Building Quantum Computers: A Practical Introduction by Shayan Majidy, Christopher Wilson, and Raymond Laflamme has been published by Cambridge University Press and will be released in the US on September 30. The authors invited me to write a Foreword for the book, which I was happy to do. The publisher kindly granted permission for me to post the Foreword here on Quantum Frontiers.
Foreword
The principles of quantum mechanics, which as far as we know govern all natural phenomena, were discovered in 1925. For 99 years we have built on that achievement to reach a comprehensive understanding of much of the physical world, from molecules to materials to elementary particles and much more. No comparably revolutionary advance in fundamental science has occurred since 1925. But a new revolution is in the offing.
Up until now, most of what we have learned about the quantum world has resulted from considering the behavior of individual particles — for example a single electron propagating as a wave through a crystal, unfazed by barriers that seem to stand in its way. Understanding that single-particle physics has enabled us to explore nature in unprecedented ways, and to build information technologies that have profoundly transformed our lives.
What’s happening now is we’re learning how to instruct particles to evolve in coordinated ways that can’t be accurately described in terms of the behavior of one particle at a time. The particles, as we like to say, can become entangled. Many particles, like electrons or photons or atoms, when highly entangled, exhibit an extraordinary complexity that we can’t capture with the most powerful of today’s supercomputers, or with our current theories of how nature works. That opens extraordinary opportunities for new discoveries and new applications.
Most temptingly, we anticipate that by building and operating large-scale quantum computers, which control the evolution of very complex entangled quantum systems, we will be able to solve some computational problems that are far beyond the reach of today’s digital computers. The concept of a quantum computer was proposed over 40 years ago, and the task of building quantum computing hardware has been pursued in earnest since the 1990s. After decades of steady progress, quantum information processors with hundreds of qubits have become feasible and are scientifically valuable. But we may need quantum processors with millions of qubits to realize practical applications of broad interest. There is still a long way to go.
Why is it taking so long? A conventional computer processes bits, where each bit could be, say, a switch which is either on or off. To build highly complex entangled quantum states, the fundamental information-carrying component of a quantum computer must be what we call a “qubit” rather than a bit. The trouble is that qubits are much more fragile than bits — when a qubit interacts with its environment, the information it carries is irreversibly damaged, a process called decoherence. To perform reliable logical operations on qubits, we need to prevent decoherence by keeping the qubits nearly perfectly isolated from their environment. That’s very hard to do. And because a qubit, unlike a bit, can change continuously, precisely controlling a qubit is a further challenge, even when decoherence is in check.
While theorists may find it convenient to regard a qubit (or a bit) as an abstract object, in an actual processor a qubit needs to be encoded in a particular physical system. There are many options. It might, for example, be encoded in a single atom which can be in either one of two long-lived internal states. Or the spin of a single atomic nucleus or electron which points either up or down along some axis. Or a single photon that occupies either one of two possible optical modes. These are all remarkable encodings, because the qubit resides in a very simple single quantum system, yet, thanks to technical advances over several decades, we have learned to control such qubits reasonably well. Alternatively, the qubit could be encoded in a more complex system, like a circuit conducting electricity without resistance at very low temperature. This is also remarkable, because although the qubit involves the collective motion of billions of pairs of electrons, we have learned to make it behave as though it were a single atom.
To run a quantum computer, we need to manipulate individual qubits and perform entangling operations on pairs of qubits. Once we can perform such single-qubit and two-qubit “quantum gates” with sufficient accuracy, and measure and initialize the qubits as well, then in principle we can perform any conceivable quantum computation by assembling sufficiently many qubits and executing sufficiently many gates.
It’s a daunting engineering challenge to build and operate a quantum system of sufficient complexity to solve very hard computation problems. That systems engineering task, and the potential practical applications of such a machine, are both beyond the scope of Building Quantum Computers. Instead the focus is on the computer’s elementary constituents for four different qubit modalities: nuclear spins, photons, trapped atomic ions, and superconducting circuits. Each type of qubit has its own fascinating story, told here expertly and with admirable clarity.
For each modality a crucial question must be addressed: how to produce well-controlled entangling interactions between two qubits. Answers vary. Spins have interactions that are always on, and can be “refocused” by applying suitable pulses. Photons hardly interact with one another at all, but such interactions can be mocked up using appropriate measurements. Because of their Coulomb repulsion, trapped ions have shared normal modes of vibration that can be manipulated to generate entanglement. Couplings and frequencies of superconducting qubits can be tuned to turn interactions on and off. The physics underlying each scheme is instructive, with valuable lessons for the quantum informationists to heed.
Various proposed quantum information processing platforms have characteristic strengths and weaknesses, which are clearly delineated in this book. For now it is important to pursue a variety of hardware approaches in parallel, because we don’t know for sure which ones have the best long term prospects. Furthermore, different qubit technologies might be best suited for different applications, or a hybrid of different technologies might be the best choice in some settings. The truth is that we are still in the early stages of developing quantum computing systems, and there is plenty of potential for surprises that could dramatically alter the outlook.
Building large-scale quantum computers is a grand challenge facing 21st-century science and technology. And we’re just getting started. The qubits and quantum gates of the distant future may look very different from what is described in this book, but the authors have made wise choices in selecting material that is likely to have enduring value. Beyond that, the book is highly accessible and fun to read. As quantum technology grows ever more sophisticated, I expect the study and control of highly complex many-particle systems to become an increasingly central theme of physical science. If so, Building Quantum Computers will be treasured reading for years to come.
On December 6, I gave a keynote address at the Q2B 2023 Conference in Silicon Valley. Here is a transcript of my remarks.
Toward quantum value
The theme of this year’s Q2B meeting is “The Roadmap to Quantum Value.” I interpret “quantum value” as meaning applications of quantum computing that have practical utility for end-users in business. So I’ll begin by reiterating a point I have made repeatedly in previous appearances at Q2B. As best we currently understand, the path to economic impact is the road through fault-tolerant quantum computing. And that poses daunting challenges for our field and for the quantum industry.
We are in the NISQ era. NISQ (rhymes with “risk’”) is an acronym meaning “Noisy Intermediate-Scale Quantum.” Here “intermediate-scale” conveys that current quantum computing platforms with of order 100 qubits are difficult to simulate by brute force using the most powerful currently existing supercomputers. “Noisy” reminds us that today’s quantum processors are not error-corrected, and noise is a serious limitation on their computational power. NISQ technology already has noteworthy scientific value. But as of now there is no proposed application of NISQ computing with commercial value for which quantum advantage has been demonstrated when compared to the best classical hardware running the best algorithms for solving the same problems. Furthermore, currently there are no persuasive theoretical arguments indicating that commercially viable applications will be found that do not use quantum error-correcting codes and fault-tolerant quantum computing.
A useful survey of quantum computing applications, over 300 pages long, recently appeared, providing rough estimates of end-to-end run times for various quantum algorithms. This is hardly the last word on the subject — new applications are continually proposed, and better implementations of existing algorithms continually arise. But it is a valuable snapshot of what we understand today, and it is sobering.
There can be quantum advantage in some applications of quantum computing to optimization, finance, and machine learning. But in this application area, the speedups are typically at best quadratic, meaning the quantum run time scales as the square root of the classical run time. So the advantage kicks in only for very large problem instances and deep circuits, which we won’t be able to execute without error correction.
Larger polynomial advantage and perhaps superpolynomial advantage is possible in applications to chemistry and materials science, but these may require at least hundreds of very well-protected logical qubits, and hundreds of millions of very high-fidelity logical gates, if not more. Quantum fault tolerance will be needed to run these applications, and fault tolerance has a hefty cost in both the number of physical qubits and the number of physical gates required. We should also bear in mind that the speed of logical gates is relevant, since the run time as measured by the wall clock will be an important determinant of the value of quantum algorithms.
Overcoming noise in quantum devices
Already in today’s quantum processors steps are taken to address limitations imposed by the noise — we use error mitigation methods like zero noise extrapolation or probabilistic error cancellation. These methods work effectively at extending the size of the circuits we can execute with useful fidelity. But the asymptotic cost scales exponentially with the size of the circuit, so error mitigation alone may not suffice to reach quantum value. Quantum error correction, on the other hand, scales much more favorably, like a power of a logarithm of the circuit size. But quantum error correction is not practical yet. To make use of it, we’ll need better two-qubit gate fidelities, many more physical qubits, robust systems to control those qubits, as well as the ability to perform fast and reliable mid-circuit measurements and qubit resets; all these are technically demanding goals.
To get a feel for the overhead cost of fault-tolerant quantum computing, consider the surface code — it’s presumed to be the best near-term prospect for achieving quantum error correction, because it has a high accuracy threshold and requires only geometrically local processing in two dimensions. Once the physical two-qubit error rate is below the threshold value of about 1%, the probability of a logical error per error correction cycle declines exponentially as we increase the code distance d:
Plogical = (0.1)(Pphysical/Pthreshold)(d+1)/2
where the number of physical qubits in the code block (which encodes a single protected qubit) is the distance squared.
Suppose we wish to execute a circuit with 1000 qubits and 100 million time steps. Then we want the probability of a logical error per cycle to be 10-11. Assuming the physical error rate is 10-3, better than what is currently achieved in multi-qubit devices, from this formula we infer that we need a code distance of 19, and hence 361 physical qubits to encode each logical qubit, and a comparable number of ancilla qubits for syndrome measurement — hence over 700 physical qubits per logical qubit, or a total of nearly a million physical qubits. If the physical error rate improves to 10-4 someday, that cost is reduced, but we’ll still need hundreds of thousands of physical qubits if we rely on the surface code to protect this circuit.
Progress toward quantum error correction
The study of error correction is gathering momentum, and I’d like to highlight some recent experimental and theoretical progress. Specifically, I’ll remark on three promising directions, all with the potential to hasten the arrival of the fault-tolerant era: erasure conversion, biased noise, and more efficient quantum codes.
Erasure conversion
Error correction is more effective if we know when and where the errors occurred. To appreciate the idea, consider the case of a classical repetition code that protects against bit flips. If we don’t know which bits have errors we can decode successfully by majority voting, assuming that fewer than half the bits have errors. But if errors are heralded then we can decode successfully by just looking at any one of the undamaged bits. In quantum codes the details are more complicated but the same principle applies — we can recover more effectively if so-called erasure errors dominate; that is, if we know which qubits are damaged and in which time steps. “Erasure conversion” means fashioning a processor such that the dominant errors are erasure errors.
We can make use of this idea if the dominant errors exit the computational space of the qubit, so that an error can be detected without disturbing the coherence of undamaged qubits. One realization is with Alkaline earth Rydberg atoms in optical tweezers, where 0 is encoded as a low energy state, and 1 is a highly excited Rydberg state. The dominant error is the spontaneous decay of the 1 to a lower energy state. But if the atomic level structure and the encoding allow, 1 usually decays not to a 0, but rather to another state g. We can check whether the g state is occupied, to detect whether or not the error occurred, without disturbing a coherent superposition of 0 and 1.
Erasure conversion can also be arranged in superconducting devices, by using a so-called dual-rail encoding of the qubit in a pair of transmons or a pair of microwave resonators. With two resonators, for example, we can encode a qubit by placing a single photon in one resonator or the other. The dominant error is loss of the photon, causing either the 01 state or the 10 state to decay to 00. One can check whether the state is 00, detecting whether the error occurred, without disturbing a coherent superposition of 01 and 10.
Erasure detection has been successfully demonstrated in recent months, for both atomic (here and here) and superconducting (here and here) qubit encodings.
Biased noise
Another setting in which the effectiveness of quantum error correction can be enhanced is when the noise is highly biased. Quantum error correction is more difficult than classical error correction partly because more types of errors can occur — a qubit can flip in the standard basis, or it can flip in the complementary basis, what we call a phase error. In suitably designed quantum hardware the bit flips are highly suppressed, so we can concentrate the error-correcting power of the code on protecting against phase errors. For this scheme to work, it is important that phase errors occurring during the execution of a quantum gate do not propagate to become bit-flip errors. And it was realized just a few years ago that such bias-preserving gates are possible for qubits encoded in continuous variable systems like microwave resonators.
Specifically, we may consider a cat code, in which the encoded 0 and encoded 1 are coherent states, well separated in phase space. Then bit flips are exponentially suppressed as the mean photon number in the resonator increases. The main source of error, then, is photon loss from the resonator, which induces a phase error for the cat qubit, with an error rate that increases only linearly with photon number. We can then strike a balance, choosing a photon number in the resonator large enough to provide physical protection against bit flips, and then use a classical code like the repetition code to build a logical qubit well protected against phase flips as well.
Work on such repetition cat codes is ongoing (see here, here, and here), and we can expect to hear about progress in that direction in the coming months.
More efficient codes
Another exciting development has been the recent discovery of quantum codes that are far more efficient than the surface code. These include constant-rate codes, in which the number of protected qubits scales linearly with the number of physical qubits in the code block, in contrast to the surface code, which protects just a single logical qubit per block. Furthermore, such codes can have constant relative distance, meaning that the distance of the code, a rough measure of how many errors can be corrected, scales linearly with the block size rather than the square root scaling attained by the surface code.
These new high-rate codes can have a relatively high accuracy threshold, can be efficiently decoded, and schemes for executing fault-tolerant logical gates are currently under development.
A drawback of the high-rate codes is that, to extract error syndromes, geometrically local processing in two dimensions is not sufficient — long-range operations are needed. Nonlocality can be achieved through movement of qubits in neutral atom tweezer arrays or ion traps, or one can use the native long-range coupling in an ion trap processor. Long-range coupling is more challenging to achieve in superconducting processors, but should be possible.
An example with potential near-term relevance is a recently discovered code with distance 12 and 144 physical qubits. In contrast to the surface code with similar distance and length which encodes just a single logical qubit, this code protects 12 logical qubits, a significant improvement in encoding efficiency.
The quest for practical quantum error corrections offers numerous examples like these of co-design. Quantum error correction schemes are adapted to the features of the hardware, and ideas about quantum error correction guide the realization of new hardware capabilities. This fruitful interplay will surely continue.
An exciting time for Rydberg atom arrays
In this year’s hardware news, now is a particularly exciting time for platforms based on Rydberg atoms trapped in optical tweezer arrays. We can anticipate that Rydberg platforms will lead the progress in quantum error correction for at least the next few years, if two-qubit gate fidelities continue to improve. Thousands of qubits can be controlled, and geometrically nonlocal operations can be achieved by reconfiguring the atomic positions. Further improvement in error correction performance might be possible by means of erasure conversion. Significant progress in error correction using Rydberg platforms is reported in a paper published today.
But there are caveats. So far, repeatable error syndrome measurement has not been demonstrated. For that purpose, continuous loading of fresh atoms needs to be developed. And both the readout and atomic movement are relatively slow, which limits the clock speed.
Movability of atomic qubits will be highly enabling in the short run. But in the longer run, movement imposes serious limitations on clock speed unless much faster movement can be achieved. As things currently stand, one can’t rapidly accelerate an atom without shaking it loose from an optical tweezer, or rapidly accelerate an ion without heating its motional state substantially. To attain practical quantum computing using Rydberg arrays, or ion traps, we’ll eventually need to make the clock speed much faster.
Cosmic rays!
To be fair, other platforms face serious threats as well. One is the vulnerability of superconducting circuits to ionizing radiation. Cosmic ray muons for example will occasionally deposit a large amount of energy in a superconducting circuit, creating many phonons which in turn break Cooper pairs and induce qubit errors in a large region of the chip, potentially overwhelming the error-correcting power of the quantum code. What can we do? We might go deep underground to reduce the muon flux, but that’s expensive and inconvenient. We could add an additional layer of coding to protect against an event that wipes out an entire surface code block; that would increase the overhead cost of error correction. Or maybe modifications to the hardware can strengthen robustness against ionizing radiation, but it is not clear how to do that.
