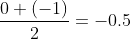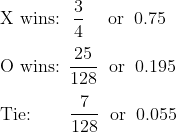When my brother and I were little, we sometimes played video games on weekend mornings, before our parents woke up. We owned a 3DO console, which ran the game Gex. Gex is named after its main character, a gecko. Stepping into Gex’s shoes—or toe pads—a player can clamber up walls and across ceilings.
I learned this month how geckos clamber, at the 125th Statistical Mechanics Conference at Rutgers University. (For those unfamiliar with the field: statistical mechanics is a sibling of thermodynamics, the study of energy.) Joel Lebowitz, a legendary mathematical physicist and nonagenarian, has organized the conference for decades. This iteration included a talk by Kanupriya (Kanu) Sinha, an assistant professor at the University of Arizona.
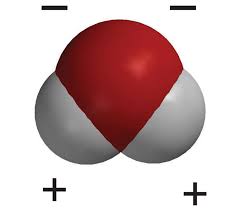
Kanu studies open quantum systems, or quantum systems that interact with environments. She often studies a particle that can be polarized. Such a particle carries an electric charge, which can be distributed unevenly across the particle. Examples include a water molecule. As encoded in its chemical symbol, H2O, a water molecule consists of two hydrogen atoms and one oxygen atom. The oxygen attracts the molecule’s electrons more strongly than the hydrogen atoms do. So the molecule’s oxygen end carries a negative charge, and the hydrogen ends carry positive charges.1
The red area represents the oxygen, and the gray areas represent the hydrogen atoms. Image from the American Chemical Society.
When certain quantum particles are polarized, we can control their positions using lasers. After all, a laser consists of light—an electromagnetic field—and electric fields influence electrically charged particles’ movements. This control enables optical tweezers—laser beams that can place certain polarizable atoms wherever an experimentalist wishes. Such atoms can form a quantum computer, as John Preskill wrote in a blog post on Quantum Frontiers earlier this month.
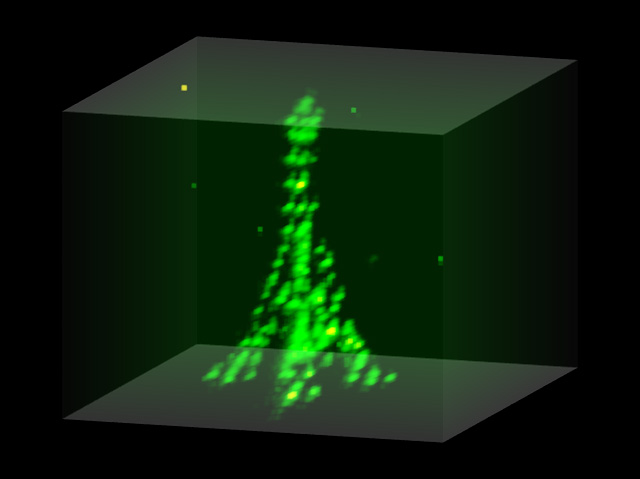
Instead of placing polarizable atoms in an array that will perform a quantum computation, you can place the atoms in an outline of the Eiffel Tower. Image from Antoine Browaeys’s lab.
A tweezered atom’s environment consists not only of a laser, but also everything else around, including dust particles. Undesirable interactions with the environment deplete an atom of its quantum properties. Quantum information stored in the atom leaks into the environment, threatening a quantum computer’s integrity. Hence the need for researchers such as Kanu, who study open quantum systems.
Kanu illustrated the importance of polarizable particles in environments, in her talk, through geckos. A gecko’s toe pads contain tiny hairs that polarize temporarily. The electric charges therein can be attracted to electric charges in a wall. We call this attraction the van der Waals force. So Gex can clamber around for a reason related to why certain atoms suit quantum computing.
Kanu explaining how geckos stick.
Winter break offers prime opportunities for kicking back with one’s siblings. Even if you don’t play Gex (and I doubt whether you do), behind your game of choice may lie more physics than expected.
1Water molecules are polarized permanently, whereas Kanu studies particles that polarize temporarily.
Note: Oliver Zheng is a senior at University High School, Irvine CA. He has been working on AI players for quantum versions of Tic Tac Toe under the supervision of Dr. Spiros Michalakis.
Several years ago, while scrolling through YouTube, I came across a video of Paul Rudd playing something called “Quantum Chess.” I had no idea what it was, nor did I know that it would become one of the most gloriously nerdy rabbit holes I would ever fall into (see: 5D Chess with Multiverse Time Travel).
