems. That systems engineering task, and the potential practical applications of such a machine, are both beyond the scope of Building Quantum Computers. Instead the focus is on the computer’s elementary constituents for four different qubit modalities: nuclear spins, photons, trapped atomic ions, and superconducting circuits. Each type of qubit has its own fascinating story, told here expertly and with admirable clarity.
For each modality a crucial question must be addressed: how to produce well-controlled entangling interactions between two qubits. Answers vary. Spins have interactions that are always on, and can be “refocused” by applying suitable pulses. Photons hardly interact with one another at all, but such interactions can be mocked up using appropriate measurements. Because of their Coulomb repulsion, trapped ions have shared normal modes of vibration that can be manipulated to generate entanglement. Couplings and frequencies of superconducting qubits can be tuned to turn interactions on and off. The physics underlying each scheme is instructive, with valuable lessons for the quantum informationists to heed.
Various proposed quantum information processing platforms have characteristic strengths and weaknesses, which are clearly delineated in this book. For now it is important to pursue a variety of hardware approaches in parallel, because we don’t know for sure which ones have the best long term prospects. Furthermore, different qubit technologies might be best suited for different applications, or a hybrid of different technologies might be the best choice in some settings. The truth is that we are still in the early stages of developing quantum computing systems, and there is plenty of potential for surprises that could dramatically alter the outlook.
Building large-scale quantum computers is a grand challenge facing 21st-century science and technology. And we’re just getting started. The qubits and quantum gates of the distant future may look very different from what is described in this book, but the authors have made wise choices in selecting material that is likely to have enduring value. Beyond that, the book is highly accessible and fun to read. As quantum technology grows ever more sophisticated, I expect the study and control of highly complex many-particle systems to become an increasingly central theme of physical science. If so, Building Quantum Computers will be treasured reading for years to come.
A great childhood memory that I have comes from first playing “The Incredible Machine” on PC in the early 90’s. For those not in the know, this is a physics-based puzzle game about building Rube Goldberg style contraptions to achieve given tasks. What made this game a standout for me was the freedom that it granted players. In many levels you were given a disparate set of components (e.g. strings, pulleys, rubber bands, scissors, conveyor belts, Pokie the Cat…) and it was entirely up to you to “MacGuyver” your way to some kind of solution (incidentally, my favorite TV show from that time period). In other words, it was often a creative exercise in designing your own solution, rather than “connecting the dots” to find a single intended solution. Growing up with games like this undoubtedly had significant influence in directing me to my profession as a research scientist: a job which is often about finding novel or creative solutions to a task given a limited set of tools.
From the late 90’s onwards puzzle games like “The Incredible Machine” largely went out of fashion as developers focused more on 3D games that exploited that latest hardware advances. However, this genre saw a resurgence in 2010’s spearheaded by developer “Zachtronics” who released a plethora of popular, and exceptionally challenging, logic and programming based puzzle games (some of my favorites include Opus Magnum and TIS-100). Zachtronics games similarly encouraged players to solve problems through creative designs, but also had the side-effect of helping players to develop and practice tangible programming skills (e.g. design patterns, control flow, optimization). This is a really great way to learn, I thought to myself.
So, fast-forward several years, while teaching undergraduate/graduate quantum courses at Georgia Tech I began thinking about whether it would be possible to incorporate quantum mechanics (and specifically quantum circuits) into a Zachtronics-style puzzle game. My thinking was that such a game might provide an opportunity for students to experiment with quantum through a hands-on approach, one that encouraged creativity and self-directed exploration. I was also hoping that representing quantum processes through a visual language that emphasized geometry, rather than mathematical language, could help students develop intuition in this setting. These thoughts ultimately led to the development of The Qubit Factory. At its core, this is a quantum circuit simulator with a graphic interface (not too dissimilar to the Quirk quantum circuit simulator) but providing a structured sequence of challenges, many based on tasks of real-life importance to quantum computing, that players must construct circuits to solve.
An example level of The Qubit Factory in action, showcasing a potential solution to a task involving quantum error correction.The column of “?” tiles represents a noisy channel that has a small chance of flipping any qubit that passes through. Players are challenged to send qubits from the input on the left to the output on the right while mitigating errors that occur due to this noisy channel. The solution shown here is based on a bit-flip code, although a more advanced strategy is required to earn a bonus star for the level!
Quantum Gamification and The Qubit Factory
My goal in designing The Qubit Factory was to provide an accurate simulation of quantum mechanics (although not necessarily a complete one), such that players could learn some authentic, working knowledge about quantum computers and how they differ from regular computers. However, I also wanted to make a game that was accessible to the layperson (i.e. without a prior knowledge of quantum mechanics or the underlying mathematical foundations like linear algebra). These goals, which are largely opposing one-another, are not easy to balance!
A key step in achieving this balance was to find a suitable visual depiction of quantum states and processes; here the Bloch sphere, which provides a simple geometric representation of qubit states, was ideal. However, it is also here that I made my first major compromise to the scope of the physics within the game by restricting the game state to real-valued wave-functions (which in turn implies that only gates which transform qubits within the X-Z plane can be allowed). I feel that this compromise was ultimately the correct choice: it greatly enhanced the visual clarity by allowing qubits to be represented as arrows on a flat disk rather than on a sphere, and similarly allowed the action of single-qubit gates to depicted clearly (i.e. as rotations and flips on the disk). Some purists may object to this limitation on grounds that it prevents universal quantum computation, but my counterpoint would be that there are still many interesting quantum tasks and algorithms that can be performed within this restricted scope. In a similar spirit, I decided to forgo the standard quantum circuit notation: instead I used stylized circuits to emphasize the geometric interpretation as demonstrated in the example below. This choice was made with the intention of allowing players to infer the action of gates from the visual design alone.
A quantum circuit in conventional notation versus the same circuit depicted in The Qubit Factory.
Okay, so while the Bloch sphere provides a nice way to represent (unentangled) single qubit states, we also need a way to represent entangled states of multiple qubits. Here I made use of some creative license to show entangled states as blinking through the basis states. I found this visualization to work well for conveying simple states such as the singlet state presented below, but players are also able to view the complete list of wave-function amplitudes if necessary.
A singlet state is created by entangling a pair of qubits via a CNOT gate.
Although the blinking effect is not a perfect solution for displaying superpositions, I think that it is useful in conveying key aspects like uncertainty and correlation. The animation below shows an example of the entangled wave-function collapsing when one of the qubits is measured.
A single qubit from a singlet is measured. While each qubit has a 50/50 chance of giving ▲ or ▼ when measured individually, once one qubit is measured the other qubit collapses to the anti-aligned state.
So, thus far, I have described a quantum circuit simulator with some added visual cues and animations, but how can this be turned into a game? Here, I leaned heavily on the existing example of Zachtronic (and Zachtronic-like) games: each level in The Qubit Factory provides the player with some input bits/qubits and requires the player to perform some logical task in order to produce a set of desired outputs. Some of the levels within the game are highly structured, similar to textbook exercises. They aim to teach a specific concept and may only have a narrow set of potential solutions. An example of such a structured level is the first quantum level (lvl QI.A) which tasks the player with inverting a sequence of single qubit gates. Of course, this problem would be trivial to those of you already familiar with quantum mechanics: you could use the linear algebra result together with the knowledge that quantum gates are unitary, so the Hermitian conjugate of each gate doubles as its inverse. But what if you didn’t know quantum mechanics, or even linear algebra? Could this problem be solved through logical reasoning alone? This is where I think that the visuals really help; players should be able to infer several key points from geometry alone:
the inverse of a flip (or mirroring about some axis) is another equal flip.
the inverse of a rotation is an equal rotation in the opposite direction.
the last transformation done on each qubit should be the first transformation to be inverted.
So I think it is plausible that, even without prior knowledge in quantum mechanics or linear algebra, a player could not only solve the level but also grasp some important concepts (i.e. that quantum gates are invertible and that the order in which they are applied matters).
An early level challenges the player to invert the action of the 3gates on the left.A solution is given on the right, formed by composing the inverse of each gate in reverse order.
Many of the levels in The Qubit Factory are also designed to be open-ended. Such levels, which often begin with a blank factory, have no single intended solution. The player is instead expected to use experimentation and creativity to design their own solution; this is the setting where I feel that the “game” format really shines. An example of an open-ended level is QIII.E, which gives the player 4 copies of a single qubit state , guaranteed to be either the or eigenstate, and tasks the player to determine which state they have been given. Those familiar with quantum computing will recognize this as a relatively simple problem in state tomography. There are many viable strategies that could be employed to solve this task (and I am not even sure of the optimal one myself). However, by circumventing the need for a mathematical calculation, the Qubit Factory allows players to easily and quickly explore different approaches. Hopefully this could allow players to find effective strategies through trial-and-error, gaining some understanding of state tomography (and why it is challenging) in the process.
An example of a level in action! This levelchallenges the player to construct a circuit that can identify an unknown qubit state given several identical copies; a task in state tomography.The solution shown here uses a cascaded sequence of measurements, where the result of one measurement is used to control the axis of a subsequent measurement.
The Qubit Factory begins with levels covering the basics of qubits, gates and measurements. It later progresses to more advanced concepts like superpositions, basis changes and entangled states. Finally it culminates with levels based on introductory quantum protocols and algorithms (including quantum error correction, state tomography, super-dense coding, quantum repeaters, entanglement distillation and more). Even if you are familiar with the aforementioned material you should still be in for a substantial challenge, so please check it out if that sounds like your thing!
The Potential of Quantum Games
I believe that interactive games have great potential to provide new opportunities for people to better understand the quantum realm (a position shared by the IQIM, members of which have developed several projects in this area). As young children, playing is how we discover the world around us and build intuition for the rules that govern it. This is perhaps a significant reason why quantum mechanics is often a challenge for new students to learn; we don’t have direct experience or intuition with the quantum world in the same way that we do with the classical world. A quote from John Preskill puts it very succinctly:
“Perhaps kids who grow up playing quantum games will acquire a visceral understanding of quantum phenomena that our generation lacks.”
John Preskill, Richard P. Feynman Professor of Theoretical Physics at Caltech, has been named the 2024 John Stewart Bell Prize recipient. The prize honors John’s contributions in “the developments at the interface of efficient learning and processing of quantum information in quantum computation, and following upon long standing intellectual leadership in near-term quantum computing.” The committee cited John’s seminal work defining the concept of the NISQ (noisy intermediate-scale quantum) era, our joint work “Predicting Many Properties of a Quantum System from Very Few Measurements” proposing the classical shadow formalism, along with subsequent research that builds on classical shadows to develop new machine learning algorithms for processing information in the quantum world.
We are truly honored that our joint work on classical shadows played a role in John winning this prize. But as the citation implies, this is also a much-deserved “lifetime achievement” award. For the past two and a half decades, first at IQI and now at IQIM, John has cultivated a wonderful, world-class research environment at Caltech that celebrates intellectual freedom, while fostering collaborations between diverse groups of physicists, computer scientists, chemists, and mathematicians. John has said that his job is to shield young researchers from bureaucratic issues, teaching duties and the like, so that we can focus on what we love doing best. This extraordinary generosity of spirit has been responsible for seeding the world with some of the bests minds in the field of quantum information science and technology.
It is in this environment that the two of us (Robert and Richard) met and first developed the rudimentary form of classical shadows — inspired by Scott Aaronson’s idea of shadow tomography. While the initial form of classical shadows is mathematically appealing and was appreciated by the theorists (it was a short plenary talk at the premier quantum information theory conference), it was deemed too abstract to be of practical use. As a result, when we submitted the initial version of classical shadows for publication, the paper was rejected. John not only recognized the conceptual beauty of our initial idea, but also pointed us towards a direction that blossomed into the classical shadows we know today. Applications range from enabling scientists to more efficiently understand engineered quantum devices, speeding up various near-term quantum algorithms, to teaching machines to learn and predict the behavior of quantum systems.
Congratulations John! Thank you for bringing this community together to do extraordinarily fun research and for guiding us throughout the journey.
Have you ever wondered what can be done in 48 hours? For instance, our heart beats around 200 000 times. One of the biggest supercomputers crunches petabytes (peta = 1015) of numbers to simulate an experiment that took Google’s quantum processor only 300 seconds to run. In 48 hours, one can also participate in the Sciathon with almost 500 young researchers from more than 80 countries!
Two weeks ago I participated in a scientific marathon, the Sciathon. The structure of this event roughly resembled a hackathon. I am sure many readers are familiar with the idea of a hackathon from personal experience. For those unfamiliar — a hackathon is an intense collaborative event, usually organized over the weekend, during which people with different backgrounds work in groups to create prototypes of functioning software or hardware. For me, it was the very first time to have firsthand experience with a hackathon-like event!
The Sciathon was organized by the Lindau Nobel Laureate Meetings (more about the meetings with Nobel laureates, which happen annually in the lovely German town of Lindau, in another blogpost, I promise!) This year, unfortunately, the face-to-face meeting in Lindau was postponed until the summer of 2021. Instead, the Lindau Nobel Laureate Meetings alumni and this year’s would-be attendees had an opportunity to gather for the Sciathon, as well as the Online Science Days earlier this week, during which the best Sciathon projects were presented.
The participants of the Sciathon could choose to contribute new views, perspectives and solutions to three main topics: Lindau Guidelines, Communicating Climate Change and Capitalism After Corona. The first topic concerned an open, cooperative science community where data and knowledge are freely shared, the second — how scientists could show that the climate crisis is just as big a threat as the SARS-CoV-19 virus, and the last — how to remodel our current economic systems so that they are more robust to unexpected sudden crises. More detailed descriptions of each topic can be found on the official Sciathon webpage.
My group of ten eager scientists, mostly physicists, from master students to postdoctoral researchers, focused on the first topic. In particular, our goal was to develop a method of familiarizing high school students with the basics of quantum information and computation. We envisioned creating an online notebook, where an engaging story would be intertwined with interactive blocks of Python code utilizing the open-source quantum computing toolkit Qiskit. This hands-on approach would enable students to play with quantum systems described in the story-line by simply running the pre-programmed commands with a click of the mouse and then observe how “experiment” matches “the theory”. We decided to work with a system comprising one or two qubits and explain such fundamental concepts in quantum physics as superposition, entanglement and measurement. The last missing part was a captivating story.
We prepared a two-minute video to illustrate our idea of explaining basic concepts of quantum physics as a children’s fairy tale intertwined with interactive blocks of Python code.
The story we came up with involved two good friends from the lab, Miss Schrödinger and Miss Pauli, as well as their kittens, Alice and Bob. At first, Alice and Bob seemed to be ordinary cats, however whenever they sipped quantum milk, they would turn into quantum cats, or as quantum physicists would say — kets. Do I have to remind the reader that a quantum cat, unlike an ordinary one, could be both awake and asleep at the same time?
Miss Schrödinger was a proud cat owner who not only loved her cat, but also would take hundreds of pictures of Alice and eagerly upload them on social media. Much to Miss Schrödinger’s surprise, none of the pictures showed Alice partly awake and partly asleep — the ket would always collapse to the cat awake or the cat asleep! Every now and then, Miss Pauli would come to visit Miss Schrödinger and bring her own cat Bob. While the good friends were chit-chatting over a cup of afternoon tea, the cats sipped a bit of quantum milk and started to play with a ball of wool, resulting in a cute mess of two kittens tangled up in wool. Every time after coming back home, Miss Pauli would take a picture of Bob and share it with Miss Schrödinger, who would obviously also take a picture of Alice. After a while, the young scientists started to notice some strange correlations between the states of their cats…
The adventures of Miss Schrödinger and her cat continue! For those interested, you can watch a short video about our project!
Overall, I can say that I had a lot of fun participating in the Sciathon. It was an intense yet extremely gratifying event. In addition to the obvious difficulty of racing against the clock, our group also had to struggle with coordinating video calls between group members scattered across three almost equidistant time zones — Eastern Australian, Central European and Central US! During the Sciathon I had a chance to interact with other science enthusiasts from different backgrounds and work on something from outside my area of expertise. I would strongly encourage anyone to participate in hackathon-like events to break the daily routine, particularly monotonous during the lockdown, and unleash one’s creative spirit. Such events can also be viewed as an opportunity to communicate science and scientific progress to the public. Lastly, I would like to thank other members of my team — collaborating with you during the Sciathon was a blast!
During the Sciathon, we had many brainstorming sessions. You can see most of the members of my group in this video call (from left to right, top to bottom): Shuang, myself, Martin, Kyle, Hadewijch, Saskia, Michael and Bartłomiej. The team also included Ahmed and Watcharaphol.