Outlook
Our field and the quantum industry continue to face a pressing question: How will we scale up to quantum computing systems that can solve hard problems? The honest answer is: We don’t know yet. All proposed hardware platforms need to overcome serious challenges. Whatever technologies may seem to be in the lead over, say, the next 10 years might not be the best long-term solution. For that reason, it remains essential at this stage to develop a broad array of hardware platforms in parallel.
Today’s NISQ technology is already scientifically useful, and that scientific value will continue to rise as processors advance. The path to business value is longer, and progress will be gradual. Above all, we have good reason to believe that to attain quantum value, to realize the grand aspirations that we all share for quantum computing, we must follow the road to fault tolerance. That awareness should inform our thinking, our strategy, and our investments now and in the years ahead.
Crossing the quantum chasm (image generated using Midjourney)
Editor’s note: On 10 August 2023, Caltech celebrated the groundbreaking for the Dr. Allen and Charlotte Ginsburg Center for Quantum Precision Measurement, which will open in 2025. At a lunch following the ceremony, John Preskill made these remarks.
Rendering of the facade of the Ginsburg Center
Hello everyone. I’m John Preskill, a professor of theoretical physics at Caltech, and I’m honored to have this opportunity to make some brief remarks on this exciting day.
In 2025, the Dr. Allen and Charlotte Ginsburg Center for Quantum Precision Measurement will open on the Caltech campus. That will certainly be a cause for celebration. Quite fittingly, in that same year, we’ll have something else to celebrate — the 100th anniversary of the formulation of quantum mechanics in 1925. In 1900, it had become clear that the physics of the 19th century had serious shortcomings that needed to be addressed, and for 25 years a great struggle unfolded to establish a firm foundation for the science of atoms, electrons, and light; the momentous achievements of 1925 brought that quest to a satisfying conclusion. No comparably revolutionary advance in fundamental science has occurred since then.
For 98 years now we’ve built on those achievements of 1925 to arrive at a comprehensive understanding of much of the physical world, from molecules to materials to atomic nuclei and exotic elementary particles, and much else besides. But a new revolution is in the offing. And the Ginsburg Center will arise at just the right time and at just the right place to drive that revolution forward.
Up until now, most of what we’ve learned about the quantum world has resulted from considering the behavior of individual particles. A single electron propagating as a wave through a crystal, unfazed by barriers that seem to stand in its way. Or a single photon, bouncing hundreds of times between mirrors positioned kilometers apart, dutifully tracking the response of those mirrors to gravitational waves from black holes that collided in a galaxy billions of light years away. Understanding that single-particle physics has enabled us to explore nature in unprecedented ways, and to build information technologies that have profoundly transformed our lives.
At the groundbreaking: Physics, Math and Astronomy Chair Fiona Harrison, California Assemblymember Chris Holden, President Tom Rosenbaum, Charlotte Ginsburg, Dr. Allen Ginsburg, Pasadena Mayor Victor Gordo, Provost Dave Tirrell.
What’s happening now is that we’re getting increasingly adept at instructing particles to move in coordinated ways that can’t be accurately described in terms of the behavior of one particle at a time. The particles, as we like to say, can become entangled. Many particles, like electrons or photons or atoms, when highly entangled, exhibit an extraordinary complexity that we can’t capture with the most powerful of today’s supercomputers, or with our current theories of how Nature works. That opens extraordinary opportunities for new discoveries and new applications.
We’re very proud of the role Caltech has played in setting the stage for the next quantum revolution. Richard Feynman envisioning quantum computers that far surpass the computers we have today. Kip Thorne proposing ways to use entangled photons to perform extraordinarily precise measurements. Jeff Kimble envisioning and executing ingenious methods for entangling atoms and photons. Jim Eisenstein creating and studying extraordinary phenomena in a soup of entangled electrons. And much more besides. But far greater things are yet to come.
How can we learn to understand and exploit the behavior of many entangled particles that work together? For that, we’ll need many scientists and engineers who work together. I joined the Caltech faculty in August 1983, almost exactly 40 years ago. These have been 40 good years, but I’m having more fun now than ever before. My training was in elementary particle physics. But as our ability to manipulate the quantum world advances, I find that I have more and more in common with my colleagues from different specialties. To fully realize my own potential as a researcher and a teacher, I need to stay in touch with atomic physics, condensed matter physics, materials science, chemistry, gravitational wave physics, computer science, electrical engineering, and much else. Even more important, that kind of interdisciplinary community is vital for broadening the vision of the students and postdocs in our research groups.
Nurturing that community — that’s what the Ginsburg Center is all about. That’s what will happen there every day. That sense of a shared mission, enhanced by colocation, will enable the Ginsburg Center to lead the way as quantum science and technology becomes increasingly central to Caltech’s research agenda in the years ahead, and increasingly important for science and engineering around the globe. And I just can’t wait for 2025.
Editor’s note: Since 2015, the Simons Foundation has supported the “It from Qubit” collaboration, a group of scientists drawing on ideas from quantum information theory to address deep issues in fundamental physics. The collaboration held its “Last Hurrah” event at Perimeter Institute last week. Here is a transcript of remarks by John Preskill at the conference dinner.
It from Qubit 2023 at Perimeter Institute
This meeting is forward-looking, as it should be, but it’s fun to look back as well, to assess and appreciate the progress we’ve made. So my remarks may meander back and forth through the years. Settle back — this may take a while.
We proposed the It from Qubit collaboration in March 2015, in the wake of several years of remarkable progress. Interestingly, that progress was largely provoked by an idea that most of us think is wrong: Black hole firewalls. Wrong perhaps, but challenging to grapple with.
This challenge accelerated a synthesis of quantum computing, quantum field theory, quantum matter, and quantum gravity as well. By 2015, we were already appreciating the relevance to quantum gravity of concepts like quantum error correction, quantum computational complexity, and quantum chaos. It was natural to assemble a collaboration in which computer scientists and information theorists would participate along with high-energy physicists.
We built our proposal around some deep questions where further progress seemed imminent, such as these:
Does spacetime emerge from entanglement? Do black holes have interiors? What is the information-theoretical structure of quantum field theory? Can quantum computers simulate all physical phenomena?
On April 30, 2015 we presented our vision to the Simons Foundation, led by Patrick [Hayden] and Matt [Headrick], with Juan [Maldacena], Lenny [Susskind] and me tagging along. We all shared at that time a sense of great excitement; that feeling must have been infectious, because It from Qubit was successfully launched.
Some It from Qubit investigators at a 2015 meeting.
Since then ideas we talked about in 2015 have continued to mature, to ripen. Now our common language includes ideas like islands and quantum extremal surfaces, traversable wormholes, modular flow, the SYK model, quantum gravity in the lab, nonisometric codes, the breakdown of effective field theory when quantum complexity is high, and emergent geometry described by Von Neumann algebras. In parallel, we’ve seen a surge of interest in quantum dynamics in condensed matter, focused on issues like how entanglement spreads, and how chaotic systems thermalize — progress driven in part by experimental advances in quantum simulators, both circuit-based and analog.
Why did we call ourselves “It from Qubit”? Patrick explained that in our presentation with a quote from John Wheeler in 1990. Wheeler said,
“It from bit” symbolizes the idea that every item of the physical world has at bottom—a very deep bottom, in most instances — an immaterial source and explanation; that which we call reality arises in the last analysis from the posing of yes-or-no questions and the registering of equipment-evoked responses; in short, that all things physical are information-theoretic in origin and that this is a participatory universe.
As is often the case with Wheeler, you’re not quite sure what he’s getting at. But you can glean that Wheeler envisioned that progress in fundamental physics would be hastened by bringing in ideas from information theory. So we updated Wheeler’s vision by changing “it from bit” to “it from qubit.”
As you may know, Richard Feynman had been Wheeler’s student, and he once said this about Wheeler: “Some people think Wheeler’s gotten crazy in his later years, but he’s always been crazy.” So you can imagine how flattered I was when Graeme Smith said the exact same thing about me.
During the 1972-73 academic year, I took a full-year undergraduate course from Wheeler at Princeton that covered everything in physics, so I have a lot of Wheeler stories. I’ll just tell one, which will give you some feel for his teaching style. One day, Wheeler arrives in class dressed immaculately in a suit and tie, as always, and he says: “Everyone take out a sheet of paper, and write down all the equations of physics – don’t leave anything out.” We dutifully start writing equations. The Schrödinger equation, Newton’s laws, Maxwell’s equations, the definition of entropy and the laws of thermodynanics, Navier-Stokes … we had learned a lot. Wheeler collects all the papers, and puts them in a stack on a table at the front of the classroom. He gestures toward the stack and says imploringly “Fly!” [Long pause.] Nothing happens. He tries again, even louder this time: “Fly!” [Long pause.] Nothing happens. Then Wheeler concludes: “On good authority, this stack of papers contains all the equations of physics. But it doesn’t fly. Yet, the universe flies. Something must be missing.”
Channeling Wheeler at the banquet, I implore my equations to fly. Photo by Jonathan Oppenheim.
He was an odd man, but inspiring. And not just odd, but also old. We were 19 and could hardly believe he was still alive — after all, he had worked with Bohr on nuclear fission in the 1930s! He was 61. I’m wiser now, and know that’s not really so old.
Now let’s skip ahead to 1998. Just last week, Strings 2023 happened right here at PI. So it’s fitting to mention that a pivotal Strings meeting occurred 25 years ago, Strings 1998 in Santa Barbara. The participants were in a celebratory mood, so much so that Jeff Harvey led hundreds of physicists in a night of song and dance. It went like this [singing to the tune of “The Macarena”]:
You start with the brane and the brane is BPS. Then you go near the brane and the space is AdS. Who knows what it means? I don’t, I confess. Ehhhh! Maldacena!
You can’t blame them for wanting to celebrate. Admittedly I wasn’t there, so how did I know that hundreds of physicists were singing and dancing? I read about it in the New York Times!
It was significant that by 1998, the Strings meetings had already been held annually for 10 years. You might wonder how that came about. Let’s go back to 1984. Those of you who are too young to remember might not realize that in the late 70s and early 80s string theory was in eclipse. It had initially been proposed as a model of hadrons, but after the discovery of asymptotic freedom in 1973 quantum chromodynamics became accepted as the preferred theory of the strong interactions. (Maybe the QCD string will make a comeback someday – we’ll see.) The community pushing string theory forward shrunk to a handful of people around the world. That changed very abruptly in August 1984. I tried to capture that sudden change in a poem I wrote for John Schwarz’s 60th birthday in 2001. I’ll read it — think of this as a history lesson.
Thirty years ago or more John saw what physics had in store. He had a vision of a string And focused on that one big thing.
But then in nineteen-seven-three Most physicists had to agree That hadrons blasted to debris Were well described by QCD.
The string, it seemed, by then was dead. But John said: “It’s space-time instead! The string can be revived again. Give masses twenty powers of ten!
Then Dr. Green and Dr. Black, Writing papers by the stack, Made One, Two-A, and Two-B glisten. Why is it none of us would listen?
We said, “Who cares if super tricks Bring D to ten from twenty-six? Your theory must have fatal flaws. Anomalies will doom your cause.”
If you weren’t there you couldn’t know The impact of that mighty blow: “The Green-Schwarz theory could be true — It works for S-O-thirty-two!”
Then strings of course became the rage And young folks of a certain age Could not resist their siren call: One theory that explains it all.
Because he never would give in, Pursued his dream with discipline, John Schwarz has been a hero to me. So … please don’t spell it with a “t”!
And 39 years after the revolutionary events of 1984, the intellectual feast launched by string theory still thrives.
In the late 1980s and early 1990s, many high-energy physicists got interested in the black hole information problem. Of course, the problem was 15 years old by then; it arose when Hawking radiation was discovered, as Hawking himself pointed out shortly thereafter. But many of us were drawn to this problem while we waited for the Superconducting Super Collider to turn on. As I have sometimes done when I wanted to learn something, in 1990 I taught a course on quantum field theory in curved spacetime, the main purpose of which was to explain the origin of Hawking radiation, and then for a few years I tried to understand whether information can escape from black holes and if so how, as did many others in those days. That led to a 1992 Aspen program co-organized by Andy Strominger and me on “Quantum Aspects of Black Holes.” Various luminaries were there, among them Hawking, Susskind, Sidney Coleman, Kip Thorne, Don Page, and others. Andy and I were asked to nominate someone from our program to give the Aspen Center colloquium, so of course we chose Lenny, and he gave an engaging talk on “The Puzzle of Black Hole Evaporation.”
At the end of the talk, Lenny reported on discussions he’d had with various physicists he respected about the information problem, and he summarized their views. Of course, Hawking said information is lost. ‘t Hooft said that the S-matrix must be unitary for profound reasons we needed to understand. Polchinski said in 1992 that information is lost and there is no way to retrieve it. Yakir Aharonov said that the information resides in a stable Planck-sized black hole remnant. Sidney Coleman said a black hole is a lump of coal — that was the code in 1992 for what we now call the central dogma of black hole physics, that as seen from the outside a black hole is a conventional quantum system. And – remember this was Lenny’s account of what he claimed people had told him – Frank Wilczek said this is a technical problem, I’ll soon have it solved, while Ed Witten said he did not find the problem interesting.