Over time, I tried to teach myself how to play these multi-layered, multi-dimensional games, but progress was slow. However, while taking a break during a piano lesson last year, I mentioned to my teacher my growing interest in unnecessarily stressful versions of chess. She told me that she happened to be friends with Dr. Xie Chen, professor of theoretical physics at Caltech who was sponsoring a Quantum Gaming project. I immediately jumped at the opportunity to connect with her, and within days was able to have my first online meeting with Dr. Chen. Soon after, I got invited to join the project. Following my introduction to the team, I started reading “Quantum Computation and Quantum Information”, which helped me understand how the theory behind the games worked. When I felt ready, Dr. Chen referred me to Dr. Spiros Michalakis at Caltech, who, funnily enough, was the creator of the quantum chess video.
I would’ve never imagined that I am two degrees of separation from Paul Rudd, but nonetheless, I wanted to share some of the work I’ve been doing with Spiros on Quantum TiqTaqToe.
What is Quantum TiqTaqToe?
Evert van Nieuwenburg, the creator of Quantum TiqTaqToe whom I also collaborated with, goes in depth about how the game works here, but I will give a short rundown. The general idea is that there is now a split move, where you can put an ‘X’ in two different squares at once — a Schrödinger’s X, if you will. When the board has no more empty squares, the X randomly ‘collapses’ into one of the two squares with equal probability. The game ends when there are three real X’s or three real O’s in a row, just as in regular tic-tac-toe. Depending on the mode you are playing, you might also be able to entangle your X’s with your opponent’s O’s. You can get a better sense of all this by actually playing the game here.
My goal was to find out who wins when both players play optimally. For instance, in normal tic-tac-toe, it is well-known that the first X should go in the middle of the board, and if player O counters successfully, the game should end in a tie. Is the outcome of Quantum TiqTaqToe, too, predetermined to end in a tie if both players play optimally? And, if not, what is the best first move for player X? I sought to answer these questions through the power of computation.
The First Attempt
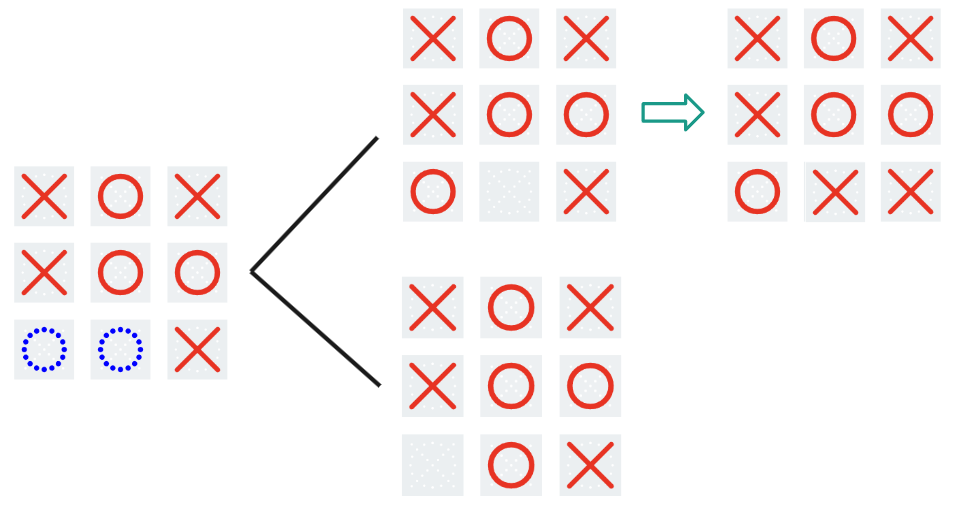
In the following section, I refer to a ‘game state’ as any unique arrangement of X’s and O’s on a board. The ‘empty game state’ simply means an empty board. ‘Traversing’ through a certain game state means that, at some point in the game, that game state occurs. So, for example, every game traverses through the empty game state, since every game starts with an empty board.
In order to solve the unsolved, one must first solve the solved. As such, my first attempt was to create an algorithm that would figure out the best move to play in regular tic-tac-toe. This first attempt was rather straightforward, and I will explain it here:
Essentially, I developed a model using what is known as “reinforcement learning” to determine the best next move given a certain game state. Here is how it works: To track which set of moves are best for player X and player O, respectively, every game state is assigned a value, initially 0. When a game ends, these values are updated to reflect who won. The more games are played, the better these values reflect the sequence of moves that X and O must make to win or tie. To train this model (machine learning parlance for the algorithm that updates the values/parameters mentioned above), I programmed the computer to play randomly chosen moves for X and O, until the game ended. If, say, player X won, then the value of every game state traversed was increased by 1 to indicate that X was favored. On the other hand, if player O won, then the value of every game state traversed was decreased by 1 to indicate that O was favored. Here is an example:
X wins!