In the previous blog post (titled, “On the Coattails of Quantum Supremacy“) we started with Google and ended up with molecules! I also mentioned a recent paper by John Preskill, Jake Covey, and myself (see also this videoed talk) where we assume that, somewhere in the (near?) future, experimentalists will be able to construct quantum superpositions of several orientations of molecules or other rigid bodies. Next, I’d like to cover a few more details on how to construct error-correcting codes for anything from classical bits in your phone to those future quantum computers, molecular or otherwise.
Classical error correction: the basics
Error correction is concerned with the design of an encoding that allows for protection against noise. Let’s say we want to protect one classical bit, which is in either “0” or “1”. If the bit is say in “0”, and the environment (say, the strong magnetic field from a magnet you forgot was laying next to your hard drive) flipped it to “1” without our knowledge, an error would result (e.g., making your phone think you swiped right!)
Now let’s encode our single logical bit into three physical bits, whose possible states are represented by the eight corners of the cube below. Let’s encode the logical bit as “0” —> 000 and “1” —> 111, corresponding to the corners of the cube marked by the black and white ball, respectively. For our (local) noise model, we assume that flips of only one of the three physical bits are more likely to occur than flips of two or three at the same time.
Error correction is, like many Hollywood movies, an origin story. If, say, the first bit flips in our above code, the 000 state is mapped to 100, and 111 is mapped to 011. Since we have assumed that the most likely error is a flip of one of the bits, we know upon observing that 100 must have come from the clean 000, and 011 from 111. Thus, in either case of the logical bit being “0” or “1”, we can recover the information by simply observing which state the majority of the bits are in. The same things happen when the second or third bits flip. In all three cases, the logical “0” state is mapped to one of its three neighboring points (above, in blue) while the logical “1” is mapped to its own three points, which, crucially, are distinct from the neighbors of “0”. The set of points that are closer to 000 than to 111 is called a Voronoi tile.
Now, let’s adapt these ideas to molecules. Consider the rotational states of a dumb-bell molecule consisting of two different atoms. (Let’s assume that we have frozen this molecule to the point that the vibration of the inter-atomic bond is limited, essentially creating a fixed distance between the two atoms.) This molecule can orient itself in any direction, and each such orientation can be represented as a point on the surface of a sphere. Now let us encode a classical bit using the north and south poles of this sphere (represented in the picture below as a black and a white ball, respectively). The north pole of the sphere corresponds to the molecule being parallel to the z-axis, while the south pole corresponds to the molecule being anti-parallel.
This time, the noise consists of small shifts in the molecule’s orientation. Clearly, if such shifts are small, the molecule just wiggles a bit around the z-axis. Such wiggles still allow us to infer that the molecule is (mostly) parallel and anti-parallel to the axis, as long as they do not rotate the molecule all the way past the equator. Upon such correctable rotations, the logical “0” state — the north pole — is mapped to a point in the northern hemisphere, while logical “1” — the south pole — is mapped to a point in the southern hemisphere. The northern hemisphere forms a Voronoi tile of the logical “0” state (blue in the picture), which, along with the corresponding tile of the logical “1” state (the southern hemisphere), tiles the entire sphere.
Quantum error correction
To upgrade these ideas to the quantum realm, recall that this time we have to protect superpositions. This means that, in addition to shifting our quantum logical state to other states as before, noise can also affect the terms in the superposition itself. Namely, if, say, the superposition is equal — with an amplitude of in “0” and in “1” — noise can change the relative sign of the superposition and map one of the amplitudes to . We didn’t have to worry about such sign errors before, because our classical information would always be the definite state of “0” or “1”. Now, there are two effects of noise to worry about, so our task has become twice as hard!
Not to worry though. In order to protect against both sources of noise, all we need to do is effectively stagger the above constructions. Now we will need to design a logical “0” state which is itself a superposition of different points, with each point separated from all of the points that are superimposed to make the logical “1” state.
Diatomic molecules: For the diatomic molecule example, consider superpositions of all four corners of two antipodal tetrahedra for the two respective logical states.
The logical “0” state for the quantum code is now itself a quantum superposition of orientations of our diatomic molecule corresponding to the four black points on the sphere to the left (the sphere to the right is a top-down view). Similarly, the logical “1” quantum state is a superposition of all orientations corresponding to the white points.
Each orientation (black or white point) present in our logical states rotates under fluctuations in the position of the molecule. However, the entire set of orientations for say logical “0” — the tetrahedron — rotates rigidly under such rotations. Therefore, the region from which we can successfully recover after rotations is fully determined by the Voronoi tile of any one of the corners of the tetrahedron. (Above, we plot the tile for the point at the north pole.) This cell is clearly smaller than the one for classical north-south-pole encoding we used before. However, the tetrahedral code now provides some protection against phase errors — the other type of noise that we need to worry about if we are to protect quantum information. This is an example of the trade-off we must make in order to protect against both types of noise; a licensed quantum mechanic has to live with such trade-offs every day.
Oscillators: Another example of a quantum encoding is the GKP encoding in the phase space of the harmonic oscillator. Here, we have at our disposal the entire two-dimensional plane indexing different values of position and momentum. In this case, we can use a checkerboard approach, superimposing all points at the centers of the black squares for the logical “0” state, and similarly all points at the centers of the white squares for the logical “1”. The region depicting correctable momentum and position shifts is then the Voronoi cell of the point at the origin: if a shift takes our central black point to somewhere inside the blue square, we know (most likely) where that point came from! In solid state circles, the blue square is none other than the primitive or unit cell of the lattice consisting of points making up both of the logical states.
Asymmetric molecules (a.k.a. rigid rotors): Now let’s briefly return to molecules. Above, we considered diatomic molecules that had a symmetry axis, i.e., that were left unchanged under rotations about the axis that connects the two atoms. There are of course more general molecules out there, including ones that are completely asymmetric under any possible (proper) 3D rotation (see figure below for an example).
BONUS: There is a subtle mistake relating to the geometry of the rotation group in the labeling of this figure. Let me know if you can find it in the comments!
All of the orientations of the asymmetric molecule, and more generally a rigid body, can no longer be parameterized by the sphere. They can be parameterized by the 3D rotation group : each orientation of an asymmetric molecule is labeled by the 3D rotation necessary to obtain said orientation from a reference state. Such rotations, and in turn the orientations themselves, are parameterized by an axis (around which to rotate) and an angle (by which one rotates). The rotation group luckily can still be viewed by humans on a sheet of paper. Namely, can be thought of as a ball of radius with opposite points identified. The direction of each vector lying inside the ball corresponds to the axis of rotation, while the length corresponds to the angle. This may take some time to digest, but it’s not crucial to the story.
So far we’ve looked at codes defined on cubes of bits, spheres, and phase-space lattices. Turns out that even can house similar encodings! In other words, can also be cut up into different Voronoi tiles, which in turn can be staggered to create logical “0” and “1” states consisting of different molecular orientations. There are many ways to pick such states, corresponding to various subgroups of . Below, we sketch two sets of black/white points, along with the Voronoi tile corresponding to the rotations that are corrected by each encoding.
Voronoi tiles of the black point at the center of the ball representing the 3D rotation group, for two different molecular codes. This and the Voronoi cells corresponding to the other points tile together to make up the entire ball. 3D printing all of these tiles would make for cool puzzles!
In closing…
Achieving supremacy was a big first step towards making quantum computing a practical and universal tool. However, the largest obstacles still await, namely handling superposition-poisoning noise coming from the ever-curious environment. As quantum technologies advance, other possible routes for error correction are by encoding qubits in harmonic oscillators and molecules, alongside the “traditional” approach of using arrays of physical qubits. Oscillator and molecular qubits possess their own mechanisms for error correction, and could prove useful (granted that the large high-energy space required for the procedures to work can be accessed and controlled). Even though molecular qubits are not yet mature enough to be used in quantum computers, we have at least outlined a blueprint for how some of the required pieces can be built. We are by no means done however: besides an engineering barrier, we need to further develop how to run robust computations on these exotic spaces.
Author’s note: I’d like to acknowledge Jose Gonzalez for helping me immensely with the writing of this post, as well as for drawing the comic panels in the previous post. The figures above were made possible by Mathematica 12.
Most readers have by now heard that Google has “achieved” quantum “supremacy”. Notice the only word not in quotes is “quantum”, because unlike previous proposals that have also made some waves, quantumness is mostly not under review here. (Well, neither really are the other two words, but that story has already been covered quite eloquently by John, Scott, and Toby.) The Google team has managed to engineer a device that, although noisy, can do the right thing a large-enough fraction of the time for people to be able to “quantify its quantumness”.
However, the Google device, while less so than previous incarnations, is still noisy. Future devices like it will continue to be noisy. Noise is what makes quantum computers so darn difficult to build; it is what destroys the fragile quantum superpositions that we are trying so hard to protect (remember, unlike a classical computer, we are not protecting things we actually observe, but their superposition).
Protecting quantum information is like taking your home-schooled date (who has lived their entire life in a bunker) to the prom for the first time. It is a fun and necessary part of a healthy relationship to spend time in public, but the price you pay is the possibility that your date will hit it off with someone else. This will leave you abandoned, dancing alone to Taylor Swift’s “You Belong With Me” while crying into your (spiked?) punch.
When the environment corrupts your quantum date.
The high school sweetheart/would-be dance partner in the above provocative example is the quantum superposition — the resource we need for a working quantum computer. You want it all to yourself, but your adversary — the environment — wants it too. No matter how much you try to protect it, you’ll have to observe it eventually (after all, you want to know the answer to your computation). And when you do (take your date out onto the crowded dance floor), you run the risk of the environment collapsing the information before you do, leaving you with nothing.
Protecting quantum information is also like (modern!) medicine. The fussy patient is the quantum information, stored in delicate superposition, while quantumists are the doctors aiming to prevent the patient from getting sick (or “corrupted”). If our patient incurs say “quasiparticle poisoning”, we first diagnose the patient’s syndromes, and, based on this diagnosis, apply procedures like “lattice surgery” and “state injection” to help our patient successfully recover.
The medical analogy to QEC, noticed first by Daniel Litinski. All terms are actually used in papers. Cartoon by Jose Gonzalez.
Error correction with qubits
Error correction sounds hard, and it should! Not to fear: plenty of very smart people have thought hard about this problem, and have come up with a plan — to redundantly encode the quantum superposition in a way that allows protection from errors caused by noise. Such quantum error-correction is an expansion of the techniques we currently use to protect classical bits in your phone and computer, but now the aim is to protect, not the definitive bit states 0 or 1, but their quantum superpositions. Things are even harder now, as the protection machinery has to do its magic without disturbing the superposition itself (after all, we want our quantum calculation to run to its conclusion and hack your bank).
For example, consider a qubit — the fundamental quantum unit represented by two shelves (which, e.g., could be the ground and excited states of an atom, the absence or presence of a photon in a box, or the zeroth and first quanta of a really cold LC circuit). This qubit can be in any quantum superposition of the two shelves, described by 2 probability amplitudes, one corresponding to each shelf. Observing this qubit will collapse its state onto either one of the shelves, changing the values of the 2 amplitudes. Since the resource we use for our computation is precisely this superposition, we definitely do not want to observe this qubit during our computation. However, we are not the only ones looking: the environment (other people at the prom: the trapping potential of our atom, the jiggling atoms of our metal box, nearby circuit elements) is also observing this system, thereby potentially manipulating the stored quantum state without our knowledge and ruining our computation.
Now consider 50 such qubits. Such a space allows for a superposition with different amplitudes (instead of just for the case of a single qubit). We are once again plagued by noise coming from the environment. But what if we now, less ambitiously, want to store only one qubit’s worth of information in this 50-qubit system? Now there is room to play with! A clever choice of how to do this (a.k.a. the encoding) helps protect from the bad environment.
The entire prospect of building a bona-fide quantum computer rests on this extra overhead or quantum redundancy of using a larger system to encode a smaller one. It sounds daunting at first: if we need 50 physical qubits for each robust logical qubit, then we’d need “I-love-you-3000” physical qubits for 60 logical ones? Yes, this is a fact we all have to live with. But granted we can scale up our devices to that many qubits, there is no fundamental obstacle that prevents us from then using error correction to make next-level computers.
To what extent do we need to protect our quantum superposition from the environment? It would be too ambitious to protect it from a meteor shower. Or a power outage (although that would be quite useful here in California). So what then can we protect against?
Our working answer is local noise — noise that affects only a few qubits that are located near each other in the device. We can never be truly certain if this type of noise is all that our quantum computers will encounter. However, our belief that this is the noise we should focus on is grounded in solid physical principles — that nature respects locality, that affecting things far away from you is harder than making an impact nearby. (So far Google has not reported otherwise, although much more work needs to be done to verify this intuition.)
The harmonic oscillator
In what other ways can we embed our two-shelf qubit into a larger space? Instead of scaling up using many physical qubits, we can utilize a fact that we have so far swept under the rug: in any physical system, our two shelves are already part of an entire bookcase! Atoms have more than one excited state, there can be more than one photon in a box, and there can be more than one quantum in a cold LC circuit. Why don’t we use some of that higher-energy space for our redundant encoding?
The noise in our bookcase will certainly be different, since the structure of the space, and therefore the notion of locality, is different. How to cope with this? The good news is that such a space — the space of the harmonic oscillator — also has a(t least one) natural notion of locality!
Whatever the incarnation, the oscillator has associated with it a position and momentum (different jargon for these quantities may be used, depending on the context, but you can just think of a child on a swing, just quantized). Anyone who knows the joke about Heisenberg getting pulled over, will know that these two quantities cannot be set simultaneously.
Cartoon by Jose Gonzalez.
Nevertheless, local errors can be thought of as small shifts in position or momentum, while nonlocal errors are ones that suddenly shift our bewildered swinging quantized child from one side of the swing to the other.
Armed with a local noise model, we can extend our know-how from multi-qubit land to the oscillator. One of the first such oscillator codes were developed by Gottesman, Kitaev, and Preskill (GKP). Proposed in 2001, GKP encodings posed a difficult engineering challenge: some believed that GKP states could never be realized, that they “did not exist”. In the past few years however, GKP states have been realized nearly simultaneously in two experimentalplatforms. (Food for thought for the non-believers!)
Parallel to GKP codes, another promising oscillator encoding using cat states is also being developed. This encoding has historically been far easier to create experimentally. It is so far the only experimental procedure achieving the break-even point, at which the actively protected logical information has the same lifetime as the system’s best unprotected degree of freedom.
Can we mix and match all of these different systems? Why yes! While Google is currently trying to build the surface code out of qubits, using oscillators (instead of qubits) for the surface code and encoding said oscillators either in GKP (see related IBM post) [1,2,3] or cat [4,5] codes is something people are seriously considering. There is even more overhead, but the extra information one gets from the correction procedure might make for a more fault-tolerant machine. With all of these different options being explored, it’s an exciting time to be into quantum!
Molecules?
It turns out there are still other systems we can consider, although because they are sufficiently more “out there” at the moment, I should first say “bear with me!” as I explain. Forget about atoms, photons in a box, and really cold LC circuits. Instead, consider a rigid 3-dimensional object whose center of mass has been pinned in such a way that the object can rotate any way it wants. Now, “quantize” it! In other words, consider the possibility of having quantum superpositions of different orientations of this object. Just like superpositions of a dead and alive cat, of a photon and no photon, the object can be in quantum superposition of oriented up, sideways, and down, for example. Superpositions of all possible orientations then make up our new configuration space (read: playground), and we are lucky that it too inherits many of the properties we know and love from its multi-qubit and oscillator cousins.
Examples of rigid bodies include airplanes (which can roll, pitch and yaw, even while “fixed” on a particular trajectory vector) and robot arms (which can rotate about multiple joints). Given that we’re not quantizing those (yet?), what rigid body should we have in mind as a serious candidate? Well, in parallel to the impressive engineering successes of the multi-qubit and oscillator paradigms, physicists and chemists have made substantial progress in trapping and cooling molecules. If a trapped molecule is cold enough, it’s vibrational and electronic states can be neglected, and its rotational states form exactly the rigid body we are interested in. Such rotational states, as far as we can tell, are not in the realm of Avengers-style science fiction.
The idea to use molecules for quantum computing dates all the way back to a 2001 paper by Dave DeMille, but in a recent paper by Jacob Covey, John Preskill, and myself, we propose a framework of how to utilize the large space of molecular orientations to protect against (you guessed it!) a type of local noise. In the second part of the story, called “Quantum Error Correction with Molecules“, I will cover a particular concept that is not only useful for a proper error-correcting code (classical and quantum), but also one that is quite fun to try and understand. The concept is based on a certain kind of tiling, called Voronoi tiles or Thiessen polygons, which can be used to tile anything from your bathroom floor to the space of molecular orientations. Stay tuned!