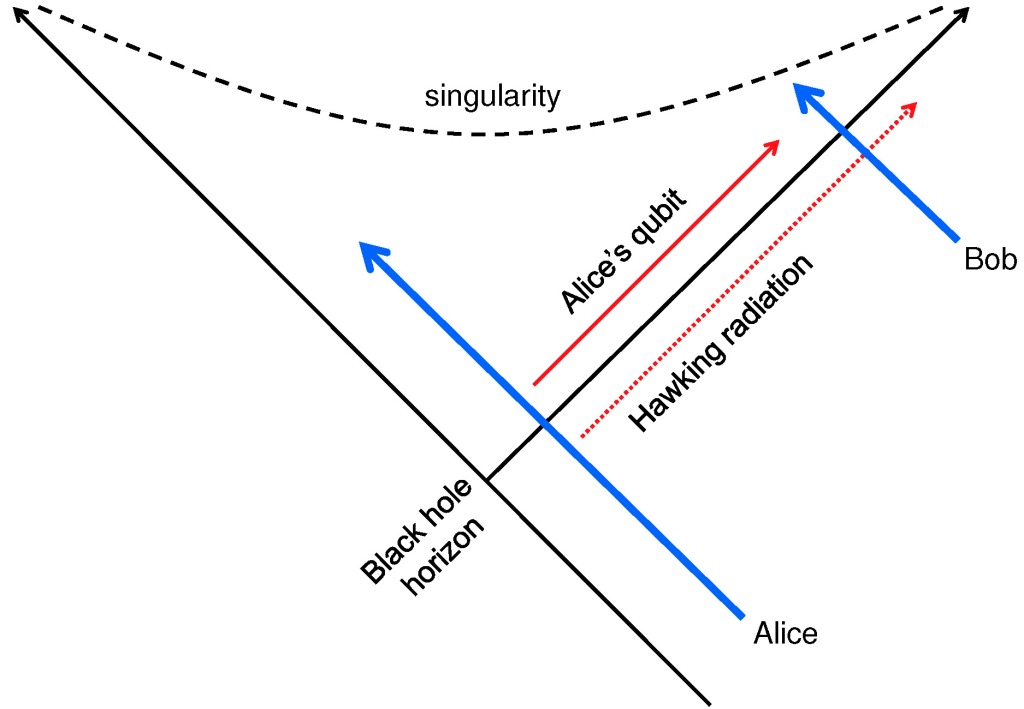
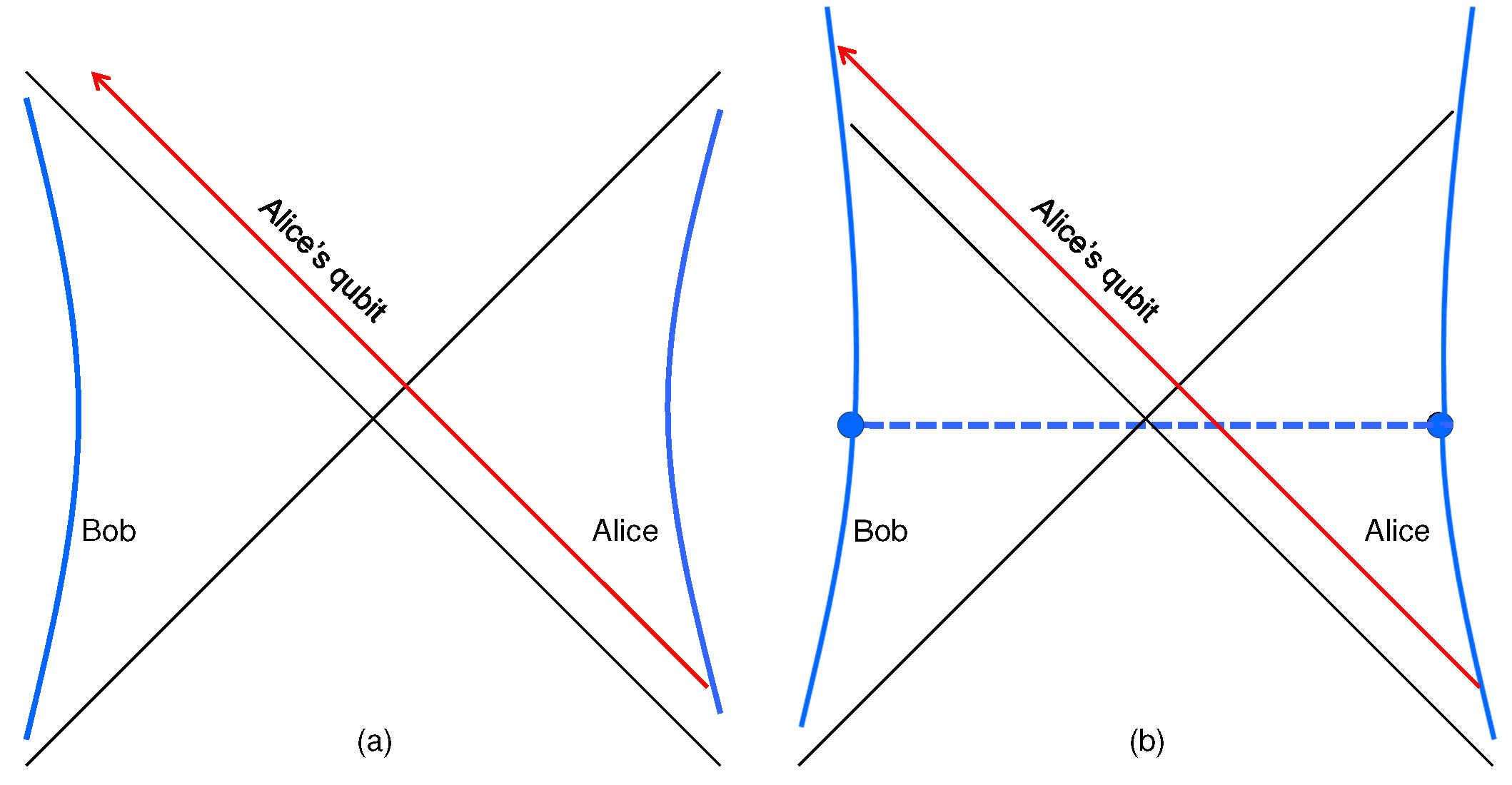
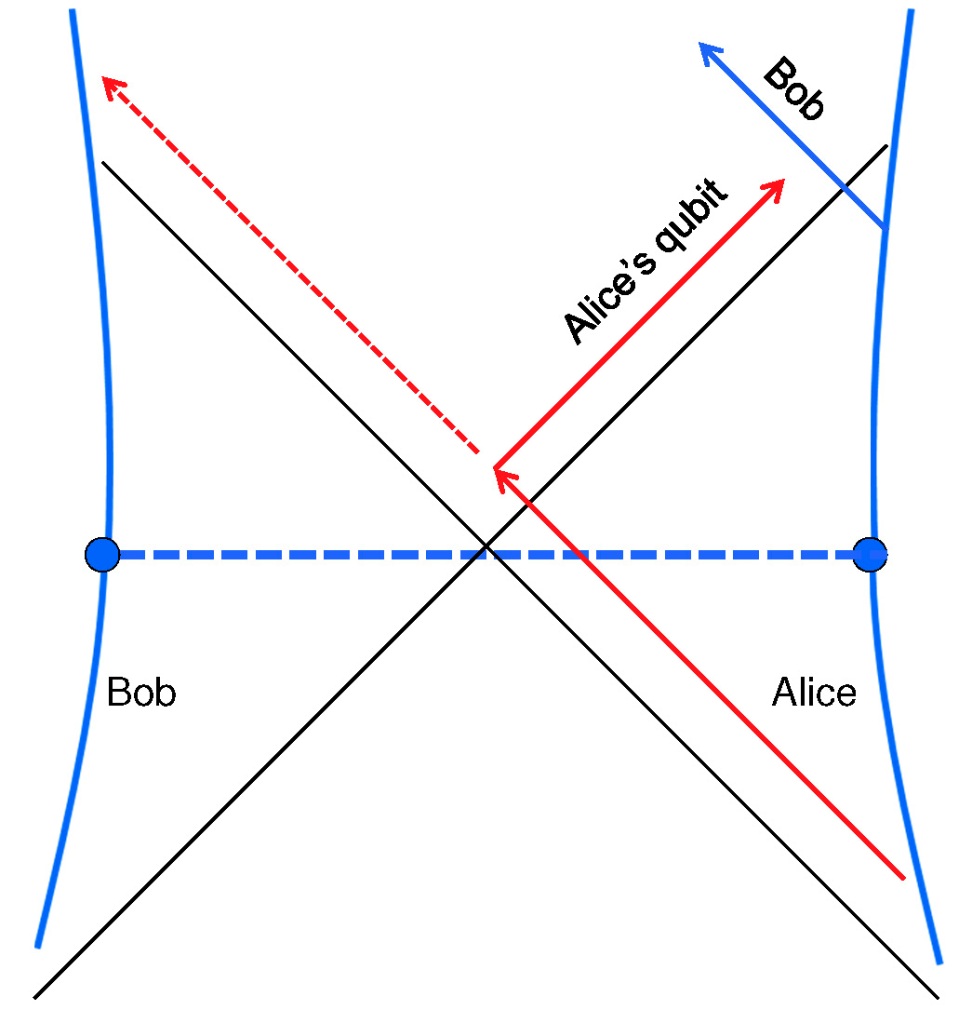
We talked a lot that summer about the no-cloning principle, and our discomfort with the notion that the quantum information encoded in an infalling encyclopedia could be in two places at once on the same time slice, seen inside the black hole by infalling observers and seen outside the black hole by observers who peruse the Hawking radiation. That potential for cloning shook the faith of the self-appointed defenders of unitarity. Andy and I wrote a report at the end of the workshop with a pessimistic tone:
There is an emerging consensus among the participants that Hawking is essentially right – that the information loss paradox portends a true revolution in fundamental physics. If so, then one must go further, and develop a sensible “phenomenological” theory of information loss. One must reconcile the fact of information loss with established principles of physics, such as locality and energy conservation. We expect that many people, stimulated by their participation in the workshop, will now focus attention on this challenge.
There was another memorable event a year later, in June 1993, a conference at the ITP in Santa Barbara (there was no “K” back then), also called “Quantum Aspects of Black Holes.” Among those attending were Susskind, Gibbons, Polchinski, Thorne, Wald, Israel, Bekenstein, and many others. By then our mood was brightening. Rather pointedly, Lenny said to me that week: “Why is this meeting so much better than the one you organized last year?” And I replied, “Because now you think you know the answer!”
That week we talked about “black hole complementarity,” our hope that quantum information being available both inside and outside the horizon could be somehow consistent with the linearity of quantum theory. Complementarity then was a less radical, less wildly nonlocal idea than it became later on. We envisioned that information in an infalling body could stick to the stretched horizon, but not, as I recall, that the black hole interior would be somehow encoded in Hawking radiation emitted long ago — that came later. But anyway, we felt encouraged.
Joe Polchinski organized a poll of the participants, where one could choose among four options.
Information is lost (unitarity violated)
Information escapes (causality violated)
Planck-scale black hole remnants
None of the above
The poll results favored unitarity over information loss by a 60-40 margin. Perhaps not coincidentally, the participants self-identified as 60% high energy physicists and 40% relativists.
The following summer in June 1994, there was a program called Geometry and Gravity at the Newton Institute in Cambridge. Hawking, Gibbons, Susskind, Strominger, Harvey, Sorkin, and (Herman) Verlinde were among the participants. I had more discussions with Lenny that month than any time before or since. I recall sending an email to Paul Ginsparg after one such long discussion in which I said, “When I hear Lenny Susskind speak, I truly believe that information can come out of a black hole.” Secretly, though, having learned about Shor’s algorithm shortly before that program began, I was spending my evenings struggling to understand Shor’s paper. After Cambridge, Lenny visited ‘t Hooft in Utrecht, and returned to Stanford all charged up to write his paper on “The world as a hologram,” in which he credits ‘t Hooft with the idea that “the world is in a sense two-dimensional.”
Important things happened in the next few years: D-branes, counting of black hole microstates, M-theory, and AdS/CFT. But I’ll skip ahead to the most memorable of my visits to Perimeter Institute. (Of course, I always like coming here, because in Canada you use the same electrical outlets we do …)
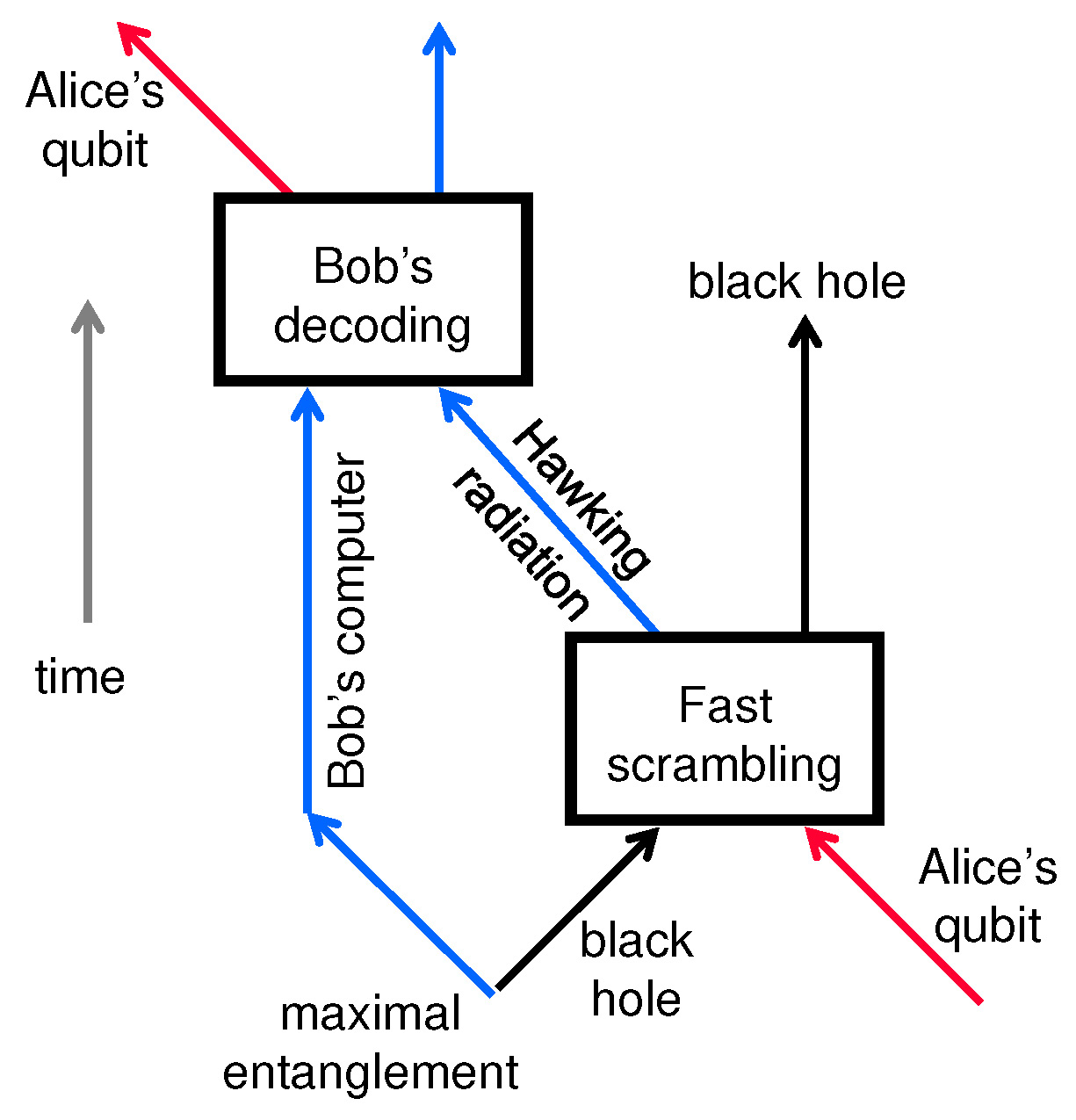
In June 2007, there was a month-long program at PI called “Taming the Quantum World.” I recall that Lucien Hardy objected to that title — he preferred “Let the Beast Loose” — which I guess is a different perspective on the same idea. I talked there about fault-tolerant quantum computing, but more importantly, I shared an office with Patrick Hayden. I already knew Patrick well — he had been a Caltech postdoc — but I was surprised and pleased that he was thinking about black holes. Patrick had already reached crucial insights concerning the behavior of a black hole that is profoundly entangled with its surroundings. That sparked intensive discussions resulting in a paper later that summer called “Black holes as mirrors.” In the acknowledgments you’ll find this passage:
We are grateful for the hospitality of the Perimeter Institute, where we had the good fortune to share an office, and JP thanks PH for letting him use the comfortable chair.
We intended for that paper to pique the interest of both the quantum information and quantum gravity communities, as it seemed to us that the time was ripe to widen the communication channel between the two. Since then, not only has that communication continued, but a deeper synthesis has occurred; most serious quantum gravity researchers are now well acquainted with the core concepts of quantum information science.
That John Schwarz poem I read earlier reminds me that I often used to write poems. I do it less often lately. Still, I feel that you are entitled to hear something that rhymes tonight. But I quickly noticed our field has many words that are quite hard to rhyme, like “chaos” and “dogma.” And perhaps the hardest of all: “Takayanagi.” So I decided to settle for some limericks — that’s easier for me than a full-fledged poem.
This first one captures how I felt when I first heard about AdS/CFT: excited but perplexed.
Spacetime is emergent they say. But emergent in what sort of way? It’s really quite cool, The bulk has a dual! I might understand that someday.
For a quantum information theorist, it was pleasing to learn later on that we can interpret the dictionary as an encoding map, such that the bulk degrees of freedom are protected when a portion of the boundary is erased.
Almheiri and Harlow and Dong Said “you’re thinking about the map wrong.” It’s really a code! That’s the thing that they showed. Should we have known that all along?
(It is easier to rhyme “Dong” than “Takayanagi”.) To see that connection one needed a good grasp of both AdS/CFT and quantum error-correcting codes. In 2014 few researchers knew both, but those guys did.
For all our progress, we still don’t have a complete answer to a key question that inspired IFQ. What’s inside a black hole?
Information loss has been denied. Locality’s been cast aside. When the black hole is gone What fell in’s been withdrawn. I’d still like to know: what’s inside?
We’re also still lacking an alternative nonperturbative formulation of the bulk; we can only say it’s something that’s dual to the boundary. Until we can define both sides of the correspondence, the claim that two descriptions are equivalent, however inspiring, will remain unsatisfying.