Let’s say that this is the first iteration that the model is trained on. Then, the next time the model sees this game state,
it will recognize that X has an advantage. In the same vein, the model now also thinks that the empty game state is favorable towards X, since, in the one game that was played, when the empty game state was traversed, X won.
If we run these randomized games enough times (I ran ten million iterations), every move in every game state has most likely been made, which means that the model is able to give a meaningful evaluation for any game state. However, there is one major problem with this approach, in that the model only indicates who is favored when they make a random move, not when they make the best move. To illustrate this, let’s examine the following game state:
(O’s turn)
Here, player O has two options: they can win the game by putting their O on the bottom center square, or lose the game by putting it on the right center square. Any seasoned tic-tac-toe player would make the right move in this scenario, and win the game. However, since the model trains on random moves, it thinks that player O will win half the time and lose half the time. Thus, to the model, this game state is not favorable to either player, when in reality it is absolutely favored towards O.
During my first meeting with Spiros and Evert, they pointed out this flaw in my model. Evert suggested that I study up on something called a minimax algorithm, which circumvents this flaw, and apply it to tic-tac-toe. This set me on the next step of my journey.
Enter Minimax
The content of this section takes inspiration from thisarticle.
In the minimax algorithm, the two players are known as the ‘maximizer’ and the ‘minimizer’. In the case of tic-tac-toe, X would be the maximizer and O the minimizer. The maximizer’s goal is to maximize their score, while the minimizer’s goal is to minimize their score. In tic-tac-toe, the minimax algorithm is implemented so that a win by X is a score of +1, a win by O is a score of -1, and a tie is simply 0. So X, seeking to maximize their score, would want to win, which makes sense.
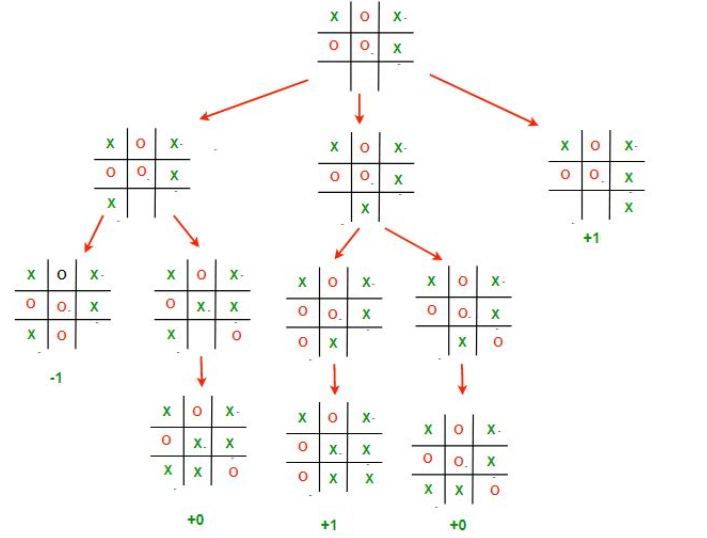
Now, if X wanted to maximize their score through some move, they would have to consider O’s move, who would try to minimize the score. But before O makes their move, they would have to consider X’s next move. This creates a sort of back-and-forth, recursive dynamic in the minimax algorithm. In order for either player to make the best move, they would have to go through all possible moves they can make, and all possible moves their opponent can make after that, and so on and so forth. Here is a relatively simple example of the minimax algorithm at work:
Let’s start from the top. X has three possible moves they can make, and evaluates each of them.
In the leftmost branch, the result is either -1 or 0, but which is the real score? Well, we expect O to make their best move, and since they are trying to minimize the score, we expect them to choose the ‘-1’ case. So we can say that this move results in a score of -1.
In the middle branch, the result is either 1 or 0, and, following the same reasoning as before, O chooses the move corresponding to the minimal score, resulting in a score of 0.
Finally, the last branch results in X winning, so the score is +1.
Now, X can finally choose their best move, and in the interest of maximizing the score, places their X on the bottom right square. Intuitively, this makes sense because it was the only move that wins the game for X outright.