A few months ago I sat down with Craig Cannon of Y Combinator for a discussion about quantum technology and other things. A lightly edited version was published this week on the Y Combinator blog. The video is also on YouTube:
If you’re in a hurry, or can’t stand the sound of my voice, you might prefer to read the transcript, which is appended below. Only by watching the video, however, can you follow the waving of my hands.
I grabbed the transcript from the Y Combinator blog post, so you can read it there if you prefer, but I’ve corrected some of the typos. (There are a few references to questions and comments that were edited out, but that shouldn’t cause too much confusion.)
Here we go:
Craig Cannon [00:00:00] – Hey, how’s it going? This is Craig Cannon, and you’re listening to Y Combinator’s Podcast. Today’s episode is with John Preskill. John’s a theoretical physicist and the Richard P. Feynman Professor of Theoretical Physics at Caltech. He once won a bet with Stephen Hawking and he writes that it made him briefly almost famous. Basically, what happened is John and Kip Thorne bet that singularities could exist outside of black holes. After six years, Hawking conceded. He said that they were possible in very special, “non-generic conditions.” I’ll link up some more details to that in the description. In this episode, we cover what John’s been focusing on for years, which is quantum information, quantum computing, and quantum error correction. Alright, here we go. What was the revelation that made scientists and physicists think that a quantum computer could exist?
John Preskill [00:00:54] – It’s not obvious. A lot of people thought it couldn’t. The idea that a quantum computer would be powerful was emphasized over 30 years ago by Richard Feynman, the Caltech physicist. It was interesting how he came to that realization. Feynman was interested in computation his whole life. He had been involved during the war in Los Alamos. He was the head of the computation group. He was the guy who fixed the little mechanical calculators, and he had a whole crew of people who were calculating, and he figured out how to flow the work from one computer to another. All that kind of stuff. As computing technology started to evolve, he followed that. In the 1970s, a particle physicist like Feynman, that’s my background too, got really interested in using computers to study the properties of elementary particles like the quarks inside a nucleus, you know? We know a proton isn’t really a fundamental object. It’s got little beans rattling around inside, but they’re quantum beans. Gell-Mann, who’s good at names, called them quarks.
John Preskill [00:02:17] – Now we’ve had a theory since the 1970s of how quarks behave, and so in principle, you know everything about the theory, you can compute everything, but you can’t because it’s just too hard. People started to simulate that physics with digital computers in the ’70s, and there were some things that they could successfully compute, and some things they couldn’t because it was just too hard. The resources required, the memory, the time were out of reach. Feynman, in the early ’80s said nature is quantum mechanical damn it, so if you want a simulation of nature, it should be quantum mechanical. You should use a quantum system to behave like another quantum system. At the time, he called it a universal quantum simulator.
John Preskill [00:03:02] – Now we call it a quantum computer. The idea caught on about 10 years later when Peter Shor made the suggestion that we could solve problems which don’t seem to have anything to do with physics, which are really things about numbers like finding the prime factors of a big integer. That caused a lot of excitement, in part because the implications for cryptography are a big disturbing. But then physicists — good physicists — started to consider, can we really build this thing? Some concluded and argued fairly cogently that no, you couldn’t because of this difficulty that it’s so hard to isolate systems from the environment well enough for them to behave quantumly. It took a few years for that to sort out at the theoretical level. In the mid ’90s we developed a theory called quantum error correction. It’s about how to encode the quantum state that you’d like to protect in such a clever way that even if there are some interactions with the environment that you can’t control, it still stays robust.
John Preskill [00:04:17] – At first, that was just kind of a theorist’s fantasy — it was a little too far ahead of the technology. But 20 years later, the technology is catching up, and now this idea of quantum error correction has become something you can do in the lab.
Craig Cannon [00:04:31] – How does quantum error correction work? I’ve seen a bunch of diagrams, so maybe this is difficult to explain, but how would you explain it?
John Preskill [00:04:39] – Well, I would explain it this way. I don’t think I’ve said the word entanglement yet, have I?
Craig Cannon [00:04:43] – Well, I have been checking off all the Bingo words yet.
John Preskill [00:04:45] – Okay, so let’s talk about entanglement because it’s part of the answer to your question, which I’m still not done answering, what is quantum physics? What do we mean by entanglement? It’s really the characteristic way, maybe the most important way that we know in which quantum is different from ordinary stuff, from classical. Now what does it mean, entanglement? It means that you can have a physical system which has many parts, which have interacted with one another, so it’s in kind of a complex correlated state of all those parts, and when you look at the parts one at a time it doesn’t tell you anything about the state of the whole thing. The whole thing’s in some definite state — there’s information stored in it — and now you’d like to access that information … Let me be a little more concrete. Suppose it’s a book.
John Preskill [00:05:40] – Okay? It’s a book, it’s 100 pages long. If it’s an ordinary book, 100 people could each take a page, and read it, they know what’s on that page, and then they could get together and talk, and now they’d know everything that’s in the book, right? But if it’s a quantum book written in qubits where these pages are very highly entangled, there’s still a lot of information in the book, but you can’t read it the way I just described. You can look at the pages one at a time, but a single page when you look at it just gives you random gibberish. It doesn’t reveal anything about the content of the book. Why is that? There’s information in the book, but it’s not stored in the individual pages. It’s encoded almost entirely in how those pages are correlated with one another. That’s what we mean by quantum entanglement: Information stored in those correlations which you can’t see when you look at the parts one at a time. You asked about quantum error correction?
John Preskill [00:06:39] – What’s the basic idea? It’s to take advantage of that property of entanglement. Because let’s say you have a system of many particles. The environment is kind of kicking them around, it’s interacting with them. You can’t really completely turn off those interactions no matter how hard you try, but suppose we’ve encoded the information in entanglement. So, say, if you look at one atom, it’s not telling you anything about the information you’re trying to protect. The environment isn’t learning anything when it looks at the atoms one at a time.
John Preskill [00:07:15] – This is kind of the key thing — that what makes quantum information so fragile is that when you look at it, you disturb it. This ordinary water bottle isn’t like that. Let’s say we knew it was either here or here, and we didn’t know. I would look at it, I’d find out it’s here. I was ignorant of where it was to start with, and now I know. With a quantum system, when you look at it, you really change the state. There’s no way to avoid that. So if the environment is looking at it in the sense that information is leaking out to the environment, that’s going to mess it up. We have to encode the information so the environment, so to speak, can’t find out anything about what the information is, and that’s the idea of quantum error correction. If we encode it in entanglement, the environment is looking at the parts one at a time, but it doesn’t find out what the protected information is.
Craig Cannon [00:08:06] – In other words, it’s kind of measuring probability the whole way along, right?
John Preskill [00:08:12] – I’m not sure what you mean by that.
Craig Cannon [00:08:15] – Is it Grover’s algorithm that was as quantum bits roll through, go through gates– The probability is determined of what information’s being passed through? What’s being computed?
John Preskill [00:08:30] – Grover’s algorithm is a way of sort of doing an exhaustive search through many possibilities. Let’s say I’m trying to solve some problem like a famous one is the traveling salesman problem. I’ve told you what the distances are between all the pairs of cities, and now I want to find the shortest route I can that visits them all. That’s a really hard problem. It’s still hard for a quantum computer, but not quite as hard because there’s a way of solving it, which is to try all the different routes, and measure how long they are, and then find the one that’s shortest, and you’ve solved the problem. The reason it’s so hard to solve is there’s such a vast number of possible routes. Now what Grover’s algorithm does is it speeds up that exhaustive search.
John Preskill [00:09:29] – In practice, it’s not that big a deal. What it means is that if you had the same processing speed, you can handle about twice as many cities before the problem becomes too hard to solve, as you could if you were using a classical processor. As far as what’s quantum about Grover, it takes advantage of the property in quantum physics that probabilities … tell me if I’m getting too inside baseball …
Craig Cannon [00:10:03] – No, no, this is perfect.
John Preskill [00:10:05] – That probabilities are the squares of amplitudes. This is interference. Again, this is another part of the answer. Well, we can spend the whole hour answering the question, what is quantum physics? Another essential part of it is what we call interference, and this is really crucial for understanding how quantum computing works. That is that probabilities add. If you know the probability of one alternative, and you know the probability of another, then you can add those together and find the probability that one or the other occurred. It’s not like that in quantum physics. The famous example is the double slit interference experiment. I’m sending electrons, let’s say — it could be basketballs, but it’s an easier experiment to do with electrons —
John Preskill [00:11:02] – at a screen, and there are two holes in the screen. You can try to detect the electron on the other side of the screen, and when you do that experiment many times, you can plot a graph showing where the electron was detected in each run, or make a histogram of all the different outcomes. And the graph wiggles, okay? If you could say there’s some probability of going through the first hole, and some probability of going through the second, and each time you detected it, it went through either one or the other, there’d be no wiggles in that graph. It’s the interference that makes it wiggle. The essence of the interference is that nobody can tell you whether it went through the first slit or the second slit. The question is sort of inadmissible. This interference then occurs when we can add up these different alternatives in a way which is different from what we’re used to. It’s not right to say that the electron was detected at this point because it had some probability of going through the first hole, and some probability of going through the second
John Preskill [00:12:23] – and we add those probabilities up. That doesn’t give the right answer. The different alternatives can interfere. This is really important for quantum computing because what we’re trying to do is enhance the probability or the time it takes to find the solution to a problem, and this interference can work to our advantage. We want to have, when we’re doing our search, we want to have a higher chance of getting the right answer, and a lower chance of getting the wrong answer. If the different wrong answers can interfere, they can cancel one another out, and that enhances the probability of getting the right answer. Sorry it’s such a long-winded answer, but this is how Grover’s algorithm works.
John Preskill [00:13:17] – It can speed up exhaustive search by taking advantage of that interference phenomenon.
Craig Cannon [00:13:20] – Well this is kind of one of the underlying questions among many of the questions from Twitter. You’ve hit our record for most questions asked. Basically, many people are wondering what quantum computers really will do if and when it becomes a reality that they outperform classical computers. What are they going to be really good at?
John Preskill [00:13:44] – Well, you know what? I’m not really sure. If you look at the history of technology, it would be hubris to expect me to know. It’s a whole different way of dealing with information. Quantum information is not just … a quantum computer is not just a faster way of computing. It deals with information in a completely new way because of this interference phenomenon, because of entanglement that we’ve talked about. We have limited vision when it comes to predicting decades out what the impact will be of an entirely new way of doing things. Information processing, in particular. I mean you know this well. We go back to the 1960s, and people are starting to put a few transistors on a chip. Where is that going to lead? Nobody knew.
Craig Cannon [00:14:44] – Even early days of the internet.
John Preskill [00:14:45] – Yeah, good example.
Craig Cannon [00:14:46] – Even the first browser. No one really knew what anyone was going to do with it. It makes total sense.
John Preskill [00:14:52] – For good or ill. Yeah. But we have some ideas, you know? I think … why are we confident there will be some transformative effect on society? Of the things we know about, and I emphasize again, probably the most important ones are things we haven’t thought of when it comes to applications of quantum computing, the ones which will affect everyday life, I think, are better methods for understanding and inventing new materials, new chemical compounds. Things like that can be really important. If you find a better way of capturing carbon by designing a better catalyst, or you can design pharmaceuticals that have new effects, materials that have unusual properties. These are quantum physics problems because those properties of the molecule or the material really have to do with the underlying quantum behavior of the particles, and we don’t have a good way for solving such problems or predicting that behavior using ordinary digital computers. That’s what a quantum computer is good at. It’s good — but maybe not the only thing it’s good at — one thing it should certainly be good at is telling us quantitatively how quantum systems behave. In the two contexts I just mentioned, there’s little question that there will be practical impact of that.
Craig Cannon [00:16:37] – It’s not just doing the traveling salesman problem through the table of elements for why it can find these compounds.
John Preskill [00:16:49] – No. If it were, that wouldn’t be very efficient.
Craig Cannon [00:16:52] – Exactly.
John Preskill [00:16:53] – Yeah. No, it’s much trickier than that. Like I said, the exhaustive search, though conceptually it’s really interesting that quantum can speed it up because of interference, from a practical point of view it may not be that big a deal. It means that, well like I said, in the same amount of time you can solve an instance which is twice as big of the problem. What we really get excited about are the so-called exponential speed ups. That was why Shor’s algorithm was exciting in 1994, because factoring large numbers was a problem that had been studied by smart people for a long time, and on that basis, the fact that there weren’t any fast ways of solving it was pretty good evidence it’s a hard problem. Actually, we don’t know how to prove that from first principles. Maybe somebody will come along one day and figure out how to solve factoring very fast on a digital computer. It doesn’t seem very likely because people have been trying for so long to solve problems like that, and it’s just intractable with ordinary computers. You could say the same thing about these quantum physics problems. Maybe some brilliant graduate student is going to drop a paper on the arXiv tomorrow which will say, “Here, I solved quantum chemistry, and I can do it on a digital computer.” But we don’t think that’s very likely because we’ve been working pretty hard on these problems for decades and they seem to be really hard. Those cases, like these number theoretic problems,
John Preskill [00:18:40] – which have cryptological implications, and tasks for simulating the behavior of quantum systems, we’re pretty sure those are hard problems classically, and we’re pretty sure quantum computers … I mean we have algorithms that have been proposed, but which we can’t really run currently because our quantum computers aren’t big enough on the scale that’s needed to solve problems people really care about.
Craig Cannon [00:19:09] – Maybe we should jump to one of the questions from Twitter which is related to that. Travis Scholten (@Travis_Sch) asked, what are the most problem pressings in physics, let’s say specifically around quantum computers that you think substantial progress ought to be made in to move the field forward?
John Preskill [00:19:27] – I know Travis. He was an undergrad here. How you doing, Travis? The problems that we need to solve to make quantum computing closer to realization at the level that would solve problems people care about? Well, let’s go over where we are now.
Craig Cannon [00:19:50] – Yeah, definitely.
John Preskill [00:19:51] – People have been working on quantum hardware for 20 years, working hard, and there are a number of different approaches to building the hardware, and nobody really knows which is going to be the best. I think we’re far from collapsing to one approach which everybody agrees has the best long-term prospects for scalability. And so it’s important that a lot of different types of hardware are being pursued. We can come back to what some of the different approaches are later. Where are we now? We think in a couple of years we’ll have devices with about 50 qubits to 100, and we’ll be able to control them pretty well. That’s an interesting range because even though it’s only 50 to 100 qubits, doesn’t sound like that big a deal, but that’s already too many to simulate with a digital computer, even with the most powerful supercomputers today. From that point of view, these relatively small, near-term quantum computers which we’ll be fooling around with over the next five years or so, are doing something that’s kind of super-classical.
John Preskill [00:21:14] – At least, we don’t know how to do exactly the same things with ordinary computers. Now that doesn’t mean they’ll be able to do anything that’s practically important, but we’re going to try. We’re going to try, and there are ideas about things we’ll try out, including baby versions of these problems in chemistry, and materials, and ways of speeding up optimization problems. Nobody knows how well those things are going to work at these small scales. Part of the reason is not just the number of qubits is small, but they’re also not perfect. We can perform elementary operations on pairs of qubits, which we call quantum gates like the gates in ordinary logic. But they have an error rate a little bit below an error every 100 gates. If you have a circuit with 1000 qubits, that’s a lot of noise.
Craig Cannon [00:22:18] – Exactly. Does for instance, 100-qubit quantum computer really mean 100-qubit quantum computer or do you need a certain amount of backup going on?
John Preskill [00:22:29] – In the near term, we’re going to be trying out, and probably we have the best hopes for, kind of hybrid classical-quantum methods with some kind of classical feedback. You try to do something on the quantum computer, you make a measurement that gives you some information, then you change the way you did it a little bit, and try to converge on some better answer. That’s one possible way of addressing optimization that might be faster on a quantum computer. But I just wanted to emphasize that the number of qubits isn’t the only metric. How good they are, and in particular, the reliability of the gates, how well we can perform them … that’s equally important. Anyway, coming back to Travis’ question, there are lots of things that we’d like to be able to do better. But just having much better qubits would be huge, right? If you … more or less, with the technology we have now, you can have a gate error rate of a few parts in 1,000, you know? If you can improve that by orders of magnitude, then obviously, you could run bigger circuits. That would be very enabling.