Duality I can embrace. Complexity, too, has its place. That’s all a good show But I still want to know: What are the atoms of space?
The question, “What are the atoms of space?” is stolen from Joe Polchinski, who framed it to explain to a popular audience what we’re trying to answer. I miss Joe. He was a founding member of It from Qubit, an inspiring scientific leader, and still an inspiration for all of us today.
The IFQ Simons collaboration may fade away, but the quest that has engaged us these past 8 years goes on. IFQ is the continuation of a long struggle, which took on great urgency with Hawking’s formulation of the information loss puzzle nearly 50 years ago. Understanding quantum gravity and its implications is a huge challenge and a grand quest that humanity is obligated to pursue. And it’s fun and it’s exciting, and I sincerely believe that we’ve made remarkable progress in recent years, thanks in large part to you, the IFQ community. We are privileged to live at a time when truths about the nature of space and time are being unveiled. And we are privileged to be part of this community, with so many like-minded colleagues pulling in the same direction, sharing the joy of facing this challenge.
Where is it all going? Coming back to our pitch to the Simons Foundation in 2015, I was very struck by Juan’s presentation that day, and in particular his final slide. I liked it so much that I stole it and used in my presentations for a while. Juan tried to explain what we’re doing by means of an analogy to biological science. How are the quantumists like the biologists?
Well, bulk quantum gravity is life. We all want to understand life. The boundary theory is chemistry, which underlies life. The quantum information theorists are chemists; they want to understand chemistry in detail. The quantum gravity theorists are biologists, they think chemistry is fine, if it can really help them to understand life. What we want is: molecular biology, the explanation for how life works in terms of the underlying chemistry. The black hole information problem is our fruit fly, the toy problem we need to solve before we’ll be ready to take on a much bigger challenge: finding the cure for cancer; that is, understanding the big bang.
How’s it going? We’ve made a lot of progress since 2015. We haven’t cured cancer. Not yet. But we’re having a lot of fun along the way there.
I’ll end with this hope, addressed especially to those who were not yet born when AdS/CFT was first proposed, or were still scampering around in your playpens. I’ll grant you a reprieve, you have another 8 years. By then: May you cure cancer!
So I propose this toast: To It from Qubit, to our colleagues and friends, to our quest, to curing cancer, to understanding the universe. I wish you all well. Cheers!
Two things you should know about me are: (1) I have unbounded admiration for scientists who can actually finish writing a book, and (2) I’m a firm believer that exciting progress can be ignited when two fields fuse together. So I’m doubly thrilled that Quantum Information Meets Quantum Matter, by IQIM physicist Xie Chen and her colleagues Bei Zeng, Duan-Lu Zhou, and Xiao-Gang Wen, has now been published by Springer.
The authors kindly invited me to write a foreword for the book, which I was happy to contribute. That foreword is reproduced here, with the permission of the publisher.
Foreword
In 1989 I attended a workshop at the University of Minnesota. The organizers had hoped the workshop would spawn new ideas about the origin of high-temperature superconductivity, which had recently been discovered. But I was especially impressed by a talk about the fractional quantum Hall effect by a young physicist named Xiao-Gang Wen.
From Wen I heard for the first time about a concept called topological order. He explained that for some quantum phases of two-dimensional matter the ground state becomes degenerate when the system resides on a surface of nontrivial topology such as a torus, and that the degree of degeneracy provides a useful signature for distinguishing different phases. I was fascinated.
Up until then, studies of phases of matter and the transitions between them usually built on principles annunciated decades earlier by Lev Landau. Landau had emphasized the crucial role of symmetry, and of local order parameters that distinguish different symmetry realizations. Though much of what Wen said went over my head, I did manage to glean that he was proposing a way to distinguish quantum phases founded on much different principles that Landau’s. As a particle physicist I deeply appreciated the power of Landau theory, but I was also keenly aware that the interface of topology and physics had already yielded many novel and fruitful insights.
Mulling over these ideas on the plane ride home, I scribbled a few lines of verse:
Now we are allowed
To disavow Landau.
Wow …
Without knowing where it might lead, one could sense the opening of a new chapter.
At around that same time, another new research direction was beginning to gather steam, the study of quantum information. Richard Feynman and Yuri Manin had suggested that a computer processing quantum information might perform tasks beyond the reach of ordinary digital computers. David Deutsch formalized the idea, which attracted the attention of computer scientists, and eventually led to Peter Shor’s discovery that a quantum computer can factor large numbers in polynomial time. Meanwhile, Alexander Holevo, Charles Bennett and others seized the opportunity to unify Claude Shannon’s information theory with quantum physics, erecting new schemes for quantifying quantum entanglement and characterizing processes in which quantum information is acquired, transmitted, and processed.
The discovery of Shor’s algorithm caused a burst of excitement and activity, but quantum information science remained outside the mainstream of physics, and few scientists at that time glimpsed the rich connections between quantum information and the study of quantum matter. One notable exception was Alexei Kitaev, who had two remarkable insights in the 1990s. He pointed out that finding the ground state energy of a quantum system defined by a “local” Hamiltonian, when suitably formalized, is as hard as any problem whose solution can be verified with a quantum computer. This idea launched the study of Hamiltonian complexity. Kitaev also discerned the relationship between Wen’s concept of topological order and the quantum error-correcting codes that can protect delicate quantum superpositions from the ravages of environmental decoherence. Kitaev’s notion of a topological quantum computer, a mere theorist’s fantasy when proposed in 1997, is by now pursued in experimental laboratories around the world (though the technology still has far to go before truly scalable quantum computers will be capable of addressing hard problems).
Thereafter progress accelerated, led by a burgeoning community of scientists working at the interface of quantum information and quantum matter. Guifre Vidal realized that many-particle quantum systems that are only slightly entangled can be succinctly described using tensor networks. This new method extended the reach of mean-field theory and provided an illuminating new perspective on the successes of the Density Matrix Renormalization Group (DMRG). By proving that the ground state of a local Hamiltonian with an energy gap has limited entanglement (the area law), Matthew Hastings showed that tensor network tools are widely applicable. These tools eventually led to a complete understanding of gapped quantum phases in one spatial dimension.
The experimental discovery of topological insulators focused attention on the interplay of symmetry and topology. The more general notion of a symmetry-protected topological (SPT) phase arose, in which a quantum system has an energy gap in the bulk but supports gapless excitations confined to its boundary which are protected by specified symmetries. (For topological insulators the symmetries are particle-number conservation and time-reversal invariance.) Again, tensor network methods proved to be well suited for establishing a complete classification of one-dimensional SPT phases, and guided progress toward understanding higher dimensions, though many open questions remain.
We now have a much deeper understanding of topological order than when I first heard about it from Wen nearly 30 years ago. A central new insight is that topologically ordered systems have long-range entanglement, and that the entanglement has universal properties, like topological entanglement entropy, which are insensitive to the microscopic details of the Hamiltonian. Indeed, topological order is an intrinsic property of a quantum state and can be identified without reference to any particular Hamiltonian at all. To understand the meaning of long-range entanglement, imagine a quantum computer which applies a sequence of geometrically local operations to an input quantum state, producing an output product state which is completely disentangled. If the time required to complete this disentangling computation is independent of the size of the system, then we say the input state is short-ranged entangled; otherwise it is long-range entangled. More generally (loosely speaking), two states are in different quantum phases if no constant-time quantum computation can convert one state to the other. This fundamental connection between quantum computation and quantum order has many ramifications which are explored in this book.
When is the right time for a book that summarizes the status of an ongoing research area? It’s a subtle question. The subject should be sufficiently mature that enduring concepts and results can be identified and clearly explained. If the pace of progress is sufficiently rapid, and the topics emphasized are not well chosen, then an ill-timed book might become obsolete quickly. On the other hand, the subject ought not to be too mature; only if there are many exciting open questions to attack will the book be likely to attract a sizable audience eager to master the material.
I feel confident that Quantum Information Meets Quantum Matter is appearing at an opportune time, and that the authors have made wise choices about what to include. They are world-class experts, and are themselves responsible for many of the scientific advances explained here. The student or senior scientist who studies this book closely will be well grounded in the tools and ideas at the forefront of current research at the confluence of quantum information science and quantum condensed matter physics.
Indeed, I expect that in the years ahead a steadily expanding community of scientists, including computer scientists, chemists, and high-energy physicists, will want to be well acquainted with the ideas at the heart of Quantum Information Meets Quantum Matter. In particular, growing evidence suggests that the quantum physics of spacetime itself is an emergent manifestation of long-range quantum entanglement in an underlying more fundamental quantum theory. More broadly, as quantum technology grows ever more sophisticated, I believe that the theoretical and experimental study of highly complex many-particle systems will be an increasingly central theme of 21st century physical science. It that’s true, Quantum Information Meets Quantum Matter is bound to hold an honored place on the bookshelves of many scientists for years to come.
Scientists who work on theoretical aspects of quantum computation and information look forward each year to the Conference on Quantum Information Processing (QIP), an annual event since 1998. This year’s meeting, QIP 2019, was hosted this past week by the University of Colorado at Boulder. I attended and had a great time, as I always do.
But this year, in addition to catching up with old friends and talking with colleagues about the latest research advances, I also accepted a humbling assignment: I was the after-dinner speaker at the conference banquet. Here is (approximately) what I said.
QIP 2019 After-Dinner Speech 16 January 2019
Thanks, it’s a great honor to be here, and especially to be introduced by Graeme Smith, my former student. I’m very proud of your success, Graeme. Back in the day, who would have believed it?
And I’m especially glad to join you for these holiday festivities. You do know this is a holiday, don’t you? Yes, as we do every January, we are once again celebrating Gottesman’s birthday! Happy Birthday, Daniel!
Look, I’m kidding of course. Yes, it really is Daniel’s birthday — and I’m sure he appreciates 500 people celebrating in his honor — but I know you’re really here for QIP. We’ve been holding this annual celebration of Quantum Information Processing since 1998 — this is the 22nd QIP. If you are interested in the history of this conference, it’s very helpful that the QIP website includes links to the sites for all previous QIPs. I hope that continues; it conveys a sense of history. For each of those past meetings, you can see what people were talking about, who was there, what they looked like in the conference photo, etc.
Some of you were there the very first time – I was not. But among the attendees at the first QIP, in Arhus in 1998, where a number of brilliant up-and-coming young scientists who have since then become luminaries of our field. Including: Dorit Aharonov, Wim van Dam, Peter Hoyer (who was an organizer), Michele Mosca, John Smolin, Barbara Terhal, and John Watrous. Also somewhat more senior people were there, like Harry Buhrman and Richard Cleve. And pioneers so eminent that we refer to them by their first names alone: Umesh … Gilles … Charlie. It’s nice to know those people are still around, but it validates the health of our field that so many new faces are here, that so many young people are still drawn to QIP, 21 years after it all began. Over 300 students and postdocs are here this year, among nearly 500 attendees.
QIP has changed since the early days. It was smaller and more informal then; the culture was more like a theoretical physics conference, where the organizing committee brainstorms and conjures up a list of invited speakers. The system changed in 2006, when for the first time there were submissions and a program committee. That more formal system opened up opportunities to speak to a broader community, and the quality of the accepted talks has stayed very high — only 18% of 349 submissions were accepted this year.
In fact it has become a badge of honor to speak here — people put it on their CVs: “I gave a QIP contributed talk, or plenary talk, or invited talk.” But what do you think is the highest honor that QIP can bestow? Well, it’s obvious isn’t it? It’s the after-dinner speech! That’s the talk to rule them all. So Graeme told me, when he invited me to do this. And I checked, Gottesman put it on his website, and everyone knows Daniel is a very serious guy. So it must be important. Look, we’re having a banquet in honor of his birthday, and he can hardly crack a smile!
I hear the snickers. I know what you’re thinking. “John, wake up. Don’t you see what Graeme was trying to tell you: You’re too washed up to get a talk accepted to QIP! This is the only way to get you on the program now!” But no, you’re wrong. Graeme told me this is a great honor. And I trust Graeme. He’s an honest man. What? Why are you laughing? It’s true.
I asked Graeme, what should I talk about? He said, “Well, you might try to be funny.” I said, “What do you mean funny? You mean funny Ha Ha? Or do you mean funny the way cheese smells when it’s been in the fridge for too long?” He said, “No I mean really, really funny. You know, like Scott.”
So there it was, the gauntlet had been thrown. Some of you are too young to remember this, but the most notorious QIP after-dinner speech of them all was Scott Aaronson’s in Paris in 2006. Were you there? He used props, and he skewered his more senior colleagues with razor sharp impressions. And remember, this was 2006, so everybody was Scott’s more senior colleague. He was 12 at the time, if memory serves.
He killed. Even I appreciated some of the jokes; for example, as a physicist I could understand this one: Scott said, “I don’t care about the fine structure constant, it’s just a constant.” Ba ding! So Scott set the standard back then, and though many have aspired to clear the bar since then, few have come close.
But remember, this was Graeme I was talking to. And I guess many of you know that I’ve had a lot of students through the years, and I’m proud of all of them. But my memory isn’t what it once was; I need to use mnemonic tricks to keep track of them now. So I have a rating system; I rate them according to how funny they are. And Graeme is practically off the chart, that’s how funny he is. But his is what I call stealth humor. You can’t always tell that he’s being funny, but you assume it.
So I said, “Graeme, What’s the secret? Teach me how to be funny.” I meant it sincerely, and he responded sympathetically. Graeme said, “Well, if you want to be funny, you have to believe you are funny. So when I want to be funny, I think of someone who is funny, and I pretend to be that person.” I said, “Aha, so you go out there and pretend to be Graeme Smith?” And Graeme said, “No, that wouldn’t work for me. I close my eyes and pretend I’m … John Smolin!” I said, “Graeme, you mean you want me to be indistinguishable from John Smolin to an audience of computationally bounded quantum adversaries?” He nodded. “But Graeme, I don’t know any plausible cryptographic assumptions under which that’s possible!”
Fortunately, I had another idea. “I write poems,” I said. “What if I recite a poem? This would set a great precedent. From now on, everyone would know: the QIP after-dinner speech will be a poetry slam!”
Graeme replied “Well, that sounds [long pause] really [pause] boring. But how about a limerick? People love limericks.” I objected, “Graeme, I don’t do limericks. I’m not good at limericks.” But he wouldn’t back down. “Try a limerick,” Graeme said. “People like limericks. They’re so [pause] short.”
But I don’t do limericks. You see:
I was invited to speak here by Graeme.
He knows me well, just as I am.
He was really quite nice
When he gave this advice:
Please don’t do a poetry slam.
Well, like I said, I don’t do limericks.
So now I’m starting to wonder: Why did they invite me to do this anyway? And I think I figured that out. See, Graeme asked me to speak just a few days ago. This must be what happened. Like any smoothly functioning organizing committee, they lined up an after-dinner speaker months in advance, as is the usual practice.
But then, just a few days before the conference began, they began to worry. “We better comb through the speaker’s Twitter feed. Maybe, years ago, our speaker said something offensive, something disqualifying.” And guess what? They found something, something really bad. It turned out that the designated after-dinner speaker had once made a deeply offensive remark about something called “quantum supremacy” … No, wait … that can’t be it.
Can’t you picture the panicky meeting of the organizers? QIP is about to start, and there’s no after-dinner speaker! So people started throwing out suggestions, starting with the usual suspects.
“How about Schroedinger’s Rat?”
“No, he’s booked.”
“Are you telling me Schroedinger’s Rat has another gig that same night?”
“No, no, I mean they booked him. A high-profile journal filed a complaint and he’s in the slammer.”
“Well, how about RogueQIPConference?”
“No, same problem.”
Are you all following that account? You should be. That’s where I go for all the latest fast-breaking quantum news. And that’s where you can get advice about what a quantumist should wear on Halloween. Your costume should combine Sexy with your greatest fear. Right, I mean Sexy P = BQP.