Great, but what would a minimax algorithm look like in Quantum Tiqtaqtoe?
Enter Expecti-Minimax
Expectiminimax contains the same core idea as minimax, but something interesting happens when the game board collapses. The algorithm can’t know for sure what the board will look like after collapse, so all it can do is calculate an expected value of the result (hence the name). Let’s look at an example:
Here, collapse occurs, and one branch (top) results in a tie, while the other (bottom) results in O winning. Since a tie is equal to 0 and an O win is equal to -1, the algorithm treats the score as
Note: the sum is divided by two because both outcomes have a ½ probability of occurring.
Solving the Game
Using the expecti-minimax algorithm, I effectively ‘solved’ the minimal and moderate versions of quantum tiqtaqtoe. However, even though the algorithm will always show the best move, the outcome from game to game might not be the same due to the inherent element of randomness. The most interesting of all my discoveries was probably the first move that the algorithm suggests for X, which I was able to make sense of both intuitively and logically. I challenge you all to find it! (Hint: it is the same for both the minimal and moderate versions.)
It turns out that when X plays optimally, they will always win the minimal version no matter what O plays. Meanwhile, in the moderate version, X will win most of the time, but not all the time. The probability distribution is as follows:
(Another challenge: why are the denominators powers of two?)
Having satisfied my curiosity (for now), I’m looking forward to creating a new game of my own: 4 by 4 quantum tic-tac-toe. Currently, I am working on an algorithm that will give the best move, but since a 4×4 board is almost two times larger than a 3×3 board, the computational runtime of an expectiminimax algorithm would be far too large. As such, I am exploring the use of heuristics, which is sort of what the human mind uses to approach a game like tic-tac-toe. Because of this reliance on heuristics, there is no longer a guarantee that the algorithm will always make the best move, making this new adventure all the more mysterious and captivating.
On December 6, I gave a keynote address at the Q2B 2023 Conference in Silicon Valley. Here is a transcript of my remarks.
Toward quantum value
The theme of this year’s Q2B meeting is “The Roadmap to Quantum Value.” I interpret “quantum value” as meaning applications of quantum computing that have practical utility for end-users in business. So I’ll begin by reiterating a point I have made repeatedly in previous appearances at Q2B. As best we currently understand, the path to economic impact is the road through fault-tolerant quantum computing. And that poses daunting challenges for our field and for the quantum industry.
We are in the NISQ era. NISQ (rhymes with “risk’”) is an acronym meaning “Noisy Intermediate-Scale Quantum.” Here “intermediate-scale” conveys that current quantum computing platforms with of order 100 qubits are difficult to simulate by brute force using the most powerful currently existing supercomputers. “Noisy” reminds us that today’s quantum processors are not error-corrected, and noise is a serious limitation on their computational power. NISQ technology already has noteworthy scientific value. But as of now there is no proposed application of NISQ computing with commercial value for which quantum advantage has been demonstrated when compared to the best classical hardware running the best algorithms for solving the same problems. Furthermore, currently there are no persuasive theoretical arguments indicating that commercially viable applications will be found that do not use quantum error-correcting codes and fault-tolerant quantum computing.
A useful survey of quantum computing applications, over 300 pages long, recently appeared, providing rough estimates of end-to-end run times for various quantum algorithms. This is hardly the last word on the subject — new applications are continually proposed, and better implementations of existing algorithms continually arise. But it is a valuable snapshot of what we understand today, and it is sobering.
There can be quantum advantage in some applications of quantum computing to optimization, finance, and machine learning. But in this application area, the speedups are typically at best quadratic, meaning the quantum run time scales as the square root of the classical run time. So the advantage kicks in only for very large problem instances and deep circuits, which we won’t be able to execute without error correction.
Larger polynomial advantage and perhaps superpolynomial advantage is possible in applications to chemistry and materials science, but these may require at least hundreds of very well-protected logical qubits, and hundreds of millions of very high-fidelity logical gates, if not more. Quantum fault tolerance will be needed to run these applications, and fault tolerance has a hefty cost in both the number of physical qubits and the number of physical gates required. We should also bear in mind that the speed of logical gates is relevant, since the run time as measured by the wall clock will be an important determinant of the value of quantum algorithms.