John Preskill [00:23:58] – Even if you stick with 100 qubits just by having a circuit with more depth, more layers of gates, that increases the range of what you could do. That’s always going to be important. Because, I mean look at how crappy that is. A gate error rate, even if it’s one part in 1,000, that’s pretty lousy compared to if you look at where–
Craig Cannon [00:24:21] – Your phone has a billion transistors in it. Something like that, and 0%–
John Preskill [00:24:27] – You don’t worry about the … it’s gotten to the point where there is some error protection built in at the hardware level in a processor, because I mean, we’re doing these crazy things like going down from the 11 nanometer scale for features on a chip.
Craig Cannon [00:24:45] – How are folks trying to deal with interference right now?
John Preskill [00:24:50] – You mean, what types of devices? Yeah, so that’s interesting too because there are a range of different ways to do it. I mentioned that we could store information, we could make a qubit out of a single atom, for example. That’s one approach. You have to control a whole bunch of atoms and get them to interact with one another. One way of doing that is with what we call trapped ions. That means the atoms have electrical charges. That’s a good thing because then you could control them with electric fields. You could hold them in a trap, and you can isolate them, like I said, in a very high vacuum so they’re not interacting too much with other things in the laboratory, including stray electric and magnetic fields. But that’s not enough because you got to get them to talk to one another. You got to get them to interact. We have this set of desiderata, which are kind of in tension with one another. On the one hand, we want to isolate the qubits very well. On the other hand, we want to control them from the outside and get them to do what we want them to do, and eventually, we want to read them out. You have to be able to read out the result of the computation. But the key thing is the control. You could have two of those qubits in your device interact with one another in a specified way, and to do that very accurately you have to have some kind of bus that gets the two to talk to one another.
John Preskill [00:26:23] – The way they do that in an ion trap is pretty interesting. It’s by using lasers and controlling how the ions vibrate in the trap, and with a laser, kind of excite, wiggles of the ion, and then by determining whether the ions are wiggling or not, you can go address another ion, and that way you can do a two-qubit interaction. You can do that pretty well. Another way is really completely different. What I just described was encoding information at the one atom level. But another way is to use superconductivity — circuits in which electric current flows without any dissipation. In that case, you have a lot of freedom to sort of engineer the circuits to behave in a quantum way. There are many nuances there, but the key thing is that you can encode information now in a system that might involve the collective motion of billions of electrons, and yet you can control it as though it were a single atom. I mean, here’s one oversimplified way of thinking about it.
John Preskill [00:27:42] – Suppose you have a little loop of wire, and there’s current flowing in the loop. It’s a superconducting wire so it just keeps flowing. Normally, there’d be resistance, which would dissipate that as heat, but not for the superconducting circuit, which of course, has to be kept very cold so it stays superconducting. But you can imagine in this little loop that the current is either circulating clockwise or counterclockwise. That’s a way of encoding information. It could also be both at once, and that’s what makes it a qubit.
Craig Cannon [00:28:14] – Right.
John Preskill [00:28:15] – And so in that case, even though it involves lots of particles, the magic is that you can control that system extremely well. I mentioned individual electrons. That’s another approach. Put the qubit in the spin of a single electron.
Craig Cannon [00:28:32] – You also mentioned better qubits. What did you mean by that?
John Preskill [00:28:35] – Well, what I really care about is how well I can do the gates. There’s a whole other approach, which is motivated by the desire to have much, much better control over the quantum information than we do in those systems that I mentioned so far, superconducting circuits and trapped ions. That’s actually what Microsoft is pushing very hard. We call it topological quantum computing. Topological is a word physicists and mathematicians love. It means, well, we’ll come back to what it means. Anyway, let me just tell you what they’re trying to do. They’re trying to make a much, much better qubit, which they can control much, much better using a completely different hardware approach.
Craig Cannon [00:29:30] – Okay.
John Preskill [00:29:32] – It’s very ambitious because at this point, it’s not even clear they have a single qubit, but if that approach is successful, and it’s making progress, we will see a validated qubit of this type soon. Maybe next year. Nobody really knows where it goes from there, but suppose it’s the case that you could do a two-qubit gate with an error rate of one in a million instead of one in 1,000. That would be huge. Now, scaling all these technologies up, is really challenging from a number of perspectives, including just the control engineering.
Craig Cannon [00:30:17] – How are they doing it or attempting to do it?
John Preskill [00:30:21] – You know, you could ask, where did all this progress come from over 20 years, or so? For example, with the superconducting circuits, a sort of crucial measure is what we call the coherence time of the qubit, which roughly speaking, means how much it interacts with the outside world. The longer the coherence time, the better. The rate of what we call decoherence is essentially how much it’s getting buffeted around by outside influences. For the superconducting circuits, those coherence times have increased about a factor of 10 every three years, going back 15 years or so.
Craig Cannon [00:31:06] – Wow.
John Preskill [00:31:07] – Now, it won’t necessarily go on like that indefinitely, but in order to achieve that type of progress, better materials, better fabrication, better control. The way you control these things is with microwave circuitry. Not that different from the kind of things that are going on in communication devices. All those things are important, but going forward, the control is really the critical thing. Coherence times are already getting pretty long, I mean having them longer is certainly good. But the key thing is to get two qubits to interact just the way you want them to. Even if there is, now I keep saying the key thing is the environment, it’s not the only key thing, right? Because you have some qubit, like if you think about that electron spin, one way of saying it is I said it can be both up and down at the same time. Well, there’s a simpler way of saying that. It might not point either up or down. It might point some other way. But there really are a continuum of ways it could point. That’s not like a bit. See, it’s much easier to stabilize a bit because it’s got two states.
John Preskill [00:32:31] – But if it can kind of wander around in the space of possible configurations for a qubit, that makes it much harder to control. People have gotten better at that, a lot better at that in the last few years.
Craig Cannon [00:32:44] – Interesting. Joshua Harmon asked, what engineering strategy for quantum computers do you think has the most promise?
John Preskill [00:32:53] – Yeah, so I mentioned some of these different approaches, and I guess I’ll interpret the question as, which one is the winning horse? I know better than to answer that question! They’re all interesting. For the near term, the most advanced are superconducting circuits and trapped ions, which is why I mentioned those first. I think that will remain true over the next five to 10 years. Other technologies have the potential — like these topologically protected qubits — to surpass those, but it’s not going to happen real soon. I kind of like superconducting circuits because there’s so much phase space of things you can do with them. Of ways you can engineer and configure them, and imagine scaling them up.
John Preskill [00:33:54] – They have the advantage of being faster. The cycle time, time to do a gate, is faster than with the trapped ions. Just the basic physics of the interactions is different. In the long term, those electron spins could catapult ahead of these other things. That’s something that you can naturally do in silicon, and it’s potentially easy to integrate with silicon technology. Right now, the qubits and gates aren’t as good as the other technologies, but that can change. I mean, from a theorist’s perspective, this topological approach is very appealing. We can imagine it takes off maybe 10 years from now and it becomes the leader. I think it’s important to emphasize we don’t really know what’s going to scale the best.
Craig Cannon [00:34:50] – Right. And are there multiple attempts being made around programming quantum computers?
John Preskill [00:34:55] – Yeah. I mean, some of these companies– That are working on quantum technology now, which includes well-known big players like IBM, and Google, and Microsoft and Intel, but also a lot of startups now. They are trying to encompass the full stack, so they’re interested in the hardware, and the fabrication, and the control technology. But also, the software, the applications, the user interface. All those things are certainly going to be important eventually.
Craig Cannon [00:35:38] – Yeah, they’re pushing it almost to like an AWS layer. Where you interact with your quantum computer in a server farm and you don’t even touch it.
John Preskill [00:35:49] – That’s how it will be in the near term. You’re not going to have, most of us won’t, have a quantum computer sitting on your desktop, or in your pocket. Maybe someday. In the near term, it’ll be in the Cloud, and you’ll be able to run applications on it by some kind of web interface. Ideally, that should be designed so the user doesn’t have to know anything about quantum physics in order to program or use it, and I think that’s part of what some of these companies are moving toward.
Craig Cannon [00:36:24] – Do you think it will get to the level where it’s in your pocket? How do you deal with that when you’re below one kelvin?
John Preskill [00:36:32] – Well, if it’s in your pocket, it probably won’t be one kelvin.
Craig Cannon [00:36:35] – Yeah, probably not.
John Preskill [00:36:38] – What do you do? Well, there’s one approach, as an example, which I guess I mentioned in passing before, where maybe it doesn’t have to be at such low temperature, and that’s nuclear spins. Because they’re very weakly interacting with the outside world, you can have quantum information in a nuclear spin, which — I’m not saying that it would be undisturbed for years, but seconds, which is pretty good. And you can imagine that getting significantly longer. Someday you might have a little quantum smart card in your pocket. The nice thing about that particular technology is you could do it at room temperature. Still have long coherence times. If you go to the ATM and you’re worried that there’s a rogue bank that’s going to steal your information, one solution to that problem — I’m not saying there aren’t other solutions — is to have a quantum card where the bank will be able to authenticate it without being able to forge it.
Craig Cannon [00:37:54] – We should talk about the security element. Kevin Su asked what risk would quantum computers pose to current encryption schemes? So public key, and what changes should people be thinking about if quantum computers come in the next five years, 10 years?
John Preskill [00:38:12] – Yeah. Quantum computers threaten those systems that are in widespread use. Whenever you’re using a web browser and you see that little padlock and you’re at an HTTPS site, you’re using a public key cryptosystem to protect your privacy. Those cryptosystems rely for their security on the presumed hardness of computational problems. That is, it’s possible to crack them, but it’s just too hard. RSA, which is one of the ones that’s widely used … as typically practiced today, to break it you’d have to do something like factor a number which is over 2000 bits long, 2048. That’s too hard to do now. But that’s what quantum computers will be good at. Another one that’s widely used is called elliptic curve cryptography. Doesn’t really matter exactly what it is.
John Preskill [00:39:24] – But the point is that it’s also vulnerable to quantum attack, so we’re going to have to protect our privacy in different ways when quantum computers are prevalent.
Craig Cannon [00:39:37] – What are the attempts being made right now?
John Preskill [00:39:39] – There are two main classes of attempts. One is just to come up with a cryptographic protocol not so different conceptually from what’s done now, but based on a problem that’s hard for quantum computers.
Craig Cannon [00:39:59] – There you go.
John Preskill [00:40:02] – It turns out that what has sort of become the standard way doesn’t have that feature, and there are alternatives that people are working on. We speak of post-quantum cryptography, meaning the protocols that we’ll have to use when we’re worried that our adversaries have quantum computers. I don’t think there’s any proposed cryptosystem — although there’s a long list of them by now which people think are candidates for being quantum resistant, for being unbreakable, or hard to break by quantum computers. I don’t think there’s any one that the world has sufficient confidence in now that’s really hard for a quantum adversary that we’re all going to switch over. But it’s certainly time to be thinking about it. When people worry about their privacy, of course different users have different standards, but the US Government sometimes says they would like a system to stay secure for 50 years. They’d like to be able to use it for 20, roughly speaking, and then have the intercepted traffic be protected for another 30 after that. I don’t think, though I could be wrong, that we’re likely to have quantum computers that can break those public key cryptosystems in 10 years, but in 50 years seems not unlikely,
John Preskill [00:41:33] – and so we should really be worrying about it. The other one is actually using quantum communication for privacy. In other words, if you and I could send qubits to one another instead of bits, it opens up new possibilities. The way to think about these public key schemes — or one way — that we’re using now, is I want you to send me a private message, and I can send you a lockbox. It has a padlock on it, but I keep the key, okay? But you can close up the box and send it to me. But I’m the only one with the key. The key thing is that if you have the padlock you can’t reverse engineer the key. Of course, it’s a digital box and key, but that’s the idea of public key. The idea of what we call quantum key distribution, which is a particular type of quantum cryptography, is that I can actually send you the key, or you can send me your key, but why can’t any eavesdropper then listen in and know the key? Well it’s because it’s quantum, and remember, it has that property that if you look at it, you disturb it.
John Preskill [00:42:59] – So if you collect information about my key, or if the adversary does, that will cause some change in the key, and there are ways in which we can check whether what you received is really what I sent. And if it turns out it’s not, or it has too many errors in it, then we’ll be suspicious that there was an adversary who tampered with it, and then we won’t use that key. Because we haven’t used it yet — we’re just trying to establish the key. We do the test to see whether an adversary interfered. If it passes the test, then we can use the key. And if it fails the test, we throw that key away and we try again. That’s how quantum cryptography works, but it requires a much different infrastructure than what we’re using now. We have to be able to send qubits … well, it’s not completely different because you can do it with photons. Of course, that’s how we communicate through optical fiber now — we’re sending photons. It’s a little trickier sending quantum information through an optical fiber, because of that issue that interactions with the environment can disturb it. But nowadays, you can send quantum information through an optical fiber over tens of kilometers with a low enough error rate so it’s useful for communication.
Craig Cannon [00:44:22] – Wow.
John Preskill [00:44:23] – Of course, we’d like to be able to scale that up to global distances.
Craig Cannon [00:44:26] – Sure.
John Preskill [00:44:27] – And there are big challenges in that. But anyway, so that’s another approach to the future of privacy that people are interested in.
Craig Cannon [00:44:35] – Does that necessitate quantum computers on both ends?
John Preskill [00:44:38] – Yes, but not huge ones. The reason … well, yes and no. At the scale of tens of kilometers, no. You can do that now. There are prototype systems that are in existence. But if you really want to scale it up — in other words, to send things longer distance — then you have to bring this quantum error correction idea into the game.
John Preskill [00:45:10] – Because at least with our current photonics technology, there’s no way I can send a single photon from here to China without there being a very high probability that it gets lost in the fiber somewhere. We have to have what we call quantum repeaters, which can boost the signal. But it’s not like the usual type of repeater that we have in communication networks now. The usual type is you measure the signal, and then you resend it. That won’t work for quantum because as soon as you measure it you’re going to mess it up. You have to find a way of boosting it without knowing what it is. Of course, it’s important that it works that way because otherwise, the adversary could just intercept it and resend it. And so it will require some quantum processing to get that quantum error correction in the quantum repeater to work. But it’s a much more modest scale quantum processor than we would need to solve hard problems.
Craig Cannon [00:46:14] – Okay. Gotcha. What are the other things you’re both excited about, and worried about for potential business opportunities? Snehan, I’m mispronouncing names all the times, Snehan Kekre asks, budding entrepreneurs, what should they be thinking about in the context of quantum computing?
John Preskill [00:46:37] – There’s more to quantum technology than computing. Something which has good potential to have an impact in the relatively near future is improved sensing. Quantum systems, partly because of that property that I keep emphasizing that they can’t be perfectly isolated from the outside, they’re good at sensing things. Sometimes, you want to detect it when something in the outside world messes around with your qubit. Again, using this technology of nuclear spins, which I mentioned you can do at room temperature potentially, you can make a pretty good sensor, and it can potentially achieve higher sensitivity and spatial resolution, look at things on shorter distance scales than other existing sensing technology. One of the things people are excited about are the biological and medical implications of that.
John Preskill [00:47:53] – If you can monitor the behavior of molecular machines, probe biological systems at the molecular level using very powerful sensors, that would surely have a lot of applications. One interesting question you can ask is, can you use these quantum error correction ideas to make those sensors even more powerful? That’s another area of current basic research, where you could see significant potential economic impact.
Craig Cannon [00:48:29] – Interesting. In terms of your research right now, what are you working on that you find both interesting and incredibly difficult?
John Preskill [00:48:40] – Everything I work on–
Craig Cannon [00:48:41] – 100%.
John Preskill [00:48:42] – Is both interesting and incredibly difficult. Well, let me change direction a little from what we’ve been talking about so far. Well, I’m going to tell you a little bit about me.
Craig Cannon [00:48:58] – Sure.
John Preskill [00:49:00] – I didn’t start out interested in information in my career. I’m a physicist. I was trained as an elementary particle theorist, studying the fundamental interactions and the elementary particles. That drew me into an interest in gravitation because one thing that we still have a very poor understanding of is how gravity fits together with the other fundamental interactions. The way physicists usually say it is we don’t have a quantum theory of gravity, at least not one that we think is complete and satisfactory. I’ve been interested in that question for many decades, and then got sidetracked because I got excited about quantum computing. But you know what? I’ve always looked at quantum information not just as a technology. I’m a physicist, I’m not an engineer. I’m not trying to build a better computer, necessarily, though that’s very exciting, and worth doing, and if my work can contribute to that, that’s very pleasing. I see quantum information as a new frontier in the exploration of the physical sciences. Sometimes I call it the entanglement frontier. Physicists, we like to talk about frontiers, and stuff. Short distance frontier. That’s what we’re doing at CERN in the Large Hadron Collider, trying to discern new properties of matter at distances which are shorter than we’ve ever been able to explore before.