Hey does that worry you? That maybe P = BQP? Does it keep you up at night? It’s possible, isn’t it? But it doesn’t worry me much. If it turns out that P = BQP, I’m just going to make up another word. How about NISP? Noisy Intermediate-Scale Polynomial.
I guess they weren’t able to smoke out whoever is behind Quantum Computing Memes for QMA-Complete Teens. So here I am.
Aside from Limericks, Graeme had another suggestion. He said, “You can reminisce. Tell us what QIP was like in the old days.” “The old days?” I said. “Yes, you know. You could be one of those stooped-over white-haired old men who tells interminable stories that nobody cares about.” I hesitated. “Yeah, I think I could do that.”
Okay, if that’s what you want, I’ll tell a story about my first QIP; that was QIP 2000, which was actually in Montreal in December 1999. It was back in the BPC era — Before Program Committee — and I was an invited speaker (I talked about decoding the toric code). Attending with me was Michael Nielsen, then a Caltech postdoc. Michael’s good friend Ike Chuang was also in the hotel, and they were in adjacent rooms. Both had brought laptops (not a given in 1999), and they wanted to share files. Well, hotels did not routinely offer Internet access back then, and certainly not wireless. But Ike had brought along a spool of Ethernet cable. So Ike and Mike both opened their windows, even though it was freezing cold. And Ike leaned out his window and made repeated attempts to toss the cable though Michael’s window before he finally succeeded, and they connected their computers.
I demanded to know, why the urgent need for a connection? And that was the day I found what most of the rest of the quantum world already knew: Mike and Ike were writing a book! By then they were in the final stages of writing, after some four years of effort (they sent the final draft of the book off to Cambridge University Press the following June).
So, QIP really has changed. The Mike and Ike book is out now. And it’s no longer necessary to open your window on a frigid Montreal evening to share a file with your collaborator.
Boy, it was cold that week in Montreal. [How cold was it?] Well, we went to lunch one day during the conference, and were walking single file down a narrow sidewalk toward the restaurant, when Harry Buhrman, who was right behind me, said: “John, there’s an icicle on your backpack!” You see, I hadn’t screwed the cap all the way shut on my water bottle, water was leaking out of the bottle, soaking through the backback, and immediately freezing on contact with the air; hence the icicle. And ever since then I’ve always been sure to screw my bottle cap shut tight. But over the years since then, lots of other things have spilled in my backpack just the same, and I’d love to tell you about that, but …
Well, my stories may be too lacking in drama to carry the evening …. Look, I don’t care what Graeme says, I’m gonna recite some poems!
I can’t remember how this got started, but some years ago I started writing a poem whenever I needed to introduce a speaker at the Caltech physics colloquium. I don’t do this so much anymore. Partly because I realized that my poetry might reveal my disturbing innermost thoughts, which are best kept private.
Actually, one of my colleagues, after hearing one of my poems, suggested throwing the poem into a black hole. And when we tried it … boom …. it bounced right back, but in a highly scrambled form! And ever since then I’ve had that excuse. If someone says “That’s not such a great poem,” I can shoot back, “Yeah, but it was better before it got scrambled.”
But anyway, here’s one I wrote to honor Ben Schumacher, the pioneer of quantum information theory who named the qubit, and whose compression theorem you all know well.
Ben.
He rocks.
I remember
When
He showed me how to fit
A qubit
In a small box.
I wonder how it feels
To be compressed.
And then to pass
A fidelity test.
Or does it feel
At all, and if it does
Would I squeal
Or be just as I was?
If not undone
I’d become as I’d begun
And write a memorandum
On being random.
Had it felt like a belt
Of rum?
And might it be predicted
That I’d become addicted,
Longing for my session
Of compression?
I’d crawl
To Ben again.
And call,
“Put down your pen!
Don’t stall!
Make me small!”
[Silence]
Yeah that’s the response I usually get when I recite this poem — embarrassed silence, followed by a few nervous titters.
So, as you can see, as in Ben Schumacher’s case, I use poetry to acknowledge our debt to the guiding intellects of our discipline. It doesn’t always work, though. I once tried to write a poem about someone I admire very much, Daniel Gottesman, and it started like this:
When the weather’s hottest, then
I call for Daniel Gottesman.
My apples are less spotted when
Daniel eats the rottenest ten …
It just wasn’t working, so I stopped there. Someday, I’ll go back and finish it. But it’s tough to rhyme “Gottesman.”
More apropos of QIP, some of you may recall that about 12 years ago, one of the hot topics was quantum speedups for formula evaluation, a subject ignited by a brilliant paper by Eddie Farhi, Jeffrey Goldstone, and Sam Gutmann. They showed there’s a polynomial speedup if we use a quantum computer to, say, determine whether a two-player game has a winning strategy. That breakthrough inspired me to write an homage to Eddie, which went:
We’re very sorry, Eddie Farhi
Your algorithm’s quantum.
Can’t run it on those mean machines
Until we’ve actually got ‘em.
You’re not alone, so go on home,
Tell Jeffrey and tell Sam:
Come up with something classical
Or else it’s just a scam.
Unless … you think it’s on the brink
A quantum-cal device.
That solves a game and brings you fame.
Damn! That would be nice!
Now, one thing that Graeme explained to me is that the white-haired-old-man talk has a mandatory feature: It must go on too long. Maybe I have met that criterion by now. Except …
There’s one thing Graeme neglected to say. He never told me that I must not sing at QIP.
You see, there’s a problem: Tragically, though I like to sing, I don’t sing very well at all. And unfortunately, I am totally unaware of this fact. So I sometimes I sing in public, despite strongly worded advice not to do so.
When I was about to leave home on my way to QIP, my wife Roberta asked me, “When are you going to prepare your after-dinner talk?” I said, “Well, I guess I’ll work on it on the plane.” She said, “LA to Denver, that’s not a long enough flight.” I said, “I know!”
What I didn’t say, is that I was thinking of singing a song. If I had, Roberta would have tried to stop me from boarding the plane.
So I guess it’s up to you, what do you think? Should we stop here while I’m (sort of) ahead, or should we take the plunge. Song or no song? How many say song?
All right, that’s good enough for me! This is a song that I usually perform in front of a full orchestra, and I hoped the Denver Symphony Orchestra would be here to back me up. But it turns out they don’t exist anymore. So I’ll just have to do my best.
If you are a fan of Rodgers and Hammerstein, you’ll recognize the tune as a butchered version of Some Enchanted Evening, But the lyrics have changed. This song is called One Entangled Evening.
One entangled evening
We will see a qubit
And another qubit
Across a crowded lab.
And somehow we’ll know
We’ll know even then
This qubit’s entangled
Aligned with its friend.
One entangled evening
We’ll cool down a circuit
See if we can work it
At twenty milli-K.
A circuit that cold
Is worth more than gold
For qubits within it.
Will do as they’re told.
Quantum’s inviting, just as Feynman knew.
The future’s exciting, if we see it through
One entangled evening
Anyons will be braiding
And thereby evading
The noise that haunts the lab.
Then our quantum goods
Will work as they should
Solving the problems
No old gadget could!
Once we have dreamt it, we can make it so.
Once we have dreamt it, we can make it so!
The song lyrics are meant to be uplifting, and I admit they’re corny. No one can promise you that, in the words of another song, “the dreams that you dare to dream really do come true.” That’s not always the case.
At this time in the field of quantum information processing, there are very big dreams, and many of us worry about unrealistic expectations concerning the time scale for quantum computing to have a transformative impact on society. Progress will be incremental. New technology does not change the world all at once; it’s a gradual process.
But I do feel that from the perspective of the broad sweep of history, we (the QIP community and the broader quantum community) are very privileged to be working in this field at a pivotal time in the history of science and technology on earth. We should deeply cherish that good fortune, and the opportunities it affords. I’m confident that great discoveries lie ahead for us.
It’s been a great privilege for me to be a part of a thriving quantum community for more than 20 years. By now, QIP has become one of our venerable traditions, and I hope it continues to flourish for many years ahead. Now it’s up to all of you to make our quantum dreams come true. We are on a great intellectual adventure. Let’s savor it and enjoy it to the hilt!
A few months ago I sat down with Craig Cannon of Y Combinator for a discussion about quantum technology and other things. A lightly edited version was published this week on the Y Combinator blog. The video is also on YouTube:
If you’re in a hurry, or can’t stand the sound of my voice, you might prefer to read the transcript, which is appended below. Only by watching the video, however, can you follow the waving of my hands.
I grabbed the transcript from the Y Combinator blog post, so you can read it there if you prefer, but I’ve corrected some of the typos. (There are a few references to questions and comments that were edited out, but that shouldn’t cause too much confusion.)
Here we go:
Craig Cannon [00:00:00] – Hey, how’s it going? This is Craig Cannon, and you’re listening to Y Combinator’s Podcast. Today’s episode is with John Preskill. John’s a theoretical physicist and the Richard P. Feynman Professor of Theoretical Physics at Caltech. He once won a bet with Stephen Hawking and he writes that it made him briefly almost famous. Basically, what happened is John and Kip Thorne bet that singularities could exist outside of black holes. After six years, Hawking conceded. He said that they were possible in very special, “non-generic conditions.” I’ll link up some more details to that in the description. In this episode, we cover what John’s been focusing on for years, which is quantum information, quantum computing, and quantum error correction. Alright, here we go. What was the revelation that made scientists and physicists think that a quantum computer could exist?
John Preskill [00:00:54] – It’s not obvious. A lot of people thought it couldn’t. The idea that a quantum computer would be powerful was emphasized over 30 years ago by Richard Feynman, the Caltech physicist. It was interesting how he came to that realization. Feynman was interested in computation his whole life. He had been involved during the war in Los Alamos. He was the head of the computation group. He was the guy who fixed the little mechanical calculators, and he had a whole crew of people who were calculating, and he figured out how to flow the work from one computer to another. All that kind of stuff. As computing technology started to evolve, he followed that. In the 1970s, a particle physicist like Feynman, that’s my background too, got really interested in using computers to study the properties of elementary particles like the quarks inside a nucleus, you know? We know a proton isn’t really a fundamental object. It’s got little beans rattling around inside, but they’re quantum beans. Gell-Mann, who’s good at names, called them quarks.
John Preskill [00:02:17] – Now we’ve had a theory since the 1970s of how quarks behave, and so in principle, you know everything about the theory, you can compute everything, but you can’t because it’s just too hard. People started to simulate that physics with digital computers in the ’70s, and there were some things that they could successfully compute, and some things they couldn’t because it was just too hard. The resources required, the memory, the time were out of reach. Feynman, in the early ’80s said nature is quantum mechanical damn it, so if you want a simulation of nature, it should be quantum mechanical. You should use a quantum system to behave like another quantum system. At the time, he called it a universal quantum simulator.
John Preskill [00:03:02] – Now we call it a quantum computer. The idea caught on about 10 years later when Peter Shor made the suggestion that we could solve problems which don’t seem to have anything to do with physics, which are really things about numbers like finding the prime factors of a big integer. That caused a lot of excitement, in part because the implications for cryptography are a big disturbing. But then physicists — good physicists — started to consider, can we really build this thing? Some concluded and argued fairly cogently that no, you couldn’t because of this difficulty that it’s so hard to isolate systems from the environment well enough for them to behave quantumly. It took a few years for that to sort out at the theoretical level. In the mid ’90s we developed a theory called quantum error correction. It’s about how to encode the quantum state that you’d like to protect in such a clever way that even if there are some interactions with the environment that you can’t control, it still stays robust.
John Preskill [00:04:17] – At first, that was just kind of a theorist’s fantasy — it was a little too far ahead of the technology. But 20 years later, the technology is catching up, and now this idea of quantum error correction has become something you can do in the lab.
Craig Cannon [00:04:31] – How does quantum error correction work? I’ve seen a bunch of diagrams, so maybe this is difficult to explain, but how would you explain it?
John Preskill [00:04:39] – Well, I would explain it this way. I don’t think I’ve said the word entanglement yet, have I?
Craig Cannon [00:04:43] – Well, I have been checking off all the Bingo words yet.
John Preskill [00:04:45] – Okay, so let’s talk about entanglement because it’s part of the answer to your question, which I’m still not done answering, what is quantum physics? What do we mean by entanglement? It’s really the characteristic way, maybe the most important way that we know in which quantum is different from ordinary stuff, from classical. Now what does it mean, entanglement? It means that you can have a physical system which has many parts, which have interacted with one another, so it’s in kind of a complex correlated state of all those parts, and when you look at the parts one at a time it doesn’t tell you anything about the state of the whole thing. The whole thing’s in some definite state — there’s information stored in it — and now you’d like to access that information … Let me be a little more concrete. Suppose it’s a book.
John Preskill [00:05:40] – Okay? It’s a book, it’s 100 pages long. If it’s an ordinary book, 100 people could each take a page, and read it, they know what’s on that page, and then they could get together and talk, and now they’d know everything that’s in the book, right? But if it’s a quantum book written in qubits where these pages are very highly entangled, there’s still a lot of information in the book, but you can’t read it the way I just described. You can look at the pages one at a time, but a single page when you look at it just gives you random gibberish. It doesn’t reveal anything about the content of the book. Why is that? There’s information in the book, but it’s not stored in the individual pages. It’s encoded almost entirely in how those pages are correlated with one another. That’s what we mean by quantum entanglement: Information stored in those correlations which you can’t see when you look at the parts one at a time. You asked about quantum error correction?
John Preskill [00:06:39] – What’s the basic idea? It’s to take advantage of that property of entanglement. Because let’s say you have a system of many particles. The environment is kind of kicking them around, it’s interacting with them. You can’t really completely turn off those interactions no matter how hard you try, but suppose we’ve encoded the information in entanglement. So, say, if you look at one atom, it’s not telling you anything about the information you’re trying to protect. The environment isn’t learning anything when it looks at the atoms one at a time.
John Preskill [00:07:15] – This is kind of the key thing — that what makes quantum information so fragile is that when you look at it, you disturb it. This ordinary water bottle isn’t like that. Let’s say we knew it was either here or here, and we didn’t know. I would look at it, I’d find out it’s here. I was ignorant of where it was to start with, and now I know. With a quantum system, when you look at it, you really change the state. There’s no way to avoid that. So if the environment is looking at it in the sense that information is leaking out to the environment, that’s going to mess it up. We have to encode the information so the environment, so to speak, can’t find out anything about what the information is, and that’s the idea of quantum error correction. If we encode it in entanglement, the environment is looking at the parts one at a time, but it doesn’t find out what the protected information is.
Craig Cannon [00:08:06] – In other words, it’s kind of measuring probability the whole way along, right?
John Preskill [00:08:12] – I’m not sure what you mean by that.
Craig Cannon [00:08:15] – Is it Grover’s algorithm that was as quantum bits roll through, go through gates– The probability is determined of what information’s being passed through? What’s being computed?
John Preskill [00:08:30] – Grover’s algorithm is a way of sort of doing an exhaustive search through many possibilities. Let’s say I’m trying to solve some problem like a famous one is the traveling salesman problem. I’ve told you what the distances are between all the pairs of cities, and now I want to find the shortest route I can that visits them all. That’s a really hard problem. It’s still hard for a quantum computer, but not quite as hard because there’s a way of solving it, which is to try all the different routes, and measure how long they are, and then find the one that’s shortest, and you’ve solved the problem. The reason it’s so hard to solve is there’s such a vast number of possible routes. Now what Grover’s algorithm does is it speeds up that exhaustive search.
John Preskill [00:09:29] – In practice, it’s not that big a deal. What it means is that if you had the same processing speed, you can handle about twice as many cities before the problem becomes too hard to solve, as you could if you were using a classical processor. As far as what’s quantum about Grover, it takes advantage of the property in quantum physics that probabilities … tell me if I’m getting too inside baseball …
Craig Cannon [00:10:03] – No, no, this is perfect.