Overcoming noise in quantum devices
Already in today’s quantum processors steps are taken to address limitations imposed by the noise — we use error mitigation methods like zero noise extrapolation or probabilistic error cancellation. These methods work effectively at extending the size of the circuits we can execute with useful fidelity. But the asymptotic cost scales exponentially with the size of the circuit, so error mitigation alone may not suffice to reach quantum value. Quantum error correction, on the other hand, scales much more favorably, like a power of a logarithm of the circuit size. But quantum error correction is not practical yet. To make use of it, we’ll need better two-qubit gate fidelities, many more physical qubits, robust systems to control those qubits, as well as the ability to perform fast and reliable mid-circuit measurements and qubit resets; all these are technically demanding goals.
To get a feel for the overhead cost of fault-tolerant quantum computing, consider the surface code — it’s presumed to be the best near-term prospect for achieving quantum error correction, because it has a high accuracy threshold and requires only geometrically local processing in two dimensions. Once the physical two-qubit error rate is below the threshold value of about 1%, the probability of a logical error per error correction cycle declines exponentially as we increase the code distance d:
Plogical = (0.1)(Pphysical/Pthreshold)(d+1)/2
where the number of physical qubits in the code block (which encodes a single protected qubit) is the distance squared.
Suppose we wish to execute a circuit with 1000 qubits and 100 million time steps. Then we want the probability of a logical error per cycle to be 10-11. Assuming the physical error rate is 10-3, better than what is currently achieved in multi-qubit devices, from this formula we infer that we need a code distance of 19, and hence 361 physical qubits to encode each logical qubit, and a comparable number of ancilla qubits for syndrome measurement — hence over 700 physical qubits per logical qubit, or a total of nearly a million physical qubits. If the physical error rate improves to 10-4 someday, that cost is reduced, but we’ll still need hundreds of thousands of physical qubits if we rely on the surface code to protect this circuit.
Progress toward quantum error correction
The study of error correction is gathering momentum, and I’d like to highlight some recent experimental and theoretical progress. Specifically, I’ll remark on three promising directions, all with the potential to hasten the arrival of the fault-tolerant era: erasure conversion, biased noise, and more efficient quantum codes.
Erasure conversion
Error correction is more effective if we know when and where the errors occurred. To appreciate the idea, consider the case of a classical repetition code that protects against bit flips. If we don’t know which bits have errors we can decode successfully by majority voting, assuming that fewer than half the bits have errors. But if errors are heralded then we can decode successfully by just looking at any one of the undamaged bits. In quantum codes the details are more complicated but the same principle applies — we can recover more effectively if so-called erasure errors dominate; that is, if we know which qubits are damaged and in which time steps. “Erasure conversion” means fashioning a processor such that the dominant errors are erasure errors.
We can make use of this idea if the dominant errors exit the computational space of the qubit, so that an error can be detected without disturbing the coherence of undamaged qubits. One realization is with Alkaline earth Rydberg atoms in optical tweezers, where 0 is encoded as a low energy state, and 1 is a highly excited Rydberg state. The dominant error is the spontaneous decay of the 1 to a lower energy state. But if the atomic level structure and the encoding allow, 1 usually decays not to a 0, but rather to another state g. We can check whether the g state is occupied, to detect whether or not the error occurred, without disturbing a coherent superposition of 0 and 1.
Erasure conversion can also be arranged in superconducting devices, by using a so-called dual-rail encoding of the qubit in a pair of transmons or a pair of microwave resonators. With two resonators, for example, we can encode a qubit by placing a single photon in one resonator or the other. The dominant error is loss of the photon, causing either the 01 state or the 10 state to decay to 00. One can check whether the state is 00, detecting whether the error occurred, without disturbing a coherent superposition of 01 and 10.
Erasure detection has been successfully demonstrated in recent months, for both atomic (here and here) and superconducting (here and here) qubit encodings.
Biased noise
Another setting in which the effectiveness of quantum error correction can be enhanced is when the noise is highly biased. Quantum error correction is more difficult than classical error correction partly because more types of errors can occur — a qubit can flip in the standard basis, or it can flip in the complementary basis, what we call a phase error. In suitably designed quantum hardware the bit flips are highly suppressed, so we can concentrate the error-correcting power of the code on protecting against phase errors. For this scheme to work, it is important that phase errors occurring during the execution of a quantum gate do not propagate to become bit-flip errors. And it was realized just a few years ago that such bias-preserving gates are possible for qubits encoded in continuous variable systems like microwave resonators.