John Preskill [00:50:57] – There’s a long distance frontier in cosmology. We’re trying to look deeper into the universe and understand its structure and behavior at earlier times. Those are both very exciting frontiers. This entanglement frontier is increasingly going to be at the forefront of basic physics research in the 21st century. By entanglement frontier, I just mean scaling up quantum systems to larger and larger complexity where it becomes harder and harder to simulate those systems with our existing digital tools. That means we can’t very well anticipate the types of behavior that we’re going to see. That’s a great opportunity for new discovery, and that’s part of what’s going to be exciting even in the relatively near term. When we have 100 qubits … there are some things that we can do to understand the behavior of the dynamics of a highly complex system of 100 qubits that we’ve never been able to experimentally probe before. That’s going to be very interesting. But what we’re starting to see now is that these quantum information ideas are connecting to these fundamental questions about gravitation, and how to think about it quantumly. And it turns out, as is true for most of the broader implications of quantum physics, the key thing is entanglement.
John Preskill [00:52:36] – We can think of the microscopic structure of spacetime, the geometry of where we live. Geometry just means who’s close to who else. If we’re in the auditorium, and I’m in the first row and you’re in the fourth row, the geometry is how close we are to one another. Of course, that’s very fundamental in both space and time. How far apart are we in space? How far apart are we in time? Is geometry really a fundamental thing, or is it something that’s kind of emergent from some even more fundamental concept? It seems increasingly likely that it’s really an emergent property.
John Preskill [00:53:29] – That there’s something deeper than geometry. What is it? We think it’s quantum entanglement. That you can think of the geometry as arising from quantum correlations among parts of a system. That’s really what defines who’s close to who. We’re trying to explore that idea more deeply, and one of the things that comes in is the idea of quantum error correction. Remember the whole idea of quantum error correction was that we could make a quantum system behave the way we want it to because it’s well-protected against the damaging effects of noise. It seems like quantum error correction is part of the deep secret of how spacetime geometry works. It has a kind of intrinsic robustness coming from these ideas of quantum error correction that makes space meaningful, so that it doesn’t just evaporate when you tap on it. If you wanted to, you could think of the spacetime, the space that you’re in and the space that I’m in, as parts of a system that are entangled with one another.
John Preskill [00:54:45] – What would happen if we broke that entanglement and your part of space became disentangled from my part? Well what we think that would mean is that there’d be no way to connect us anymore. There wouldn’t be any path through space that starts over here with me and ends with you. It’d become broken apart into two pieces. It’s really the entanglement which holds space together, which keeps it from falling apart into little pieces. We’re trying to get a deeper grasp of what that means.
Craig Cannon [00:55:19] – How do you make any progress on that? That seems like the most unbelievably difficult problem to work on.
John Preskill [00:55:26] – It’s difficult because, well for a number of reasons, but in particular, because it’s hard to get guidance from experiment, which is how physics historically–
Craig Cannon [00:55:38] – All science.
John Preskill [00:55:38] – Has advanced.
Craig Cannon [00:55:39] – Yeah.
John Preskill [00:55:41] – Although it was fun a moment ago to talk about what would happen if we disentangled your part of space from mine, I don’t know how to do that in the lab right now. Of course, part of the reason is we have the audacity to think we can figure these things out just by thinking about them. Maybe that’s not true. Nobody knows, right? We should try. Solving these problems is a great challenge, and it may be that the apes that evolved on Earth don’t have the capacity to understand things like the quantum structure of spacetime. But maybe we do, so we should try. Now in the longer term, and maybe not such a long term, maybe we can get some guidance from experiment. In particular, what we’re going to be doing with quantum computers and the other quantum technologies that are becoming increasingly sophisticated in the next couple of decades, is we’ll be able to control very well highly entangled complex quantum systems. That should mean that in a laboratory, on a tabletop, I can sort of make my own little toy space time …
John Preskill [00:57:02] – with an emergent geometry arising from the properties of that entanglement, and I think that’ll teach us lessons because systems like that are the types of system that, because they’re so highly entangled, digital computers can’t simulate them. It seems like only quantum computers are potentially up to the task. So that won’t be quite the same as disentangling your side of the room from mine, in real life. But we’d be able to do it in a laboratory setting using model systems, which I think would help us to understand the basic principles better.
Craig Cannon [00:57:39] – Wild. Yeah, desktop space time seems pretty cool, if you could figure it out.
John Preskill [00:57:43] – Yeah, it’s pretty fundamental. We didn’t really talk about what people sometimes, we did implicitly, but not in so many words. We didn’t talk about what people sometimes call quantum non-locality. It’s another way of describing quantum entanglement, actually. There’s this notion of Bell’s theorem that when you look at the correlations among the parts of a quantum system, that they’re different from any possible classical correlations. Some things that you read give you the impression that you can use that to instantaneously send information over long distances. It is true that if we have two qubits, electron spins, say, and they’re entangled with one another, then what’s kind of remarkable is that I can measure my qubit to see along some axis whether it’s up or down, and you can measure yours, and we will get perfectly correlated results. When I see up, you’ll see up, say, and when I see down, you’ll see down. And sometimes, people make it sound like that’s remarkable. That’s not remarkable in itself. Somebody could’ve flipped a pair of coins, you know,
John Preskill [00:59:17] – so that they came up both heads or both tails, and given one to you and one –
Craig Cannon [00:59:20] – Split them apart.
John Preskill [00:59:20] – to me.
Craig Cannon [00:59:21] – Yeah.
John Preskill [00:59:22] – And gone a light year apart, and then we both … hey, mine’s heads. Mine’s heads too!
Craig Cannon [00:59:24] – And then they call it quantum teleportation on YouTube.
John Preskill [00:59:28] – Yeah. Of course, what’s really important about entanglement that makes it different from just those coins is that there’s more than one way of looking at a qubit. We have what we call complementary ways of measuring it, so you can ask whether it’s up or down along this axis or along that axis. There’s nothing like that for the coins. There’s just one way to look at it. What’s cool about entanglement is that we’ll get perfectly correlated results if we both measure in the same way, but there’s more than one possible way that we could measure. What sometimes gets said, or the impression people get, is that that means that when I do something to my qubit, it instantaneously affects your qubit, even if we’re on different sides of the galaxy. But that’s not what entanglement does. It just means they’re correlated in a certain way.
John Preskill [01:00:30] – When you look at yours, if we have maximally entangled qubits, you just see a random bit. It could be a zero or a one, each occurring with probability 1/2. That’s going to be true no matter what I did to my qubit, and so you can’t tell what I did by just looking at it. It’s only that if we compared notes later we can see how they’re correlated, and that correlation holds for either one of these two complementary ways in which we could both measure. It’s that fact that we have these complementary ways to measure that makes it impossible for a classical system to reproduce those same correlations. So that’s one misconception that’s pretty widespread. Another one is this about quantum computing, which is in trying to explain why quantum computers are powerful, people will sometimes say, well, it’s because you can superpose –I used that word before, you can add together many different possibilities. That means that, whereas an ordinary computer would just do a computation once, acting on a superposition a quantum computer can do a vast number of computations all at once.
John Preskill [01:01:54] – There’s a certain sense in which that’s mathematically true if you interpret it right, but it’s very misleading. Because in the end, you’re going to have to make some measurement to read out the result. When you read it out, there’s a limited amount of information you can get. You’re not going to be able to read out the results of some huge number of computations in a single shot measurement. Really the key thing that makes it work is this idea of interference, which we discussed briefly when you asked about Grover’s algorithm. The art of a quantum algorithm is to make sure that the wrong answers interfere and cancel one another out, so the right answer is enhanced. That’s not automatic. It requires that the quantum algorithm be designed in just the right way.
Craig Cannon [01:02:50] – Right. The diagrams I’ve seen online at least, involve usually you’re squaring the output as it goes along, and then essentially, that flips the correct answer to the positive, and the others are in the negative position. Is that accurate?
John Preskill [01:03:08] – I wouldn’t have said it the way you did– Because you can’t really measure it as you go along. Once you measure it, the magic of superposition is going to be lost.
John Preskill [01:03:19] – It means that now there’s some definite outcome or state. To take advantage of this interference phenomenon, you need to delay the measurement. Remember when we were talking about the double slit and I said, if you actually see these wiggles in the probability of detection, which is the signal of interference, that means that there’s no way anybody could know whether the electron went through hole one or hole two? It’s the same way with quantum computing. If you think of the computation as being a superposition of different possible computations, it wouldn’t work — there wouldn’t be a speed up — if you could know which of those paths the computation followed. It’s important that you don’t know. And so you have to sum up all the different computations, and that’s how the interference phenomenon comes into play.
Craig Cannon [01:04:17] – To take a little sidetrack, you mentioned Feynman before. And before we started recording you mentioned working with him. I know I’m in the Feynman fan club, for sure. What was that experience like?
John Preskill [01:04:32] – We never really collaborated. I mean, we didn’t write a paper together, or anything like that. We overlapped for five years at Caltech. I arrived here in 1983. He died in 1988. We had offices on the same corridor, and we talked pretty often because we were both interested in the fundamental interactions, and in particular, what we call quantum chromodynamics. It’s our theory of how nuclear matter behaves, how quarks interact, what holds the proton together, those kinds of things. One big question is what does hold the proton together? Why don’t the quarks just fall apart? That was an example of a problem that both he and I were very interested in, and which we talked about sometimes. Now, this was pretty late in his career. When I think about it now, when I arrived at Caltech, that was 1983, Feynman was born in 1918, so he was 65. I’m 64 now, so maybe he wasn’t so old, right? But at the time, he seemed pretty ancient to me. Since I was 30.
John Preskill [01:05:58] – Those who interacted with Dick Feynman when he was really at his intellectual peak in the ’40s, and ’50s, and ’60s, probably saw even more extraordinary intellectual feats than I witnessed interacting with the 65 year old Feynman. He just loved physics, you know? He just thought everything was so much fun. He loved talking about it. He wasn’t as good a listener as a talker, but actually – well that’s a little unfair, isn’t it? It was kind of funny because Feynman, he always wanted to think things through for himself, sort of from first principles, rather than rely on the guidance from experts who have thought about these things before. Well that’s fine. You should try to understand things as deeply as you can on your own, and sort of reconstruct the knowledge from the ground up. That’s very enabling, and gives you new insights. But he was a little too dismissive, in my view, of what the other guys knew. But I could slip it in because I didn’t tell him, “Dick, you should read this paper by Polyakov” — well maybe I did, but he wouldn’t have even heard that — because he solved that problem that you’re talking about.
John Preskill [01:07:39] – But I knew what Polyakov had said about it, so I would say, “Oh well, look, why don’t we look at it this way?” And so he thought I was, that I was having all these insights, but the truth was the big difference between Feynman and me in the mid 1980s was I was reading literature, and he wasn’t.
Craig Cannon [01:08:00] – That’s funny.
John Preskill [01:08:01] – Probably, if he had been, he would’ve been well served, but that wasn’t the way he liked to work on things. He wanted to find his own approach. Of course, that had worked out pretty well for him throughout his career.
Craig Cannon [01:08:15] – What other qualities did you notice about him when he was roaming the corridors?
John Preskill [01:08:21] – He’d always be drumming. So you would know he was around because he’d actually be walking down the hallway drumming on the wall.
Craig Cannon [01:08:27] – Wait, with his hands, or with sticks, or–
John Preskill [01:08:29] – No, hands. He’d just be tapping.
Craig Cannon [01:08:32] – Just a bongo thing.
John Preskill [01:08:33] – Yeah. That was one thing. He loved to tell stories. You’ve probably read the books that Ralph Leighton put together based on the stories Feynman told. Ralph did an amazing job, of capturing Feynman’s personality in writing those stories down because I’d heard a lot of them. I’m sure he told the same stories to many people many times, because he loved telling stories. But the book really captures his voice pretty well.
John Preskill [01:09:12] – If you had heard him tell some of these stories, and then you read the way Ralph Leighton transcribed them, you can hear Feynman talking. At the time that I knew him, one of the experiences that he went through was he was on the Challenger commission after the space shuttle blew up. He was in Washington a lot of the time, but he’d come back from time to time, and he would sort of sit back and relax in our seminar room and start bringing us up to date on all the weird things that were happening on the Challenger commission. That was pretty fun.
Craig Cannon [01:09:56] – That’s really cool.
John Preskill [01:09:56] – A lot of that got captured in the second volume. I guess it’s the one called, What Do You Care What Other People Think? There’s a chapter about him telling stories about the Challenger commission. He was interested in everything. It wasn’t just physics. He was very interested in biology. He was interested in computation. I remember how excited he was when he got his first IBM PC. Probably not long after I got to Caltech. Yeah, it was what they called the AT. We thought it was a pretty sexy machine. I had one, too. He couldn’t wait to start programming it in BASIC.
Craig Cannon [01:10:50] – Very cool.
John Preskill [01:10:51] – Because that was so much fun.
Craig Cannon [01:10:52] – There was a question that I was kind of curious to your answer. Tika asks about essentially, teaching about quantum computers. They say, many kids in grade 10 can code. Some can play with machine learning tools without knowing the math. Can quantum computing become as simple and/or accessible?
John Preskill [01:11:17] – Maybe so. At some level, when people say quantum mechanics is counterintuitive, it’s hard for us to grasp, it’s so foreign to our experience, that’s true. The way things behave at the microscopic scale are, like we discussed earlier, really different from the way ordinary stuff behaves. But it’s a question of familiarity. What I wouldn’t be surprised by is that if you go out a few decades, kids who are 10 years old are going to be playing quantum games. That’s an application area that doesn’t get discussed very much, but there could be a real market there because people love games. Quantum games are different, and the strategies are different, and what you have to do to win is different. If you play the game enough, you start to get the hang of it.
John Preskill [01:12:26] – I don’t see any reason why kids who have not necessarily deeply studied physics can’t get a pretty good feel for how quantum mechanics works. You know, the way ordinary physics works, maybe it’s not so intuitive. Newton’s laws … Aristotle couldn’t get it right. He thought you had to keep pushing on something to get it to keep moving. That wasn’t right. Galileo was able to roll balls down a ramp, and things like that, and see he didn’t have to keep pushing to keep it moving. He could see that it was uniformly accelerated in a gravitational field. Newton took that to a much more general and powerful level. You fool around with stuff, and you get the hang of it. And I think quantum stuff can be like that. We’ll experience it in a different way, but when we have quantum computers, in a way, that opens the opportunity for trying things out and seeing what happens.
John Preskill [01:13:50] – After you’ve played the game enough, you start to anticipate. And actually, it’s an important point about the applications. One of the questions you asked me at the beginning was what are we able to do with quantum computers? And I said, I don’t know. So how are we going to discover new applications? It might just be, at least in part, by fooling around. A lot of classical algorithms that people use on today’s computers were discovered, or that they were powerful was discovered, by experimenting. By trying it. I don’t know … what’s an example of that? Well, the simplex method that we use in linear programming. I don’t think there was a mathematical proof that it was fast at first, but people did experiments, and they said, hey, this is pretty fast.
Craig Cannon [01:14:53] – Well, you’re seeing it a lot now in machine learning.
John Preskill [01:14:57] – Yeah, well that’s a good example.
Craig Cannon [01:14:58] – You test it out a million times over when you’re running simulations, and it turns out, that’s what works. Following the thread of education, and maybe your political interest, given it’s the year that it is, do you have thoughts on how you would adjust or change STEM education?
John Preskill [01:15:23] – Well, no particularly original thoughts. But I do think that STEM education … we shouldn’t think of it as we’re going to need this technical workforce, and so we better train them. The key thing is we want the general population to be able to reason effectively, and to recognize when an argument is phony and when it’s authentic. To think about, well how can I check whether what I just read on Facebook is really true? And I see that as part of the goal of STEM education. When you’re teaching kids in school how to understand the world by doing experiments, by looking at the evidence, by reasoning from the evidence, this is something that we apply in everyday life, too. I don’t know exactly how to implement this–
John Preskill [01:16:36] – But I think we should have that perspective that we’re trying to educate a public, which is going to eventually make critical decisions about our democracy, and they should understand how to tell when something is true or not. That’s a hard thing to do in general, but you know what I mean. That there are some things that, if you’re a person with some — I mean it doesn’t necessarily have to be technical — but if you’re used to evaluating evidence and making a judgment based on that evidence about whether it’s a good argument or not, you can apply that to all the things you hear and read, and make better judgments.