John Preskill [00:10:05] – That probabilities are the squares of amplitudes. This is interference. Again, this is another part of the answer. Well, we can spend the whole hour answering the question, what is quantum physics? Another essential part of it is what we call interference, and this is really crucial for understanding how quantum computing works. That is that probabilities add. If you know the probability of one alternative, and you know the probability of another, then you can add those together and find the probability that one or the other occurred. It’s not like that in quantum physics. The famous example is the double slit interference experiment. I’m sending electrons, let’s say — it could be basketballs, but it’s an easier experiment to do with electrons —
John Preskill [00:11:02] – at a screen, and there are two holes in the screen. You can try to detect the electron on the other side of the screen, and when you do that experiment many times, you can plot a graph showing where the electron was detected in each run, or make a histogram of all the different outcomes. And the graph wiggles, okay? If you could say there’s some probability of going through the first hole, and some probability of going through the second, and each time you detected it, it went through either one or the other, there’d be no wiggles in that graph. It’s the interference that makes it wiggle. The essence of the interference is that nobody can tell you whether it went through the first slit or the second slit. The question is sort of inadmissible. This interference then occurs when we can add up these different alternatives in a way which is different from what we’re used to. It’s not right to say that the electron was detected at this point because it had some probability of going through the first hole, and some probability of going through the second
John Preskill [00:12:23] – and we add those probabilities up. That doesn’t give the right answer. The different alternatives can interfere. This is really important for quantum computing because what we’re trying to do is enhance the probability or the time it takes to find the solution to a problem, and this interference can work to our advantage. We want to have, when we’re doing our search, we want to have a higher chance of getting the right answer, and a lower chance of getting the wrong answer. If the different wrong answers can interfere, they can cancel one another out, and that enhances the probability of getting the right answer. Sorry it’s such a long-winded answer, but this is how Grover’s algorithm works.
John Preskill [00:13:17] – It can speed up exhaustive search by taking advantage of that interference phenomenon.
Craig Cannon [00:13:20] – Well this is kind of one of the underlying questions among many of the questions from Twitter. You’ve hit our record for most questions asked. Basically, many people are wondering what quantum computers really will do if and when it becomes a reality that they outperform classical computers. What are they going to be really good at?
John Preskill [00:13:44] – Well, you know what? I’m not really sure. If you look at the history of technology, it would be hubris to expect me to know. It’s a whole different way of dealing with information. Quantum information is not just … a quantum computer is not just a faster way of computing. It deals with information in a completely new way because of this interference phenomenon, because of entanglement that we’ve talked about. We have limited vision when it comes to predicting decades out what the impact will be of an entirely new way of doing things. Information processing, in particular. I mean you know this well. We go back to the 1960s, and people are starting to put a few transistors on a chip. Where is that going to lead? Nobody knew.
Craig Cannon [00:14:44] – Even early days of the internet.
John Preskill [00:14:45] – Yeah, good example.
Craig Cannon [00:14:46] – Even the first browser. No one really knew what anyone was going to do with it. It makes total sense.
John Preskill [00:14:52] – For good or ill. Yeah. But we have some ideas, you know? I think … why are we confident there will be some transformative effect on society? Of the things we know about, and I emphasize again, probably the most important ones are things we haven’t thought of when it comes to applications of quantum computing, the ones which will affect everyday life, I think, are better methods for understanding and inventing new materials, new chemical compounds. Things like that can be really important. If you find a better way of capturing carbon by designing a better catalyst, or you can design pharmaceuticals that have new effects, materials that have unusual properties. These are quantum physics problems because those properties of the molecule or the material really have to do with the underlying quantum behavior of the particles, and we don’t have a good way for solving such problems or predicting that behavior using ordinary digital computers. That’s what a quantum computer is good at. It’s good — but maybe not the only thing it’s good at — one thing it should certainly be good at is telling us quantitatively how quantum systems behave. In the two contexts I just mentioned, there’s little question that there will be practical impact of that.
Craig Cannon [00:16:37] – It’s not just doing the traveling salesman problem through the table of elements for why it can find these compounds.
John Preskill [00:16:49] – No. If it were, that wouldn’t be very efficient.
Craig Cannon [00:16:52] – Exactly.
John Preskill [00:16:53] – Yeah. No, it’s much trickier than that. Like I said, the exhaustive search, though conceptually it’s really interesting that quantum can speed it up because of interference, from a practical point of view it may not be that big a deal. It means that, well like I said, in the same amount of time you can solve an instance which is twice as big of the problem. What we really get excited about are the so-called exponential speed ups. That was why Shor’s algorithm was exciting in 1994, because factoring large numbers was a problem that had been studied by smart people for a long time, and on that basis, the fact that there weren’t any fast ways of solving it was pretty good evidence it’s a hard problem. Actually, we don’t know how to prove that from first principles. Maybe somebody will come along one day and figure out how to solve factoring very fast on a digital computer. It doesn’t seem very likely because people have been trying for so long to solve problems like that, and it’s just intractable with ordinary computers. You could say the same thing about these quantum physics problems. Maybe some brilliant graduate student is going to drop a paper on the arXiv tomorrow which will say, “Here, I solved quantum chemistry, and I can do it on a digital computer.” But we don’t think that’s very likely because we’ve been working pretty hard on these problems for decades and they seem to be really hard. Those cases, like these number theoretic problems,
John Preskill [00:18:40] – which have cryptological implications, and tasks for simulating the behavior of quantum systems, we’re pretty sure those are hard problems classically, and we’re pretty sure quantum computers … I mean we have algorithms that have been proposed, but which we can’t really run currently because our quantum computers aren’t big enough on the scale that’s needed to solve problems people really care about.
Craig Cannon [00:19:09] – Maybe we should jump to one of the questions from Twitter which is related to that. Travis Scholten (@Travis_Sch) asked, what are the most problem pressings in physics, let’s say specifically around quantum computers that you think substantial progress ought to be made in to move the field forward?
John Preskill [00:19:27] – I know Travis. He was an undergrad here. How you doing, Travis? The problems that we need to solve to make quantum computing closer to realization at the level that would solve problems people care about? Well, let’s go over where we are now.
Craig Cannon [00:19:50] – Yeah, definitely.
John Preskill [00:19:51] – People have been working on quantum hardware for 20 years, working hard, and there are a number of different approaches to building the hardware, and nobody really knows which is going to be the best. I think we’re far from collapsing to one approach which everybody agrees has the best long-term prospects for scalability. And so it’s important that a lot of different types of hardware are being pursued. We can come back to what some of the different approaches are later. Where are we now? We think in a couple of years we’ll have devices with about 50 qubits to 100, and we’ll be able to control them pretty well. That’s an interesting range because even though it’s only 50 to 100 qubits, doesn’t sound like that big a deal, but that’s already too many to simulate with a digital computer, even with the most powerful supercomputers today. From that point of view, these relatively small, near-term quantum computers which we’ll be fooling around with over the next five years or so, are doing something that’s kind of super-classical.
John Preskill [00:21:14] – At least, we don’t know how to do exactly the same things with ordinary computers. Now that doesn’t mean they’ll be able to do anything that’s practically important, but we’re going to try. We’re going to try, and there are ideas about things we’ll try out, including baby versions of these problems in chemistry, and materials, and ways of speeding up optimization problems. Nobody knows how well those things are going to work at these small scales. Part of the reason is not just the number of qubits is small, but they’re also not perfect. We can perform elementary operations on pairs of qubits, which we call quantum gates like the gates in ordinary logic. But they have an error rate a little bit below an error every 100 gates. If you have a circuit with 1000 qubits, that’s a lot of noise.
Craig Cannon [00:22:18] – Exactly. Does for instance, 100-qubit quantum computer really mean 100-qubit quantum computer or do you need a certain amount of backup going on?
John Preskill [00:22:29] – In the near term, we’re going to be trying out, and probably we have the best hopes for, kind of hybrid classical-quantum methods with some kind of classical feedback. You try to do something on the quantum computer, you make a measurement that gives you some information, then you change the way you did it a little bit, and try to converge on some better answer. That’s one possible way of addressing optimization that might be faster on a quantum computer. But I just wanted to emphasize that the number of qubits isn’t the only metric. How good they are, and in particular, the reliability of the gates, how well we can perform them … that’s equally important. Anyway, coming back to Travis’ question, there are lots of things that we’d like to be able to do better. But just having much better qubits would be huge, right? If you … more or less, with the technology we have now, you can have a gate error rate of a few parts in 1,000, you know? If you can improve that by orders of magnitude, then obviously, you could run bigger circuits. That would be very enabling.
John Preskill [00:23:58] – Even if you stick with 100 qubits just by having a circuit with more depth, more layers of gates, that increases the range of what you could do. That’s always going to be important. Because, I mean look at how crappy that is. A gate error rate, even if it’s one part in 1,000, that’s pretty lousy compared to if you look at where–
Craig Cannon [00:24:21] – Your phone has a billion transistors in it. Something like that, and 0%–
John Preskill [00:24:27] – You don’t worry about the … it’s gotten to the point where there is some error protection built in at the hardware level in a processor, because I mean, we’re doing these crazy things like going down from the 11 nanometer scale for features on a chip.
Craig Cannon [00:24:45] – How are folks trying to deal with interference right now?
John Preskill [00:24:50] – You mean, what types of devices? Yeah, so that’s interesting too because there are a range of different ways to do it. I mentioned that we could store information, we could make a qubit out of a single atom, for example. That’s one approach. You have to control a whole bunch of atoms and get them to interact with one another. One way of doing that is with what we call trapped ions. That means the atoms have electrical charges. That’s a good thing because then you could control them with electric fields. You could hold them in a trap, and you can isolate them, like I said, in a very high vacuum so they’re not interacting too much with other things in the laboratory, including stray electric and magnetic fields. But that’s not enough because you got to get them to talk to one another. You got to get them to interact. We have this set of desiderata, which are kind of in tension with one another. On the one hand, we want to isolate the qubits very well. On the other hand, we want to control them from the outside and get them to do what we want them to do, and eventually, we want to read them out. You have to be able to read out the result of the computation. But the key thing is the control. You could have two of those qubits in your device interact with one another in a specified way, and to do that very accurately you have to have some kind of bus that gets the two to talk to one another.
John Preskill [00:26:23] – The way they do that in an ion trap is pretty interesting. It’s by using lasers and controlling how the ions vibrate in the trap, and with a laser, kind of excite, wiggles of the ion, and then by determining whether the ions are wiggling or not, you can go address another ion, and that way you can do a two-qubit interaction. You can do that pretty well. Another way is really completely different. What I just described was encoding information at the one atom level. But another way is to use superconductivity — circuits in which electric current flows without any dissipation. In that case, you have a lot of freedom to sort of engineer the circuits to behave in a quantum way. There are many nuances there, but the key thing is that you can encode information now in a system that might involve the collective motion of billions of electrons, and yet you can control it as though it were a single atom. I mean, here’s one oversimplified way of thinking about it.
John Preskill [00:27:42] – Suppose you have a little loop of wire, and there’s current flowing in the loop. It’s a superconducting wire so it just keeps flowing. Normally, there’d be resistance, which would dissipate that as heat, but not for the superconducting circuit, which of course, has to be kept very cold so it stays superconducting. But you can imagine in this little loop that the current is either circulating clockwise or counterclockwise. That’s a way of encoding information. It could also be both at once, and that’s what makes it a qubit.
Craig Cannon [00:28:14] – Right.
John Preskill [00:28:15] – And so in that case, even though it involves lots of particles, the magic is that you can control that system extremely well. I mentioned individual electrons. That’s another approach. Put the qubit in the spin of a single electron.
Craig Cannon [00:28:32] – You also mentioned better qubits. What did you mean by that?
John Preskill [00:28:35] – Well, what I really care about is how well I can do the gates. There’s a whole other approach, which is motivated by the desire to have much, much better control over the quantum information than we do in those systems that I mentioned so far, superconducting circuits and trapped ions. That’s actually what Microsoft is pushing very hard. We call it topological quantum computing. Topological is a word physicists and mathematicians love. It means, well, we’ll come back to what it means. Anyway, let me just tell you what they’re trying to do. They’re trying to make a much, much better qubit, which they can control much, much better using a completely different hardware approach.
Craig Cannon [00:29:30] – Okay.
John Preskill [00:29:32] – It’s very ambitious because at this point, it’s not even clear they have a single qubit, but if that approach is successful, and it’s making progress, we will see a validated qubit of this type soon. Maybe next year. Nobody really knows where it goes from there, but suppose it’s the case that you could do a two-qubit gate with an error rate of one in a million instead of one in 1,000. That would be huge. Now, scaling all these technologies up, is really challenging from a number of perspectives, including just the control engineering.
Craig Cannon [00:30:17] – How are they doing it or attempting to do it?
John Preskill [00:30:21] – You know, you could ask, where did all this progress come from over 20 years, or so? For example, with the superconducting circuits, a sort of crucial measure is what we call the coherence time of the qubit, which roughly speaking, means how much it interacts with the outside world. The longer the coherence time, the better. The rate of what we call decoherence is essentially how much it’s getting buffeted around by outside influences. For the superconducting circuits, those coherence times have increased about a factor of 10 every three years, going back 15 years or so.
Craig Cannon [00:31:06] – Wow.
John Preskill [00:31:07] – Now, it won’t necessarily go on like that indefinitely, but in order to achieve that type of progress, better materials, better fabrication, better control. The way you control these things is with microwave circuitry. Not that different from the kind of things that are going on in communication devices. All those things are important, but going forward, the control is really the critical thing. Coherence times are already getting pretty long, I mean having them longer is certainly good. But the key thing is to get two qubits to interact just the way you want them to. Even if there is, now I keep saying the key thing is the environment, it’s not the only key thing, right? Because you have some qubit, like if you think about that electron spin, one way of saying it is I said it can be both up and down at the same time. Well, there’s a simpler way of saying that. It might not point either up or down. It might point some other way. But there really are a continuum of ways it could point. That’s not like a bit. See, it’s much easier to stabilize a bit because it’s got two states.
John Preskill [00:32:31] – But if it can kind of wander around in the space of possible configurations for a qubit, that makes it much harder to control. People have gotten better at that, a lot better at that in the last few years.
Craig Cannon [00:32:44] – Interesting. Joshua Harmon asked, what engineering strategy for quantum computers do you think has the most promise?
John Preskill [00:32:53] – Yeah, so I mentioned some of these different approaches, and I guess I’ll interpret the question as, which one is the winning horse? I know better than to answer that question! They’re all interesting. For the near term, the most advanced are superconducting circuits and trapped ions, which is why I mentioned those first. I think that will remain true over the next five to 10 years. Other technologies have the potential — like these topologically protected qubits — to surpass those, but it’s not going to happen real soon. I kind of like superconducting circuits because there’s so much phase space of things you can do with them. Of ways you can engineer and configure them, and imagine scaling them up.
John Preskill [00:33:54] – They have the advantage of being faster. The cycle time, time to do a gate, is faster than with the trapped ions. Just the basic physics of the interactions is different. In the long term, those electron spins could catapult ahead of these other things. That’s something that you can naturally do in silicon, and it’s potentially easy to integrate with silicon technology. Right now, the qubits and gates aren’t as good as the other technologies, but that can change. I mean, from a theorist’s perspective, this topological approach is very appealing. We can imagine it takes off maybe 10 years from now and it becomes the leader. I think it’s important to emphasize we don’t really know what’s going to scale the best.
Craig Cannon [00:34:50] – Right. And are there multiple attempts being made around programming quantum computers?
John Preskill [00:34:55] – Yeah. I mean, some of these companies– That are working on quantum technology now, which includes well-known big players like IBM, and Google, and Microsoft and Intel, but also a lot of startups now. They are trying to encompass the full stack, so they’re interested in the hardware, and the fabrication, and the control technology. But also, the software, the applications, the user interface. All those things are certainly going to be important eventually.
Craig Cannon [00:35:38] – Yeah, they’re pushing it almost to like an AWS layer. Where you interact with your quantum computer in a server farm and you don’t even touch it.