Specifically, we may consider a cat code, in which the encoded 0 and encoded 1 are coherent states, well separated in phase space. Then bit flips are exponentially suppressed as the mean photon number in the resonator increases. The main source of error, then, is photon loss from the resonator, which induces a phase error for the cat qubit, with an error rate that increases only linearly with photon number. We can then strike a balance, choosing a photon number in the resonator large enough to provide physical protection against bit flips, and then use a classical code like the repetition code to build a logical qubit well protected against phase flips as well.
Work on such repetition cat codes is ongoing (see here, here, and here), and we can expect to hear about progress in that direction in the coming months.
More efficient codes
Another exciting development has been the recent discovery of quantum codes that are far more efficient than the surface code. These include constant-rate codes, in which the number of protected qubits scales linearly with the number of physical qubits in the code block, in contrast to the surface code, which protects just a single logical qubit per block. Furthermore, such codes can have constant relative distance, meaning that the distance of the code, a rough measure of how many errors can be corrected, scales linearly with the block size rather than the square root scaling attained by the surface code.
These new high-rate codes can have a relatively high accuracy threshold, can be efficiently decoded, and schemes for executing fault-tolerant logical gates are currently under development.
A drawback of the high-rate codes is that, to extract error syndromes, geometrically local processing in two dimensions is not sufficient — long-range operations are needed. Nonlocality can be achieved through movement of qubits in neutral atom tweezer arrays or ion traps, or one can use the native long-range coupling in an ion trap processor. Long-range coupling is more challenging to achieve in superconducting processors, but should be possible.
An example with potential near-term relevance is a recently discovered code with distance 12 and 144 physical qubits. In contrast to the surface code with similar distance and length which encodes just a single logical qubit, this code protects 12 logical qubits, a significant improvement in encoding efficiency.
The quest for practical quantum error corrections offers numerous examples like these of co-design. Quantum error correction schemes are adapted to the features of the hardware, and ideas about quantum error correction guide the realization of new hardware capabilities. This fruitful interplay will surely continue.
An exciting time for Rydberg atom arrays
In this year’s hardware news, now is a particularly exciting time for platforms based on Rydberg atoms trapped in optical tweezer arrays. We can anticipate that Rydberg platforms will lead the progress in quantum error correction for at least the next few years, if two-qubit gate fidelities continue to improve. Thousands of qubits can be controlled, and geometrically nonlocal operations can be achieved by reconfiguring the atomic positions. Further improvement in error correction performance might be possible by means of erasure conversion. Significant progress in error correction using Rydberg platforms is reported in a paper published today.
But there are caveats. So far, repeatable error syndrome measurement has not been demonstrated. For that purpose, continuous loading of fresh atoms needs to be developed. And both the readout and atomic movement are relatively slow, which limits the clock speed.
Movability of atomic qubits will be highly enabling in the short run. But in the longer run, movement imposes serious limitations on clock speed unless much faster movement can be achieved. As things currently stand, one can’t rapidly accelerate an atom without shaking it loose from an optical tweezer, or rapidly accelerate an ion without heating its motional state substantially. To attain practical quantum computing using Rydberg arrays, or ion traps, we’ll eventually need to make the clock speed much faster.
Cosmic rays!
To be fair, other platforms face serious threats as well. One is the vulnerability of superconducting circuits to ionizing radiation. Cosmic ray muons for example will occasionally deposit a large amount of energy in a superconducting circuit, creating many phonons which in turn break Cooper pairs and induce qubit errors in a large region of the chip, potentially overwhelming the error-correcting power of the quantum code. What can we do? We might go deep underground to reduce the muon flux, but that’s expensive and inconvenient. We could add an additional layer of coding to protect against an event that wipes out an entire surface code block; that would increase the overhead cost of error correction. Or maybe modifications to the hardware can strengthen robustness against ionizing radiation, but it is not clear how to do that.
Outlook
Our field and the quantum industry continue to face a pressing question: How will we scale up to quantum computing systems that can solve hard problems? The honest answer is: We don’t know yet. All proposed hardware platforms need to overcome serious challenges. Whatever technologies may seem to be in the lead over, say, the next 10 years might not be the best long-term solution. For that reason, it remains essential at this stage to develop a broad array of hardware platforms in parallel.
Today’s NISQ technology is already scientifically useful, and that scientific value will continue to rise as processors advance. The path to business value is longer, and progress will be gradual. Above all, we have good reason to believe that to attain quantum value, to realize the grand aspirations that we all share for quantum computing, we must follow the road to fault tolerance. That awareness should inform our thinking, our strategy, and our investments now and in the years ahead.
Crossing the quantum chasm (image generated using Midjourney)