Craig Cannon [01:17:23] – What about on the policy side? Let’s see, JJ Francis asked that, if you or any of your colleagues would ever consider running for office. Curious about science policy in the US.
John Preskill [01:17:38] – Well, it would be good if we had more scientifically trained people in government. Very few members of Congress. I know of one, Bill Foster’s a physicist in Illinois. He was a particle physicist, and he worked at Fermilab, and now he’s in Congress, and very interested in the science and educational policy aspects of government. Rush Holt was a congressman from New Jersey who had a background in physics. He retired from the House a couple of years ago, but he was in Congress for something like 18 years, and he had a positive influence, because he had a voice that people respected when it came to science policy. Having more people like that would help. Now, another thing, it doesn’t have to be elective office.
Craig Cannon [01:18:39] – Right.
John Preskill [01:18:42] – There are a lot of technically trained people in government, many of them making their careers in agencies that deal with technical issues. Department of Defense, of course, there are a lot of technical issues. In the Obama Administration we had two successive secretaries of energy who were very, very good physicists. Steve Chu was Nobel Prize winning physicist. Then Ernie Moniz, who’s a real authority on nuclear energy and weapons. That kind of expertise makes a difference in government.
John Preskill [01:19:24] – Now the Secretary of Energy is Rick Perry. It’s a different background.
Craig Cannon [01:19:28] – Yeah, you could say that. Just kind of historical reference, what policies did they put in place that you really felt their hand as a physicist move forward?
John Preskill [01:19:44] – You mean in particular–
Craig Cannon [01:19:45] – I’m talking the Obama Administration.
John Preskill [01:19:49] – Well, I think the Department of Energy, DOE, tried to facilitate technical innovation by seeding new technologies, by supporting startup companies that were trying to do things that would improve battery technology, and solar power, and things like that, which could benefit future generations. They had an impact by doing that. You don’t have to be a Nobel Prize winning physicist to think that’s a good idea. That the administration felt that was a priority made a difference, and appointing a physicist at Department of Energy was, if nothing else, highly symbolic of how important those things are.
Craig Cannon [01:20:52] – On the quantum side, someone asked Vikas Karad, he asked where the Quantum Valley might be. Do you have thoughts, as in Silicon Valley for quantum computing?
John Preskill [01:21:06] – Well… I don’t know, but you look at what’s happening the last couple of years, there have been a number of quantum startups. A notable number of them are in the Bay Area. Why so? Well, that’s where the tech industry is concentrated and where the people who are interested in financing innovative technical startups are concentrated. If you are an entrepreneur interested in starting a company, and you’re concerned about how to fundraise for it, it kind of makes sense to locate in that area. Now, that’s what’s sort of happening now, and may not continue, of course. It might not be like that indefinitely. Nothing lasts forever, but I would say… That’s the place, Silicon Valley is likely to be Quantum Valley, the way things are right now.
Craig Cannon [01:22:10] – Well then what about the physicists who might be listening to this? If they’re thinking about starting a company, do you have advice for them?
John Preskill [01:22:22] – Just speaking very generally, if you’re putting a team together… Different people have different expertise. Take quantum computing as an example, like we were saying earlier, some of the big players and the startups, they want to do everything. They want to build the hardware, figure out better ways to fabricate it. Better control, better software, better applications. Nobody can be an expert on all those things. Of course, you’ll hire a software person to write your software, and microwave engineer to figure out your control, and of course that’s the right thing to do. But I think in that arena, and it probably applies to other entrepreneurial activity relating to physics, being able to communicate across those boundaries is very valuable, and you can see it in quantum computing now. That if the man or woman who’s involved in the software has that background, but there’s not a big communication barrier talking to the people who are doing the control engineering, that can be very helpful. It makes sense to give some preference to the people who maybe are comfortable doing so, or have the background that stretches across more than one of those areas of expertise. That can be very enabling in a technology arena like quantum computing today, where we’re trying to do really, really hard stuff, and you don’t know whether you’ll succeed, and you want to give it your best go by seeing the connections between those different things.
Craig Cannon [01:24:28] – Would you advise someone then to maybe teach or try and explain it to, I don’t know their young cousins? Because Feynman maybe recognizes the king of communicating physics, at least for a certain period of time. How would you advise someone to get better at it so they can be more effective?
John Preskill [01:24:50] – Practice. There are different aspects of that. This isn’t what you meant at all, but I’ll say it anyway, because what you asked brought it to mind. If you teach, you learn. We have this odd model in the research university that a professor like me is supposed to do research and teach. Why don’t we hire teachers and researchers? Why do we have the same people doing both? Well, part of the reason for me is most of what I know, what I’ve learned since my own school education ended, is knowledge I acquired by trying to teach it. To keep our intellect rejuvenated, we have to have that experience of trying to teach new things that we didn’t know that well before to other people. That deepens your knowledge. Just thinking about how you convey it makes you ask questions that you might not think to ask otherwise, and you say “Hey, I don’t know the answer to that.” Then you have to try to figure it out. So I think that applies at varying levels to any situation in which a scientist, or somebody with a technical background, is trying to communicate.
John Preskill [01:26:21] – By thinking about how to get it across to other people, we can get new insights, you know? We can look at it in a different way. It’s not a waste of time. Aside from the benefits of actually successfully communicating, we benefit from it in this other way. But other than that… Have fun with it, you know? Don’t look at it as a burden, or some kind of task you have to do along with all the other things you’re doing. It should be a pleasure. When it’s successful, it’s very gratifying. If you put a lot of thought into how to communicate something and you think people are getting it, that’s one of the ways that somebody in my line of work can get a lot of satisfaction.
Craig Cannon [01:27:23] – If now were to be your opportunity to teach a lot of people about physics, and you could just point someone to things, who would you advise someone to be? They want to learn more about quantum computing, they want to learn about physics. What should they be reading? What YouTube channel should they follow? What should they pay attention to?
John Preskill [01:27:44] – Well one communicator who I have great admiration for is Leonard Susskind, who’s at Stanford. You mentioned Feynman as the great communicator, and that’s fair, but in terms of style and personality of physicists who are currently active, I think Lenny Susskind is the most similar to Feynman of anyone I can think of. He’s a no bullshit kind of guy. He wants to give you the straight stuff. He doesn’t want to water it down for you. But he’s very gifted when it comes to making analogies and creating the illusion that you’re understanding what he’s saying. He has … if you just go to YouTube and search Leonard Susskind you’ll see lectures that he’s given at Stanford where they have some kind of extension school for people who are not Stanford students, people in the community. A lot of them in the tech community because it’s Stanford, and he’s giving courses. Yeah, and on quite sophisticated topics, but also on more basic topics, and he’s in the process of turning those into books. I’m not sure how many of those have appeared, but he has a series called The Theoretical Minimum
John Preskill [01:29:19] – which is supposed to be the gentle introduction to different topics like classical physics, quantum physics, and so on. He’s pretty special I think in his ability to do that.
Craig Cannon [01:29:32] – I need to subscribe. Actually, here’s a question then. In the things you’ve relearned while teaching over the past, I guess it’s 35 years now.
John Preskill [01:29:46] – Shit, is that right?
Craig Cannon [01:29:47] – Something like that.
John Preskill [01:29:48] – That’s true. Yeah.
Craig Cannon [01:29:51] – What were the big thing, what were the revelations?
John Preskill [01:29:55] – That’s how I learned quantum computing, for one thing. I was not at all knowledgeable about information science. That wasn’t my training. Back when I was in school, physicists didn’t learn much about things like information theory, computer science, complexity theory. One of the great things about quantum computing is its interdisciplinary character, that it brings these different things into contact, which traditionally had not been part of the common curriculum of any community of scholars. I decided 20 years ago that I should teach a quantum information class at Caltech, and I worked very hard on it that year. Not that I’m an expert, or anything, but I learned a lot about information theory, and things like channel capacity, and computational complexity — how we classify the hardness of problems — and algorithms. Things like that, which I didn’t really know very well. I had sort of a passing familiarity with some of those things from reading some of the quantum computing literature. That’s no substitute for teaching a class because then you really have to synthesize it and figure out your way of presenting it. Most of the notes are typed up and you can still get to them on my website.That was pretty transformative for me … and it was easier then, 20 years ago, I guess than it is now because it was such a new topic.
John Preskill [01:31:49] – But I really felt I was kind of close enough to the cutting edge on most of those topics by the time I’d finished the class that I wasn’t intimidated by another paper I’d read or a new thing I’d hear about those things. That was probably the one case where it really made a difference in my foundation of knowledge which enabled me to do things. But I had the same experience in particle physics. When I was a student, I read a lot. I was very broadly interested in physics. But when the first time, I was still at Harvard at the time –later I taught a similar course here — I’m in my late 20s, I’m just a year or two out of graduate school, and I decide to teach a very comprehensive class on elementary particles … in particular, quantum chromodynamics, the theory of nuclear forces like we talked about before. It just really expanded my knowledge to have that experience of teaching that class. I still draw on that. I can still remember that experience and I think I get ideas that I might not otherwise have because I went through that.
Craig Cannon [01:33:23] – I want to get involved now. I want to go back to school, or maybe teach a class. I don’t know.
John Preskill [01:33:27] – Well, what’s stopping you?
Quantum mechanics is weird! Imagine for a second that you want to make an experiment and that the result of your experiment depends on what your colleague is doing in the next room. It would be crazy to live in such a world! This is the world we live in, at least at the quantum scale. The result of an experiment cannot be described in a way that is independent of the context. The neighbor is sticking his nose in our experiment!
Before telling you why quantum mechanics is contextual, let me give you an experiment that admits a simple non-contextual explanation. This story takes place in Flatland, a two-dimensional world inhabited by polygons. Our protagonist is a square who became famous after claiming that he met a sphere.
This square, call him Mr Square for convenience, met a sphere, Miss Sphere. When you live in a planar world like Flatland, this kind of event is not only rare, but it is also quite weird! For people of Flatland, only the intersection of Miss Sphere’s body with the plane is visible. Depending on the position of the sphere, its shape in Flatland will either be a point, a circle, or it could even be empty.
During their trip to flatland, Professor Farnsworth explains to Bender: “If we were in the third dimension looking down, we would be able to see an unhatched chick in it. Just as a chick in a 3-dimensional egg could be seen by an observer in the fourth dimension.’
Not convinced by Miss Sphere’s arguments, Mr Square tried to prove that she cannot exist – Square was a mathematician – and failed miserably. Let’s imagine a more realistic story, a story where spheres cannot speak. In this story, Mr Square will be a physicist, familiar with hidden variable models. Mr Square met a sphere, but a tongue-tied sphere! Confronted with this mysterious event, he did what any other citizen of Flatland would have done. He took a selfie with Miss Sphere. Mr Square was kind enough to let us use some of his photos to illustrate our story.
Picture taken by Mr Square, with his Flatland-camera. (a) The sphere. (b) Selfie of Square (left) with the sphere (right).
As you can see on these photos, when you are stuck in Flatland and you take a picture of a sphere, only a segment is visible. What aroused Mr Square’s curiosity is the fact that the length of this segment changes constantly. Each picture shows a segment of a different length, due to the movement of the sphere along the z-axis, invisible to him. However, although they look random, Square discovered that these changing lengths can be explained without randomness by introducing a hidden variable living in a hypothetical third dimension. The apparent randomness is simply a consequence of his incomplete knowledge of the system: The position along the hidden variable axis z is inaccessible! Of course, this is only a model, this third dimension is purely theoretical, and no one from Flatland will ever visit it.
What about quantum mechanics?
Measurement outcomes are random as well in the quantum realm. Can we explain the randomness in quantum measurements by a hidden variable? Surprisingly, the answer is no! Von Neumann, one of the greatest scientists of the 20th century, was the first one to make this claim in 1932. His attempt to prove this result is known today as “Von Neumann’s silly mistake”. It was not until 1966 that Bell convinced the community that Von Neumann’s argument relies on a silly assumption.
Consider first a system of a single quantum bit, or qubit. A qubit is a 2-level system. It can be either in a ground state or in an excited state, but also in a quantum superposition of these two states, where and are complex numbers such that . We can see this quantum state as a 2-dimensional vector , where the ground state is and the excited state is .
The probability of an outcome depends on the projection of the quantum state onto the ground state and the excited state.
What can we measure about this qubit? First, imagine that we want to know if our quantum state is in the ground state or in the excited state. There is a quantum measurement that returns a random outcome, which is with probability and with probability .
Let us try to reinterpret this measurement in a different way. Inspired by Mr Square’s idea, we extend our description of the state of the system to include the outcome as an extra parameter. In this model, a state is a pair of the form where is either or . Our quantum state can be seen as being in position with probability or in position with probability . Measuring only reveals the value of the hidden variable . By introducing a hidden variable, we made this measurement deterministic. This proves that the randomness can be moved to the level of the description of the state, just as in Flatland. The weirdness of quantum mechanics goes away.
Contextuality of quantum mechanics
Let us try to extend our hidden variable model to all quantum measurements. We can associate a measurement with a particular kind of matrix , called an observable. Measuring an observable returns randomly one of its eigenvalue. For instance, the Pauli matrices
as well as and the identity matrix , are 1-qubit observables with eigenvalues (i.e. measurement outcomes) . Now, take a system of 2 qubits. Since each of the 2 qubits can be either excited or not, our quantum state is a 4-dimensional vector
Therein, the 4 vectors can be identified with the vectors of the canonical basis and . We will consider the measurement of 2-qubit observables of the form defined by . In other words, acts on the first qubit and acts on the second one. Later, we will look into the observables , , , and their products.
What happens when two observables are measured simultaneously? In quantum mechanics, we can measure simultaneously multiple observables if these observables commute with each other. In that case, measuring then , or measuring first and then , doesn’t make any difference. Therefore, we say that these observables are measured simultaneously, the outcome being a pair , composed of an eigenvalue of and an eigenvalue of . Their product , which commutes with both and , can also be measured in the same time. Measuring this triple returns a triple of eigenvalues corresponding respectively to , and . The relation imposes the constraint
(1)
on the outcomes.
Assume that one can describe the result of all quantum measurements with a model such that, for all observables and for all states of the model, a deterministic outcome exists. Here, is our ‘extended’, not necessarily physical, description of the state of the system. When and are commuting, it is reasonable to assume that the relation (1) holds also at the level of the hidden variable model, namely
(2)
Such a model is called a non-contextual hidden variable model. Von Neumann proved that no such value exists by considering these relations for all pairs , of observables. This shows that quantum mechanics is contextual! Hum… Wait a minute. It seems silly to impose such a constraint for all pairs of observable, including those that cannot be measured simultaneously. This is “Von Neumann’s silly assumption’. Only pairs of commuting observables should be considered.
Peres-Mermin proof of contextuality
One can resurrect Von Neumann’s argument, assuming Eq.(2) only for commuting observables. Peres-Mermin’s square provides an elegant proof of this result. Form a array with these observables. It is constructed in such a way that
(i) The eigenvalues of all the observables in Peres-Mermin’s square are ±1,
(ii) Each row and each column is a triple of commuting observables,
(iii) The last element of each row and each column is the product of the 2 first observables, except in the last column where .
If a non-contextual hidden variable exists, it associates fixed eigenvalues , , , (which are either 1 or -1) with the 4 observables , , , . Applying Eq.(2) to the first 2 rows and to the first 2 columns, one deduces the values of all the observables of the square, except . Finally, what value should be attributed to ? By (iii), applying Eq.(2) to the last row, one gets . However, using the last column, (iii) and Eq.(2) yield the opposite value . This is the expected contradiction, proving that there is no non-contextual value . Quantum mechanics is contextual!
We saw that the randomness in quantum measurements cannot be explained in a ‘classical’ way. Besides its fundamental importance, this result also influences quantum technologies. What I really care about is how to construct a quantum computer, or more generally, I would like to understand what kind of quantum device could be superior to its classical counterpart for certain tasks. Such a quantum advantage can only be reached by exploiting the weirdness of quantum mechanics, such as contextuality 1,2,3,4,5. Understanding these weird phenomena is one of the first tasks to accomplish.
Morning sunlight illuminated John Preskill’s lecture notes about Caltech’s quantum-computation course, Ph 219. I’m TAing (the teaching assistant for) Ph 219. I previewed lecture material one sun-kissed Sunday.