John Preskill [00:35:49] – That’s how it will be in the near term. You’re not going to have, most of us won’t, have a quantum computer sitting on your desktop, or in your pocket. Maybe someday. In the near term, it’ll be in the Cloud, and you’ll be able to run applications on it by some kind of web interface. Ideally, that should be designed so the user doesn’t have to know anything about quantum physics in order to program or use it, and I think that’s part of what some of these companies are moving toward.
Craig Cannon [00:36:24] – Do you think it will get to the level where it’s in your pocket? How do you deal with that when you’re below one kelvin?
John Preskill [00:36:32] – Well, if it’s in your pocket, it probably won’t be one kelvin.
Craig Cannon [00:36:35] – Yeah, probably not.
John Preskill [00:36:38] – What do you do? Well, there’s one approach, as an example, which I guess I mentioned in passing before, where maybe it doesn’t have to be at such low temperature, and that’s nuclear spins. Because they’re very weakly interacting with the outside world, you can have quantum information in a nuclear spin, which — I’m not saying that it would be undisturbed for years, but seconds, which is pretty good. And you can imagine that getting significantly longer. Someday you might have a little quantum smart card in your pocket. The nice thing about that particular technology is you could do it at room temperature. Still have long coherence times. If you go to the ATM and you’re worried that there’s a rogue bank that’s going to steal your information, one solution to that problem — I’m not saying there aren’t other solutions — is to have a quantum card where the bank will be able to authenticate it without being able to forge it.
Craig Cannon [00:37:54] – We should talk about the security element. Kevin Su asked what risk would quantum computers pose to current encryption schemes? So public key, and what changes should people be thinking about if quantum computers come in the next five years, 10 years?
John Preskill [00:38:12] – Yeah. Quantum computers threaten those systems that are in widespread use. Whenever you’re using a web browser and you see that little padlock and you’re at an HTTPS site, you’re using a public key cryptosystem to protect your privacy. Those cryptosystems rely for their security on the presumed hardness of computational problems. That is, it’s possible to crack them, but it’s just too hard. RSA, which is one of the ones that’s widely used … as typically practiced today, to break it you’d have to do something like factor a number which is over 2000 bits long, 2048. That’s too hard to do now. But that’s what quantum computers will be good at. Another one that’s widely used is called elliptic curve cryptography. Doesn’t really matter exactly what it is.
John Preskill [00:39:24] – But the point is that it’s also vulnerable to quantum attack, so we’re going to have to protect our privacy in different ways when quantum computers are prevalent.
Craig Cannon [00:39:37] – What are the attempts being made right now?
John Preskill [00:39:39] – There are two main classes of attempts. One is just to come up with a cryptographic protocol not so different conceptually from what’s done now, but based on a problem that’s hard for quantum computers.
Craig Cannon [00:39:59] – There you go.
John Preskill [00:40:02] – It turns out that what has sort of become the standard way doesn’t have that feature, and there are alternatives that people are working on. We speak of post-quantum cryptography, meaning the protocols that we’ll have to use when we’re worried that our adversaries have quantum computers. I don’t think there’s any proposed cryptosystem — although there’s a long list of them by now which people think are candidates for being quantum resistant, for being unbreakable, or hard to break by quantum computers. I don’t think there’s any one that the world has sufficient confidence in now that’s really hard for a quantum adversary that we’re all going to switch over. But it’s certainly time to be thinking about it. When people worry about their privacy, of course different users have different standards, but the US Government sometimes says they would like a system to stay secure for 50 years. They’d like to be able to use it for 20, roughly speaking, and then have the intercepted traffic be protected for another 30 after that. I don’t think, though I could be wrong, that we’re likely to have quantum computers that can break those public key cryptosystems in 10 years, but in 50 years seems not unlikely,
John Preskill [00:41:33] – and so we should really be worrying about it. The other one is actually using quantum communication for privacy. In other words, if you and I could send qubits to one another instead of bits, it opens up new possibilities. The way to think about these public key schemes — or one way — that we’re using now, is I want you to send me a private message, and I can send you a lockbox. It has a padlock on it, but I keep the key, okay? But you can close up the box and send it to me. But I’m the only one with the key. The key thing is that if you have the padlock you can’t reverse engineer the key. Of course, it’s a digital box and key, but that’s the idea of public key. The idea of what we call quantum key distribution, which is a particular type of quantum cryptography, is that I can actually send you the key, or you can send me your key, but why can’t any eavesdropper then listen in and know the key? Well it’s because it’s quantum, and remember, it has that property that if you look at it, you disturb it.
John Preskill [00:42:59] – So if you collect information about my key, or if the adversary does, that will cause some change in the key, and there are ways in which we can check whether what you received is really what I sent. And if it turns out it’s not, or it has too many errors in it, then we’ll be suspicious that there was an adversary who tampered with it, and then we won’t use that key. Because we haven’t used it yet — we’re just trying to establish the key. We do the test to see whether an adversary interfered. If it passes the test, then we can use the key. And if it fails the test, we throw that key away and we try again. That’s how quantum cryptography works, but it requires a much different infrastructure than what we’re using now. We have to be able to send qubits … well, it’s not completely different because you can do it with photons. Of course, that’s how we communicate through optical fiber now — we’re sending photons. It’s a little trickier sending quantum information through an optical fiber, because of that issue that interactions with the environment can disturb it. But nowadays, you can send quantum information through an optical fiber over tens of kilometers with a low enough error rate so it’s useful for communication.
Craig Cannon [00:44:22] – Wow.
John Preskill [00:44:23] – Of course, we’d like to be able to scale that up to global distances.
Craig Cannon [00:44:26] – Sure.
John Preskill [00:44:27] – And there are big challenges in that. But anyway, so that’s another approach to the future of privacy that people are interested in.
Craig Cannon [00:44:35] – Does that necessitate quantum computers on both ends?
John Preskill [00:44:38] – Yes, but not huge ones. The reason … well, yes and no. At the scale of tens of kilometers, no. You can do that now. There are prototype systems that are in existence. But if you really want to scale it up — in other words, to send things longer distance — then you have to bring this quantum error correction idea into the game.
John Preskill [00:45:10] – Because at least with our current photonics technology, there’s no way I can send a single photon from here to China without there being a very high probability that it gets lost in the fiber somewhere. We have to have what we call quantum repeaters, which can boost the signal. But it’s not like the usual type of repeater that we have in communication networks now. The usual type is you measure the signal, and then you resend it. That won’t work for quantum because as soon as you measure it you’re going to mess it up. You have to find a way of boosting it without knowing what it is. Of course, it’s important that it works that way because otherwise, the adversary could just intercept it and resend it. And so it will require some quantum processing to get that quantum error correction in the quantum repeater to work. But it’s a much more modest scale quantum processor than we would need to solve hard problems.
Craig Cannon [00:46:14] – Okay. Gotcha. What are the other things you’re both excited about, and worried about for potential business opportunities? Snehan, I’m mispronouncing names all the times, Snehan Kekre asks, budding entrepreneurs, what should they be thinking about in the context of quantum computing?
John Preskill [00:46:37] – There’s more to quantum technology than computing. Something which has good potential to have an impact in the relatively near future is improved sensing. Quantum systems, partly because of that property that I keep emphasizing that they can’t be perfectly isolated from the outside, they’re good at sensing things. Sometimes, you want to detect it when something in the outside world messes around with your qubit. Again, using this technology of nuclear spins, which I mentioned you can do at room temperature potentially, you can make a pretty good sensor, and it can potentially achieve higher sensitivity and spatial resolution, look at things on shorter distance scales than other existing sensing technology. One of the things people are excited about are the biological and medical implications of that.
John Preskill [00:47:53] – If you can monitor the behavior of molecular machines, probe biological systems at the molecular level using very powerful sensors, that would surely have a lot of applications. One interesting question you can ask is, can you use these quantum error correction ideas to make those sensors even more powerful? That’s another area of current basic research, where you could see significant potential economic impact.
Craig Cannon [00:48:29] – Interesting. In terms of your research right now, what are you working on that you find both interesting and incredibly difficult?
John Preskill [00:48:40] – Everything I work on–
Craig Cannon [00:48:41] – 100%.
John Preskill [00:48:42] – Is both interesting and incredibly difficult. Well, let me change direction a little from what we’ve been talking about so far. Well, I’m going to tell you a little bit about me.
Craig Cannon [00:48:58] – Sure.
John Preskill [00:49:00] – I didn’t start out interested in information in my career. I’m a physicist. I was trained as an elementary particle theorist, studying the fundamental interactions and the elementary particles. That drew me into an interest in gravitation because one thing that we still have a very poor understanding of is how gravity fits together with the other fundamental interactions. The way physicists usually say it is we don’t have a quantum theory of gravity, at least not one that we think is complete and satisfactory. I’ve been interested in that question for many decades, and then got sidetracked because I got excited about quantum computing. But you know what? I’ve always looked at quantum information not just as a technology. I’m a physicist, I’m not an engineer. I’m not trying to build a better computer, necessarily, though that’s very exciting, and worth doing, and if my work can contribute to that, that’s very pleasing. I see quantum information as a new frontier in the exploration of the physical sciences. Sometimes I call it the entanglement frontier. Physicists, we like to talk about frontiers, and stuff. Short distance frontier. That’s what we’re doing at CERN in the Large Hadron Collider, trying to discern new properties of matter at distances which are shorter than we’ve ever been able to explore before.
John Preskill [00:50:57] – There’s a long distance frontier in cosmology. We’re trying to look deeper into the universe and understand its structure and behavior at earlier times. Those are both very exciting frontiers. This entanglement frontier is increasingly going to be at the forefront of basic physics research in the 21st century. By entanglement frontier, I just mean scaling up quantum systems to larger and larger complexity where it becomes harder and harder to simulate those systems with our existing digital tools. That means we can’t very well anticipate the types of behavior that we’re going to see. That’s a great opportunity for new discovery, and that’s part of what’s going to be exciting even in the relatively near term. When we have 100 qubits … there are some things that we can do to understand the behavior of the dynamics of a highly complex system of 100 qubits that we’ve never been able to experimentally probe before. That’s going to be very interesting. But what we’re starting to see now is that these quantum information ideas are connecting to these fundamental questions about gravitation, and how to think about it quantumly. And it turns out, as is true for most of the broader implications of quantum physics, the key thing is entanglement.
John Preskill [00:52:36] – We can think of the microscopic structure of spacetime, the geometry of where we live. Geometry just means who’s close to who else. If we’re in the auditorium, and I’m in the first row and you’re in the fourth row, the geometry is how close we are to one another. Of course, that’s very fundamental in both space and time. How far apart are we in space? How far apart are we in time? Is geometry really a fundamental thing, or is it something that’s kind of emergent from some even more fundamental concept? It seems increasingly likely that it’s really an emergent property.
John Preskill [00:53:29] – That there’s something deeper than geometry. What is it? We think it’s quantum entanglement. That you can think of the geometry as arising from quantum correlations among parts of a system. That’s really what defines who’s close to who. We’re trying to explore that idea more deeply, and one of the things that comes in is the idea of quantum error correction. Remember the whole idea of quantum error correction was that we could make a quantum system behave the way we want it to because it’s well-protected against the damaging effects of noise. It seems like quantum error correction is part of the deep secret of how spacetime geometry works. It has a kind of intrinsic robustness coming from these ideas of quantum error correction that makes space meaningful, so that it doesn’t just evaporate when you tap on it. If you wanted to, you could think of the spacetime, the space that you’re in and the space that I’m in, as parts of a system that are entangled with one another.
John Preskill [00:54:45] – What would happen if we broke that entanglement and your part of space became disentangled from my part? Well what we think that would mean is that there’d be no way to connect us anymore. There wouldn’t be any path through space that starts over here with me and ends with you. It’d become broken apart into two pieces. It’s really the entanglement which holds space together, which keeps it from falling apart into little pieces. We’re trying to get a deeper grasp of what that means.
Craig Cannon [00:55:19] – How do you make any progress on that? That seems like the most unbelievably difficult problem to work on.
John Preskill [00:55:26] – It’s difficult because, well for a number of reasons, but in particular, because it’s hard to get guidance from experiment, which is how physics historically–
Craig Cannon [00:55:38] – All science.
John Preskill [00:55:38] – Has advanced.
Craig Cannon [00:55:39] – Yeah.
John Preskill [00:55:41] – Although it was fun a moment ago to talk about what would happen if we disentangled your part of space from mine, I don’t know how to do that in the lab right now. Of course, part of the reason is we have the audacity to think we can figure these things out just by thinking about them. Maybe that’s not true. Nobody knows, right? We should try. Solving these problems is a great challenge, and it may be that the apes that evolved on Earth don’t have the capacity to understand things like the quantum structure of spacetime. But maybe we do, so we should try. Now in the longer term, and maybe not such a long term, maybe we can get some guidance from experiment. In particular, what we’re going to be doing with quantum computers and the other quantum technologies that are becoming increasingly sophisticated in the next couple of decades, is we’ll be able to control very well highly entangled complex quantum systems. That should mean that in a laboratory, on a tabletop, I can sort of make my own little toy space time …
John Preskill [00:57:02] – with an emergent geometry arising from the properties of that entanglement, and I think that’ll teach us lessons because systems like that are the types of system that, because they’re so highly entangled, digital computers can’t simulate them. It seems like only quantum computers are potentially up to the task. So that won’t be quite the same as disentangling your side of the room from mine, in real life. But we’d be able to do it in a laboratory setting using model systems, which I think would help us to understand the basic principles better.
Craig Cannon [00:57:39] – Wild. Yeah, desktop space time seems pretty cool, if you could figure it out.
John Preskill [00:57:43] – Yeah, it’s pretty fundamental. We didn’t really talk about what people sometimes, we did implicitly, but not in so many words. We didn’t talk about what people sometimes call quantum non-locality. It’s another way of describing quantum entanglement, actually. There’s this notion of Bell’s theorem that when you look at the correlations among the parts of a quantum system, that they’re different from any possible classical correlations. Some things that you read give you the impression that you can use that to instantaneously send information over long distances. It is true that if we have two qubits, electron spins, say, and they’re entangled with one another, then what’s kind of remarkable is that I can measure my qubit to see along some axis whether it’s up or down, and you can measure yours, and we will get perfectly correlated results. When I see up, you’ll see up, say, and when I see down, you’ll see down. And sometimes, people make it sound like that’s remarkable. That’s not remarkable in itself. Somebody could’ve flipped a pair of coins, you know,
John Preskill [00:59:17] – so that they came up both heads or both tails, and given one to you and one –
Craig Cannon [00:59:20] – Split them apart.
John Preskill [00:59:20] – to me.
Craig Cannon [00:59:21] – Yeah.
John Preskill [00:59:22] – And gone a light year apart, and then we both … hey, mine’s heads. Mine’s heads too!
Craig Cannon [00:59:24] – And then they call it quantum teleportation on YouTube.
John Preskill [00:59:28] – Yeah. Of course, what’s really important about entanglement that makes it different from just those coins is that there’s more than one way of looking at a qubit. We have what we call complementary ways of measuring it, so you can ask whether it’s up or down along this axis or along that axis. There’s nothing like that for the coins. There’s just one way to look at it. What’s cool about entanglement is that we’ll get perfectly correlated results if we both measure in the same way, but there’s more than one possible way that we could measure. What sometimes gets said, or the impression people get, is that that means that when I do something to my qubit, it instantaneously affects your qubit, even if we’re on different sides of the galaxy. But that’s not what entanglement does. It just means they’re correlated in a certain way.