Pasadena sunlight spilled through my window. So did the howling of a dog that’s deepened my appreciation for Billy Collins’s poem “Another reason why I don’t keep a gun in the house.” My desk space warmed up, and I unbuttoned my jacket. I underlined a phrase, braided my hair so my neck could cool, and flipped a page.
I flipped back. The phrase concerned a mathematical statement called the Yang-Baxter relation. A sunbeam had winked on in my mind: The Yang-Baxter relation described my hair.
The Yang-Baxter relation belongs to a branch of math called topology. Topology resembles geometry in its focus on shapes. Topologists study spheres, doughnuts, knots, and braids.
Topology describes some quantum physics. Scientists are harnessing this physics to build quantum computers. Alexei Kitaev largely dreamed up the harness. Alexei, a Caltech professor, is teaching Ph 219 this spring.1 His computational scheme works like this.
We can encode information in radio signals, in letters printed on a page, in the pursing of one’s lips as one passes a howling dog’s owner, and in quantum particles. Imagine three particles on a tabletop.
Consider pushing the particles around like peas on a dinner plate. You could push peas 1 and 2 until they swapped places. The swap represents a computation, in Alexei’s scheme.2
The diagram below shows how the peas move. Imagine slicing the figure into horizontal strips. Each strip would show one instant in time. Letting time run amounts to following the diagram from bottom to top.
Humor me with one more swap, an interchange of 2 and 3.
Congratulations! You’ve modeled a significant quantum computation. You’ve also braided particles.
The author models a quantum computation.
Let’s recap: You began with peas 1, 2, and 3. You swapped 1 with 2, then 1 with 3, and then 2 with 3. The peas end up ordered oppositely the way they began—end up ordered as 3, 2, 1.
You could, instead, morph 1-2-3 into 3-2-1 via a different sequence of swaps. That sequence, or braid, appears below.
Congratulations! You’ve begun proving the Yang-Baxter relation. You’ve shown that each braid turns 1-2-3 into 3-2-1.
The relation states also that 1-2-3 is topologically equivalent to 3-2-1: Imagine standing atop pea 2 during the 1-2-3 braiding. You’d see peas 1 and 3 circle around you counterclockwise. You’d see the same circling if you stood atop pea 2 during the 3-2-1 braiding.
That Sunday morning, I looked at John’s swap diagrams. I looked at the hair draped over my left shoulder. I looked at John’s swap diagrams.
“Yang-Baxter relation” might sound, to nonspecialists, like a mouthful of tweed. It might sound like a sneeze in a musty library. But an eight-year-old could grasp half the relation. When I braid my hair, I pass my left hand over the back of my neck. Then, I pass my right hand over. But I could have passed the right hand first, then the left. The braid would have ended the same way. The braidings would look identical to a beetle hiding atop what had begun as the middle hunk of hair.
The Yang-Baxter relation.
I tried to keep reading John’s lecture notes, but the analogy mushroomed. Imagine spinning one pea atop the table.
A 360° rotation returns the pea to its initial orientation. You can’t distinguish the pea’s final state from its first. But a quantum particle’s state can change during a 360° rotation. Physicists illustrate such rotations with corkscrews.
Like the corkscrews formed as I twirled my hair around a finger. I hadn’t realized that I was fidgeting till I found John’s analysis.
I gave up on his lecture notes as the analogy sprouted legs.
I’ve never mastered the fishtail braid. What computation might it represent? What about the French braid? You begin French-braiding by selecting a clump of hair. You add strands to the clump while braiding. The addition brings to mind particles created (and annihilated) during a topological quantum computation.
Ancient Greek statues wear elaborate hairstyles, replete with braids and twists. Could you decode a Greek hairdo? Might it represent the first 18 digits in pi? How long an algorithm could you run on Rapunzel’s hair?
Call me one bobby pin short of a bun. But shouldn’t a scientist find inspiration in every fiber of nature? The sunlight spilling through a window illuminates no less than the hair spilling over a shoulder. What grows on a quantum physicist’s head informs what grows in it.
1Alexei and John trade off on teaching Ph 219. Alexei recommends the notes that John wrote while teaching in previous years.
2When your mother ordered you to quit playing with your food, you could have objected, “I’m modeling computations!”
Have you ever wanted to be incredibly perceptive and make far-reaching deductions about people? I have always been fascinated by spy stories, and how the main character in them notices tiny details of his surroundings to navigate life-or-death situations. This skill seems out of reach for us normal people; you have to be “a high-functioning sociopath” to memorize all existing data on behavior, clothes choices and forensic science. Of course I’m referring to:
Yet in the not too distant future, a computer may help you become a brilliant detective (or a scheming villain) yourself! The first step is noticing the details, which is known in machine learning as the classification task. Here is a pioneering work that somewhat resembles the above picture, only it’s done by a computer:
The task for the computer here was to produce a verbal description of the image. There are thousands of words in the vocabulary, and a computer has to try them in different combinations to make a sensible sentence. There is no way a computer can be given an exhaustive list of correct sentences with examples of images for each. That kind of list would be a database bigger than the earth (as one can see just by counting the number of combinations). So to train the computer to use language like in a picture above, one only possesses a limited set of examples – maybe a few thousand pictures with descriptions. Yet we as humans are capable of learning from just seeing a few examples, by noticing the repeating patterns. So the computer can do the same! The score next to each word above is an estimate based on those few thousand examples of how relevant is the word “tennis” or “woman” to what’s in the box on the image. The algorithm produces possible sentences, scores them, and then selects the sentence with the highest total score.
Once the classification task is done, one needs to use all the collected information to make a prediction – as Sherlock is able to point out the most probable motive in the first picture, we also want to predict a piece of very personal information: we’d like to know how to start up a conversation with that tennis player.
Humans are actually good at classification tasks: with luck, we can notice and type in our cellphone all the details the predictor will need, like brand of clothing, hair color, height… though computers recently became better than humans at facial expression recognition, so we don’t have to trust ourselves on that anymore. Finally, when all the data is collected, most humans will still say only generic advice to you on conversation starters. Which means we are very bad at prediction tasks. We don’t notice the hidden dependencies between brand of clothes and sense of humor. But such information may not hide from the all-seeing eye of the machine learning algorithm! So expect your cellphones to give you dating advice within 10 years…
Now how do quantum computers come into play? Well if you look at your search results, they are still pretty irrelevant most of the time. Imagine you used them as conversation starters – you’ll embarrass yourself 9 out of 10 times! To make this better, a certain company needs more memory and processing power. Yet most advanced deep learning routines remain out of reach, just because there are exponentially many hidden dependencies one would need to try and reject before the algorithm finds the right predictor. So a certain company turns to us, quantum computing people, as we deal with exponentially hard problems notoriously well! And indeed, quantum algorithms make some of the machine learning routines exponentially faster – see this Quantum Machine Learning article, as well as a talk by Seth Lloyd for technical details. Some anonymous stock trader is already trying to intimidate their fellow quants (quantitative analysts) by calling the top trading system “Quantum machine learning”. I think we should appreciate his sense of humor and invest into his algorithm as soon as Quantiacs.com opens such functionality. Or we could invest in Teagan from Caltech – her code recently won the futures contest on the same website.


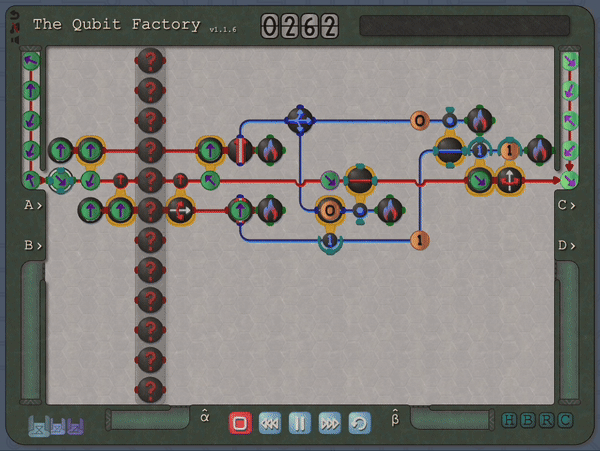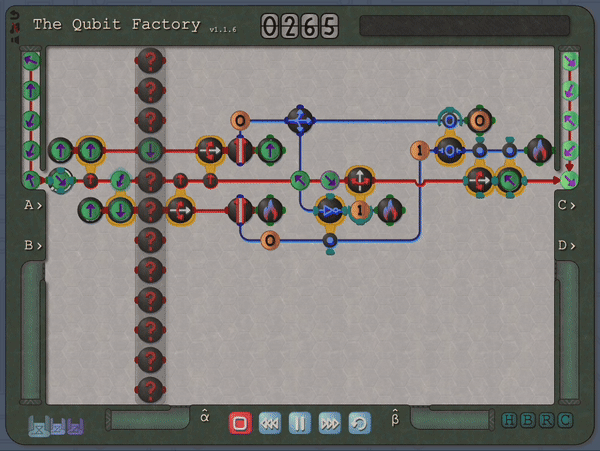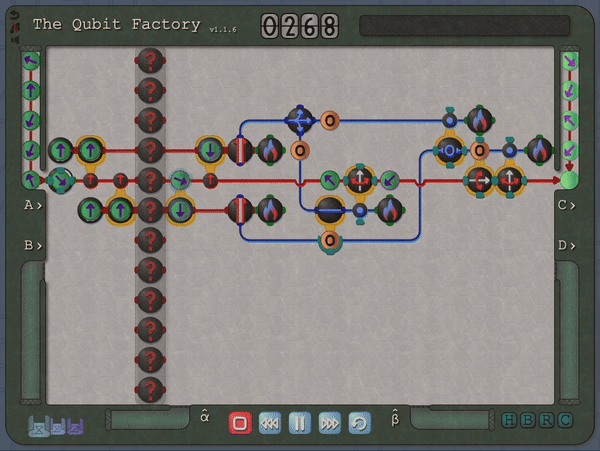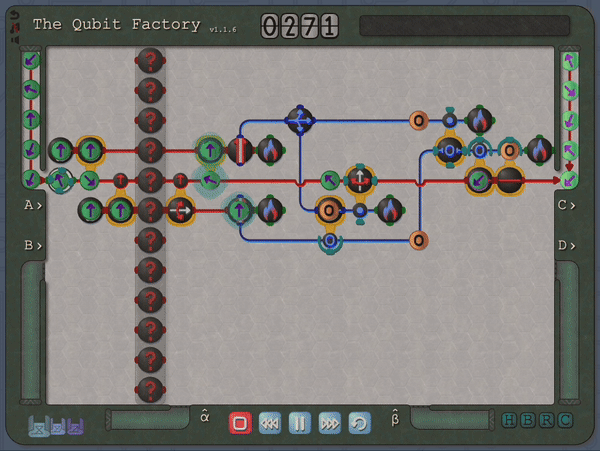



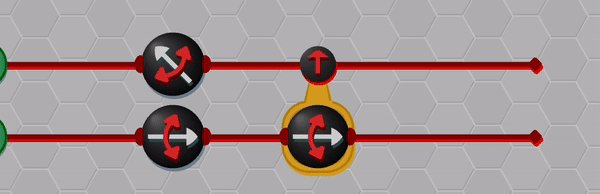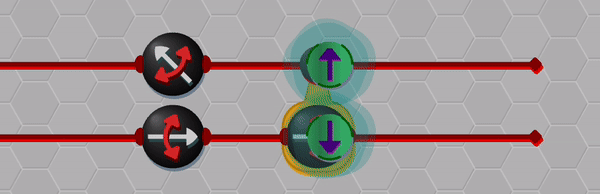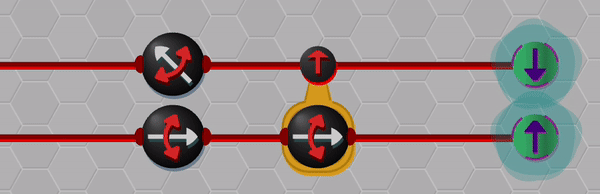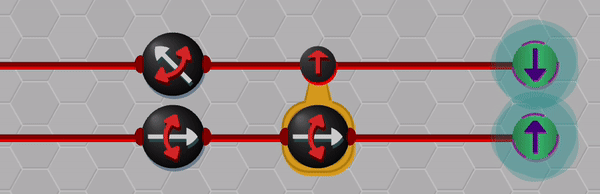

 together with the knowledge that quantum gates are unitary, so the Hermitian conjugate of each gate doubles as its inverse. But what if you didn’t know quantum mechanics, or even linear algebra? Could this problem be solved through logical reasoning alone? This is where I think that the visuals really help; players should be able to infer several key points from geometry alone:
together with the knowledge that quantum gates are unitary, so the Hermitian conjugate of each gate doubles as its inverse. But what if you didn’t know quantum mechanics, or even linear algebra? Could this problem be solved through logical reasoning alone? This is where I think that the visuals really help; players should be able to infer several key points from geometry alone:
 , guaranteed to be either the
, guaranteed to be either the  or
or  eigenstate, and tasks the player to determine which state they have been given. Those familiar with quantum computing will recognize this as a relatively simple problem in state tomography. There are many viable strategies that could be employed to solve this task (and I am not even sure of the optimal one myself). However, by circumventing the need for a mathematical calculation, the Qubit Factory allows players to easily and quickly explore different approaches. Hopefully this could allow players to find effective strategies through trial-and-error, gaining some understanding of state tomography (and why it is challenging) in the process.
eigenstate, and tasks the player to determine which state they have been given. Those familiar with quantum computing will recognize this as a relatively simple problem in state tomography. There are many viable strategies that could be employed to solve this task (and I am not even sure of the optimal one myself). However, by circumventing the need for a mathematical calculation, the Qubit Factory allows players to easily and quickly explore different approaches. Hopefully this could allow players to find effective strategies through trial-and-error, gaining some understanding of state tomography (and why it is challenging) in the process.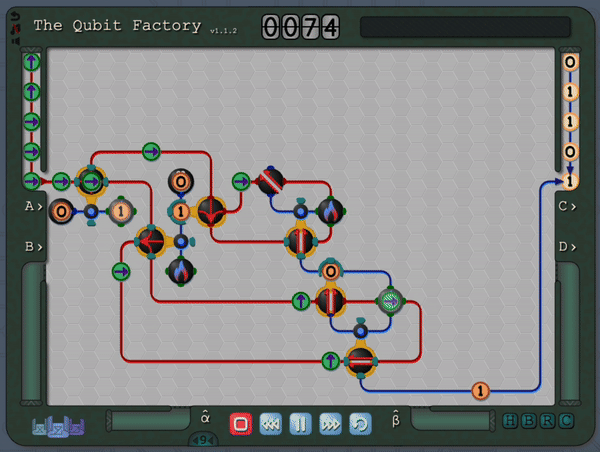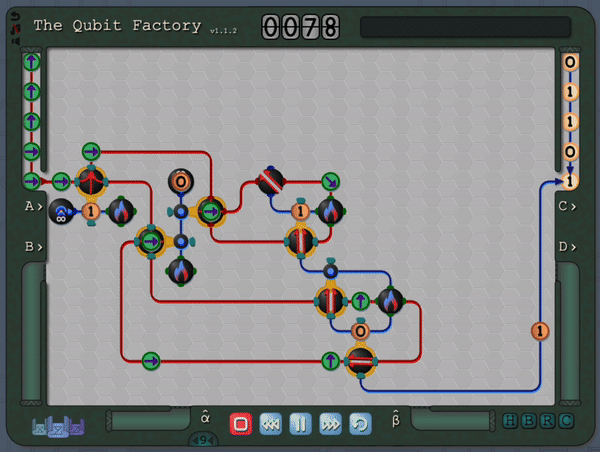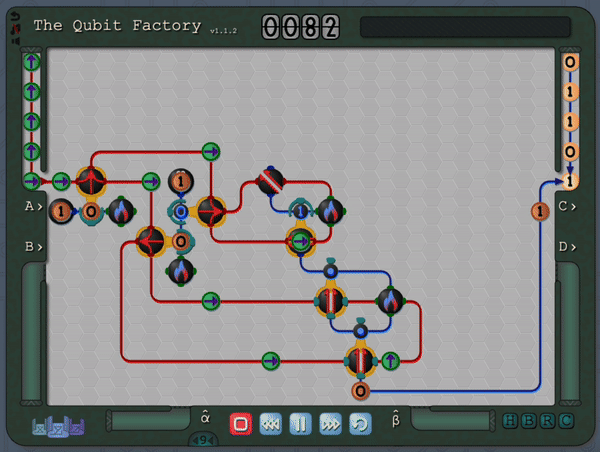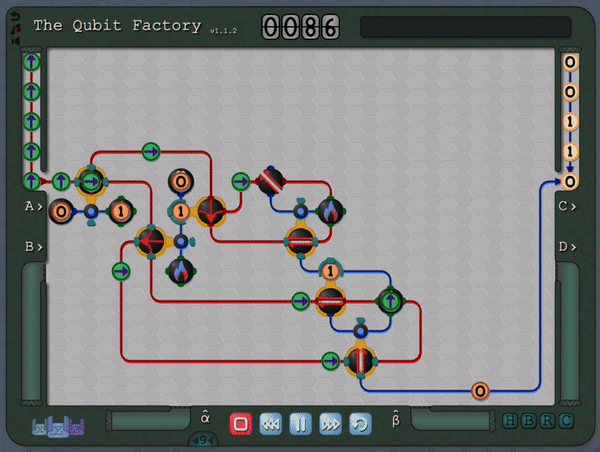



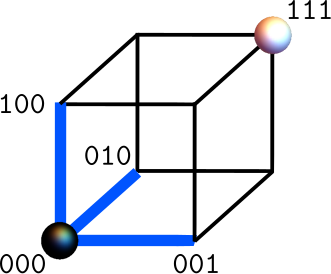
 possible states are represented by the eight corners of the cube below. Let’s encode the logical bit as “0” —> 000 and “1” —> 111, corresponding to the corners of the cube marked by the black and white ball, respectively. For our (local) noise model, we assume that flips of only one of the three physical bits are more likely to occur than flips of two or three at the same time.
possible states are represented by the eight corners of the cube below. Let’s encode the logical bit as “0” —> 000 and “1” —> 111, corresponding to the corners of the cube marked by the black and white ball, respectively. For our (local) noise model, we assume that flips of only one of the three physical bits are more likely to occur than flips of two or three at the same time. that are closer to 000 than to 111 is called a Voronoi tile.
that are closer to 000 than to 111 is called a Voronoi tile.
 on the surface of a sphere. Now let us encode a classical bit using the north and south poles of this sphere (represented in the picture below as a black and a white ball, respectively). The north pole of the sphere corresponds to the molecule being parallel to the z-axis, while the south pole corresponds to the molecule being anti-parallel.
on the surface of a sphere. Now let us encode a classical bit using the north and south poles of this sphere (represented in the picture below as a black and a white ball, respectively). The north pole of the sphere corresponds to the molecule being parallel to the z-axis, while the south pole corresponds to the molecule being anti-parallel.
 in “0” and
in “0” and  . We didn’t have to worry about such sign errors before, because our classical information would always be the definite state of “0” or “1”. Now, there are two effects of noise to worry about, so our task has become twice as hard!
. We didn’t have to worry about such sign errors before, because our classical information would always be the definite state of “0” or “1”. Now, there are two effects of noise to worry about, so our task has become twice as hard!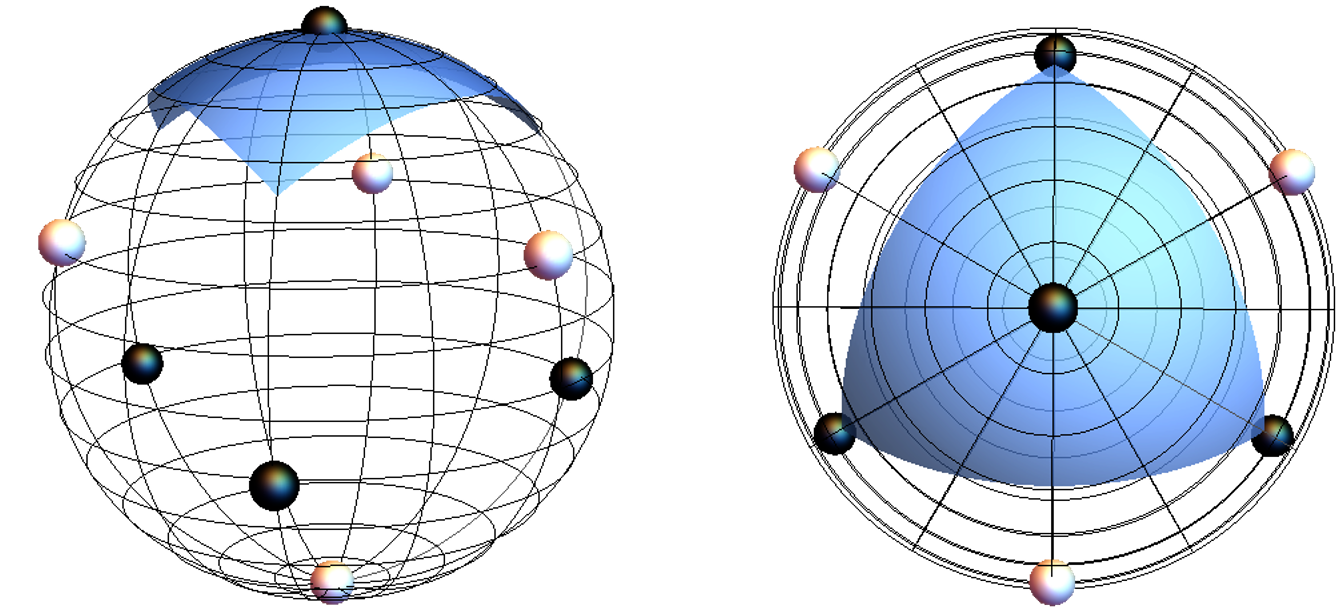

 : each orientation of an asymmetric molecule is labeled by the 3D rotation necessary to obtain said orientation from a reference state. Such rotations, and in turn the orientations themselves, are parameterized by an axis
: each orientation of an asymmetric molecule is labeled by the 3D rotation necessary to obtain said orientation from a reference state. Such rotations, and in turn the orientations themselves, are parameterized by an axis  (by which one rotates). The rotation group
(by which one rotates). The rotation group  with opposite points identified. The direction of each vector
with opposite points identified. The direction of each vector  lying inside the ball corresponds to the axis of rotation, while the length corresponds to the angle. This may take some time to digest, but it’s not crucial to the story.
lying inside the ball corresponds to the axis of rotation, while the length corresponds to the angle. This may take some time to digest, but it’s not crucial to the story.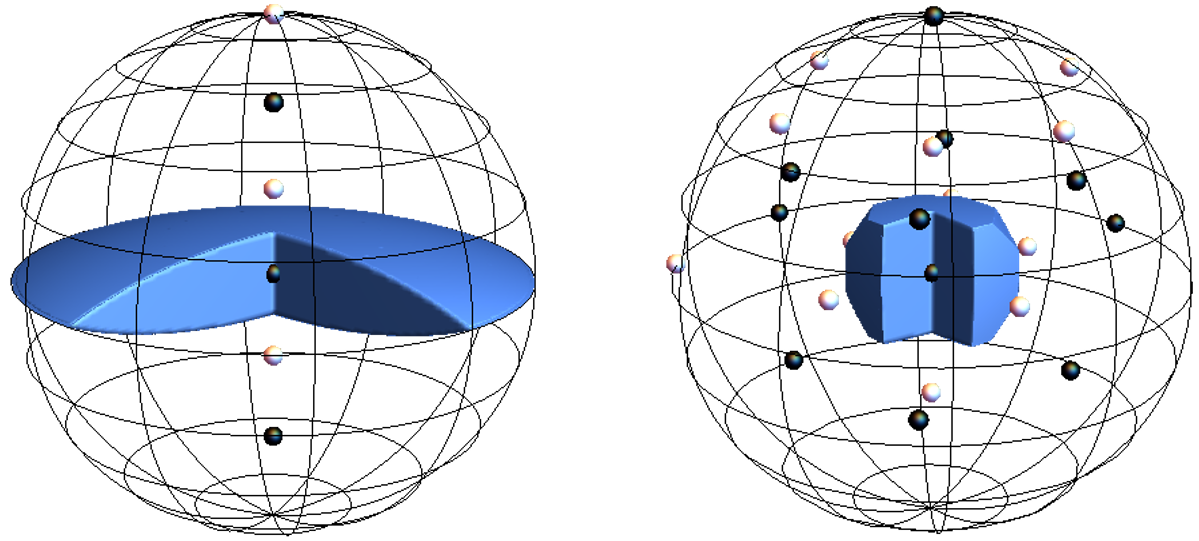

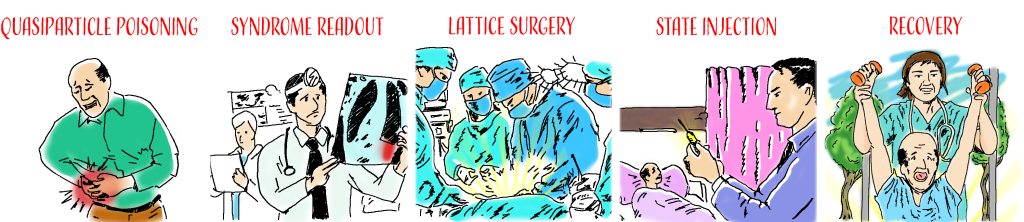
 different amplitudes (instead of just
different amplitudes (instead of just 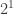 for the case of a single qubit). We are once again plagued by noise coming from the environment. But what if we now, less ambitiously, want to store only one qubit’s worth of information in this 50-qubit system? Now there is room to play with! A clever choice of how to do this (a.k.a. the encoding) helps protect from the bad environment.
for the case of a single qubit). We are once again plagued by noise coming from the environment. But what if we now, less ambitiously, want to store only one qubit’s worth of information in this 50-qubit system? Now there is room to play with! A clever choice of how to do this (a.k.a. the encoding) helps protect from the bad environment. 

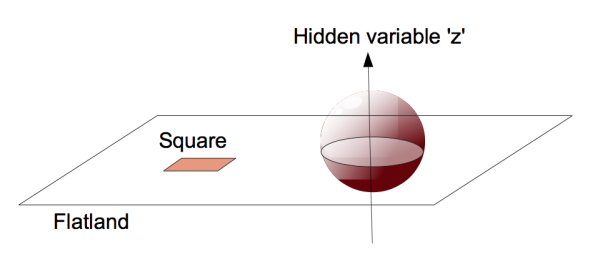

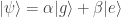 of these two states, where
of these two states, where  and
and  are complex numbers such that
are complex numbers such that  . We can see this quantum state as a 2-dimensional vector
. We can see this quantum state as a 2-dimensional vector  , where the ground state is
, where the ground state is  and the excited state is
and the excited state is  .
.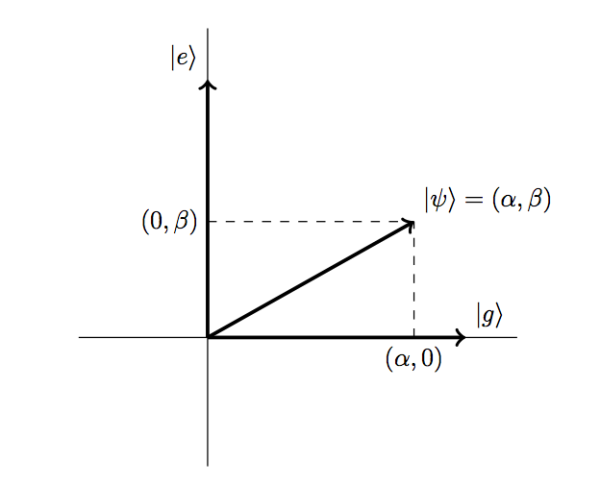
 with probability
with probability  and
and  with probability
with probability  .
. of the system to include the outcome as an extra parameter. In this model, a state is a pair of the form
of the system to include the outcome as an extra parameter. In this model, a state is a pair of the form 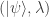 where
where  is either
is either 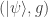 with probability
with probability  or in position
or in position 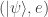 with probability
with probability 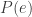 . Measuring only reveals the value of the hidden variable
. Measuring only reveals the value of the hidden variable  , called an observable. Measuring an observable returns randomly one of its eigenvalue. For instance, the Pauli matrices
, called an observable. Measuring an observable returns randomly one of its eigenvalue. For instance, the Pauli matrices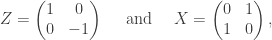
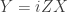 and the identity matrix
and the identity matrix  , are 1-qubit observables with eigenvalues (i.e. measurement outcomes)
, are 1-qubit observables with eigenvalues (i.e. measurement outcomes)  . Now, take a system of 2 qubits. Since each of the 2 qubits can be either excited or not, our quantum state is a 4-dimensional vector
. Now, take a system of 2 qubits. Since each of the 2 qubits can be either excited or not, our quantum state is a 4-dimensional vector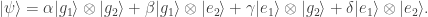
 can be identified with the vectors of the canonical basis
can be identified with the vectors of the canonical basis  and
and 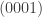 . We will consider the measurement of 2-qubit observables of the form
. We will consider the measurement of 2-qubit observables of the form 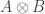 defined by
defined by 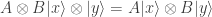 . In other words,
. In other words,  acts on the second one. Later, we will look into the observables
acts on the second one. Later, we will look into the observables  ,
,  ,
, 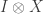 ,
,  and their products.
and their products. then
then  , or measuring
, or measuring  , composed of an eigenvalue of
, composed of an eigenvalue of  , which commutes with both
, which commutes with both  corresponding respectively to
corresponding respectively to  . The relation
. The relation 
 of the model, a deterministic outcome
of the model, a deterministic outcome  exists. Here,
exists. Here, 
 exists by considering these relations for all pairs
exists by considering these relations for all pairs 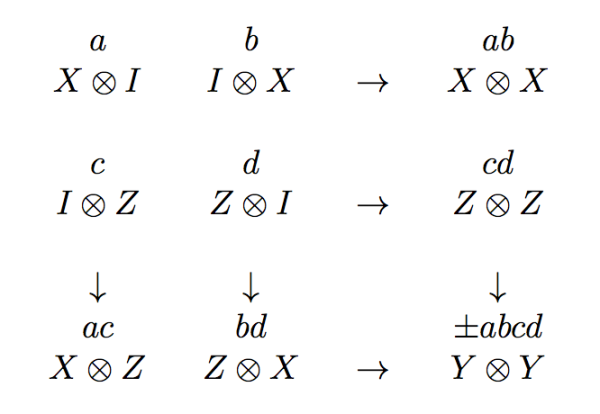
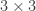 array with these observables. It is constructed in such a way that
array with these observables. It is constructed in such a way that .
. ,
,  ,
,  ,
,  (which are either 1 or -1) with the 4 observables
(which are either 1 or -1) with the 4 observables  . Finally, what value should be attributed to
. Finally, what value should be attributed to  . However, using the last column, (iii) and Eq.(2) yield the opposite value
. However, using the last column, (iii) and Eq.(2) yield the opposite value  . This is the expected contradiction, proving that there is no non-contextual value
. This is the expected contradiction, proving that there is no non-contextual value 
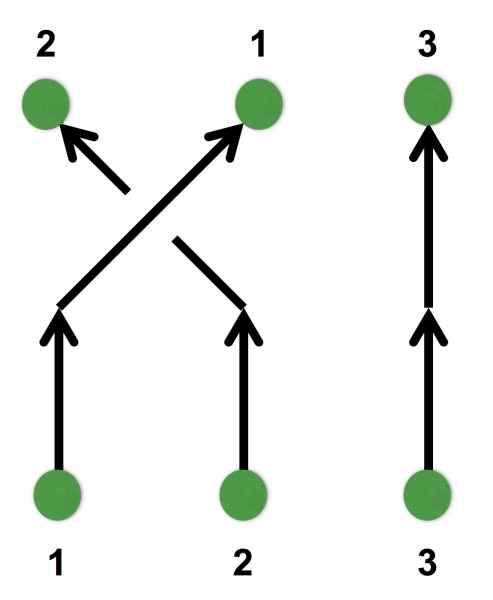
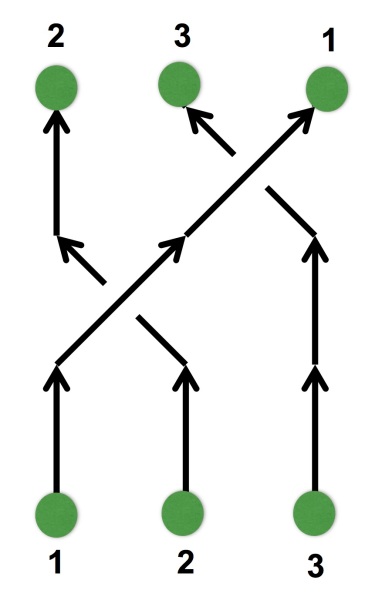








{kind=link}
{kind=link}