John Preskill [01:00:30] – When you look at yours, if we have maximally entangled qubits, you just see a random bit. It could be a zero or a one, each occurring with probability 1/2. That’s going to be true no matter what I did to my qubit, and so you can’t tell what I did by just looking at it. It’s only that if we compared notes later we can see how they’re correlated, and that correlation holds for either one of these two complementary ways in which we could both measure. It’s that fact that we have these complementary ways to measure that makes it impossible for a classical system to reproduce those same correlations. So that’s one misconception that’s pretty widespread. Another one is this about quantum computing, which is in trying to explain why quantum computers are powerful, people will sometimes say, well, it’s because you can superpose –I used that word before, you can add together many different possibilities. That means that, whereas an ordinary computer would just do a computation once, acting on a superposition a quantum computer can do a vast number of computations all at once.
John Preskill [01:01:54] – There’s a certain sense in which that’s mathematically true if you interpret it right, but it’s very misleading. Because in the end, you’re going to have to make some measurement to read out the result. When you read it out, there’s a limited amount of information you can get. You’re not going to be able to read out the results of some huge number of computations in a single shot measurement. Really the key thing that makes it work is this idea of interference, which we discussed briefly when you asked about Grover’s algorithm. The art of a quantum algorithm is to make sure that the wrong answers interfere and cancel one another out, so the right answer is enhanced. That’s not automatic. It requires that the quantum algorithm be designed in just the right way.
Craig Cannon [01:02:50] – Right. The diagrams I’ve seen online at least, involve usually you’re squaring the output as it goes along, and then essentially, that flips the correct answer to the positive, and the others are in the negative position. Is that accurate?
John Preskill [01:03:08] – I wouldn’t have said it the way you did– Because you can’t really measure it as you go along. Once you measure it, the magic of superposition is going to be lost.
John Preskill [01:03:19] – It means that now there’s some definite outcome or state. To take advantage of this interference phenomenon, you need to delay the measurement. Remember when we were talking about the double slit and I said, if you actually see these wiggles in the probability of detection, which is the signal of interference, that means that there’s no way anybody could know whether the electron went through hole one or hole two? It’s the same way with quantum computing. If you think of the computation as being a superposition of different possible computations, it wouldn’t work — there wouldn’t be a speed up — if you could know which of those paths the computation followed. It’s important that you don’t know. And so you have to sum up all the different computations, and that’s how the interference phenomenon comes into play.
Craig Cannon [01:04:17] – To take a little sidetrack, you mentioned Feynman before. And before we started recording you mentioned working with him. I know I’m in the Feynman fan club, for sure. What was that experience like?
John Preskill [01:04:32] – We never really collaborated. I mean, we didn’t write a paper together, or anything like that. We overlapped for five years at Caltech. I arrived here in 1983. He died in 1988. We had offices on the same corridor, and we talked pretty often because we were both interested in the fundamental interactions, and in particular, what we call quantum chromodynamics. It’s our theory of how nuclear matter behaves, how quarks interact, what holds the proton together, those kinds of things. One big question is what does hold the proton together? Why don’t the quarks just fall apart? That was an example of a problem that both he and I were very interested in, and which we talked about sometimes. Now, this was pretty late in his career. When I think about it now, when I arrived at Caltech, that was 1983, Feynman was born in 1918, so he was 65. I’m 64 now, so maybe he wasn’t so old, right? But at the time, he seemed pretty ancient to me. Since I was 30.
John Preskill [01:05:58] – Those who interacted with Dick Feynman when he was really at his intellectual peak in the ’40s, and ’50s, and ’60s, probably saw even more extraordinary intellectual feats than I witnessed interacting with the 65 year old Feynman. He just loved physics, you know? He just thought everything was so much fun. He loved talking about it. He wasn’t as good a listener as a talker, but actually – well that’s a little unfair, isn’t it? It was kind of funny because Feynman, he always wanted to think things through for himself, sort of from first principles, rather than rely on the guidance from experts who have thought about these things before. Well that’s fine. You should try to understand things as deeply as you can on your own, and sort of reconstruct the knowledge from the ground up. That’s very enabling, and gives you new insights. But he was a little too dismissive, in my view, of what the other guys knew. But I could slip it in because I didn’t tell him, “Dick, you should read this paper by Polyakov” — well maybe I did, but he wouldn’t have even heard that — because he solved that problem that you’re talking about.
John Preskill [01:07:39] – But I knew what Polyakov had said about it, so I would say, “Oh well, look, why don’t we look at it this way?” And so he thought I was, that I was having all these insights, but the truth was the big difference between Feynman and me in the mid 1980s was I was reading literature, and he wasn’t.
Craig Cannon [01:08:00] – That’s funny.
John Preskill [01:08:01] – Probably, if he had been, he would’ve been well served, but that wasn’t the way he liked to work on things. He wanted to find his own approach. Of course, that had worked out pretty well for him throughout his career.
Craig Cannon [01:08:15] – What other qualities did you notice about him when he was roaming the corridors?
John Preskill [01:08:21] – He’d always be drumming. So you would know he was around because he’d actually be walking down the hallway drumming on the wall.
Craig Cannon [01:08:27] – Wait, with his hands, or with sticks, or–
John Preskill [01:08:29] – No, hands. He’d just be tapping.
Craig Cannon [01:08:32] – Just a bongo thing.
John Preskill [01:08:33] – Yeah. That was one thing. He loved to tell stories. You’ve probably read the books that Ralph Leighton put together based on the stories Feynman told. Ralph did an amazing job, of capturing Feynman’s personality in writing those stories down because I’d heard a lot of them. I’m sure he told the same stories to many people many times, because he loved telling stories. But the book really captures his voice pretty well.
John Preskill [01:09:12] – If you had heard him tell some of these stories, and then you read the way Ralph Leighton transcribed them, you can hear Feynman talking. At the time that I knew him, one of the experiences that he went through was he was on the Challenger commission after the space shuttle blew up. He was in Washington a lot of the time, but he’d come back from time to time, and he would sort of sit back and relax in our seminar room and start bringing us up to date on all the weird things that were happening on the Challenger commission. That was pretty fun.
Craig Cannon [01:09:56] – That’s really cool.
John Preskill [01:09:56] – A lot of that got captured in the second volume. I guess it’s the one called, What Do You Care What Other People Think? There’s a chapter about him telling stories about the Challenger commission. He was interested in everything. It wasn’t just physics. He was very interested in biology. He was interested in computation. I remember how excited he was when he got his first IBM PC. Probably not long after I got to Caltech. Yeah, it was what they called the AT. We thought it was a pretty sexy machine. I had one, too. He couldn’t wait to start programming it in BASIC.
Craig Cannon [01:10:50] – Very cool.
John Preskill [01:10:51] – Because that was so much fun.
Craig Cannon [01:10:52] – There was a question that I was kind of curious to your answer. Tika asks about essentially, teaching about quantum computers. They say, many kids in grade 10 can code. Some can play with machine learning tools without knowing the math. Can quantum computing become as simple and/or accessible?
John Preskill [01:11:17] – Maybe so. At some level, when people say quantum mechanics is counterintuitive, it’s hard for us to grasp, it’s so foreign to our experience, that’s true. The way things behave at the microscopic scale are, like we discussed earlier, really different from the way ordinary stuff behaves. But it’s a question of familiarity. What I wouldn’t be surprised by is that if you go out a few decades, kids who are 10 years old are going to be playing quantum games. That’s an application area that doesn’t get discussed very much, but there could be a real market there because people love games. Quantum games are different, and the strategies are different, and what you have to do to win is different. If you play the game enough, you start to get the hang of it.
John Preskill [01:12:26] – I don’t see any reason why kids who have not necessarily deeply studied physics can’t get a pretty good feel for how quantum mechanics works. You know, the way ordinary physics works, maybe it’s not so intuitive. Newton’s laws … Aristotle couldn’t get it right. He thought you had to keep pushing on something to get it to keep moving. That wasn’t right. Galileo was able to roll balls down a ramp, and things like that, and see he didn’t have to keep pushing to keep it moving. He could see that it was uniformly accelerated in a gravitational field. Newton took that to a much more general and powerful level. You fool around with stuff, and you get the hang of it. And I think quantum stuff can be like that. We’ll experience it in a different way, but when we have quantum computers, in a way, that opens the opportunity for trying things out and seeing what happens.
John Preskill [01:13:50] – After you’ve played the game enough, you start to anticipate. And actually, it’s an important point about the applications. One of the questions you asked me at the beginning was what are we able to do with quantum computers? And I said, I don’t know. So how are we going to discover new applications? It might just be, at least in part, by fooling around. A lot of classical algorithms that people use on today’s computers were discovered, or that they were powerful was discovered, by experimenting. By trying it. I don’t know … what’s an example of that? Well, the simplex method that we use in linear programming. I don’t think there was a mathematical proof that it was fast at first, but people did experiments, and they said, hey, this is pretty fast.
Craig Cannon [01:14:53] – Well, you’re seeing it a lot now in machine learning.
John Preskill [01:14:57] – Yeah, well that’s a good example.
Craig Cannon [01:14:58] – You test it out a million times over when you’re running simulations, and it turns out, that’s what works. Following the thread of education, and maybe your political interest, given it’s the year that it is, do you have thoughts on how you would adjust or change STEM education?
John Preskill [01:15:23] – Well, no particularly original thoughts. But I do think that STEM education … we shouldn’t think of it as we’re going to need this technical workforce, and so we better train them. The key thing is we want the general population to be able to reason effectively, and to recognize when an argument is phony and when it’s authentic. To think about, well how can I check whether what I just read on Facebook is really true? And I see that as part of the goal of STEM education. When you’re teaching kids in school how to understand the world by doing experiments, by looking at the evidence, by reasoning from the evidence, this is something that we apply in everyday life, too. I don’t know exactly how to implement this–
John Preskill [01:16:36] – But I think we should have that perspective that we’re trying to educate a public, which is going to eventually make critical decisions about our democracy, and they should understand how to tell when something is true or not. That’s a hard thing to do in general, but you know what I mean. That there are some things that, if you’re a person with some — I mean it doesn’t necessarily have to be technical — but if you’re used to evaluating evidence and making a judgment based on that evidence about whether it’s a good argument or not, you can apply that to all the things you hear and read, and make better judgments.
Craig Cannon [01:17:23] – What about on the policy side? Let’s see, JJ Francis asked that, if you or any of your colleagues would ever consider running for office. Curious about science policy in the US.
John Preskill [01:17:38] – Well, it would be good if we had more scientifically trained people in government. Very few members of Congress. I know of one, Bill Foster’s a physicist in Illinois. He was a particle physicist, and he worked at Fermilab, and now he’s in Congress, and very interested in the science and educational policy aspects of government. Rush Holt was a congressman from New Jersey who had a background in physics. He retired from the House a couple of years ago, but he was in Congress for something like 18 years, and he had a positive influence, because he had a voice that people respected when it came to science policy. Having more people like that would help. Now, another thing, it doesn’t have to be elective office.
Craig Cannon [01:18:39] – Right.
John Preskill [01:18:42] – There are a lot of technically trained people in government, many of them making their careers in agencies that deal with technical issues. Department of Defense, of course, there are a lot of technical issues. In the Obama Administration we had two successive secretaries of energy who were very, very good physicists. Steve Chu was Nobel Prize winning physicist. Then Ernie Moniz, who’s a real authority on nuclear energy and weapons. That kind of expertise makes a difference in government.
John Preskill [01:19:24] – Now the Secretary of Energy is Rick Perry. It’s a different background.
Craig Cannon [01:19:28] – Yeah, you could say that. Just kind of historical reference, what policies did they put in place that you really felt their hand as a physicist move forward?
John Preskill [01:19:44] – You mean in particular–
Craig Cannon [01:19:45] – I’m talking the Obama Administration.
John Preskill [01:19:49] – Well, I think the Department of Energy, DOE, tried to facilitate technical innovation by seeding new technologies, by supporting startup companies that were trying to do things that would improve battery technology, and solar power, and things like that, which could benefit future generations. They had an impact by doing that. You don’t have to be a Nobel Prize winning physicist to think that’s a good idea. That the administration felt that was a priority made a difference, and appointing a physicist at Department of Energy was, if nothing else, highly symbolic of how important those things are.
Craig Cannon [01:20:52] – On the quantum side, someone asked Vikas Karad, he asked where the Quantum Valley might be. Do you have thoughts, as in Silicon Valley for quantum computing?
John Preskill [01:21:06] – Well… I don’t know, but you look at what’s happening the last couple of years, there have been a number of quantum startups. A notable number of them are in the Bay Area. Why so? Well, that’s where the tech industry is concentrated and where the people who are interested in financing innovative technical startups are concentrated. If you are an entrepreneur interested in starting a company, and you’re concerned about how to fundraise for it, it kind of makes sense to locate in that area. Now, that’s what’s sort of happening now, and may not continue, of course. It might not be like that indefinitely. Nothing lasts forever, but I would say… That’s the place, Silicon Valley is likely to be Quantum Valley, the way things are right now.
Craig Cannon [01:22:10] – Well then what about the physicists who might be listening to this? If they’re thinking about starting a company, do you have advice for them?
John Preskill [01:22:22] – Just speaking very generally, if you’re putting a team together… Different people have different expertise. Take quantum computing as an example, like we were saying earlier, some of the big players and the startups, they want to do everything. They want to build the hardware, figure out better ways to fabricate it. Better control, better software, better applications. Nobody can be an expert on all those things. Of course, you’ll hire a software person to write your software, and microwave engineer to figure out your control, and of course that’s the right thing to do. But I think in that arena, and it probably applies to other entrepreneurial activity relating to physics, being able to communicate across those boundaries is very valuable, and you can see it in quantum computing now. That if the man or woman who’s involved in the software has that background, but there’s not a big communication barrier talking to the people who are doing the control engineering, that can be very helpful. It makes sense to give some preference to the people who maybe are comfortable doing so, or have the background that stretches across more than one of those areas of expertise. That can be very enabling in a technology arena like quantum computing today, where we’re trying to do really, really hard stuff, and you don’t know whether you’ll succeed, and you want to give it your best go by seeing the connections between those different things.
Craig Cannon [01:24:28] – Would you advise someone then to maybe teach or try and explain it to, I don’t know their young cousins? Because Feynman maybe recognizes the king of communicating physics, at least for a certain period of time. How would you advise someone to get better at it so they can be more effective?
John Preskill [01:24:50] – Practice. There are different aspects of that. This isn’t what you meant at all, but I’ll say it anyway, because what you asked brought it to mind. If you teach, you learn. We have this odd model in the research university that a professor like me is supposed to do research and teach. Why don’t we hire teachers and researchers? Why do we have the same people doing both? Well, part of the reason for me is most of what I know, what I’ve learned since my own school education ended, is knowledge I acquired by trying to teach it. To keep our intellect rejuvenated, we have to have that experience of trying to teach new things that we didn’t know that well before to other people. That deepens your knowledge. Just thinking about how you convey it makes you ask questions that you might not think to ask otherwise, and you say “Hey, I don’t know the answer to that.” Then you have to try to figure it out. So I think that applies at varying levels to any situation in which a scientist, or somebody with a technical background, is trying to communicate.
John Preskill [01:26:21] – By thinking about how to get it across to other people, we can get new insights, you know? We can look at it in a different way. It’s not a waste of time. Aside from the benefits of actually successfully communicating, we benefit from it in this other way. But other than that… Have fun with it, you know? Don’t look at it as a burden, or some kind of task you have to do along with all the other things you’re doing. It should be a pleasure. When it’s successful, it’s very gratifying. If you put a lot of thought into how to communicate something and you think people are getting it, that’s one of the ways that somebody in my line of work can get a lot of satisfaction.
Craig Cannon [01:27:23] – If now were to be your opportunity to teach a lot of people about physics, and you could just point someone to things, who would you advise someone to be? They want to learn more about quantum computing, they want to learn about physics. What should they be reading? What YouTube channel should they follow? What should they pay attention to?
John Preskill [01:27:44] – Well one communicator who I have great admiration for is Leonard Susskind, who’s at Stanford. You mentioned Feynman as the great communicator, and that’s fair, but in terms of style and personality of physicists who are currently active, I think Lenny Susskind is the most similar to Feynman of anyone I can think of. He’s a no bullshit kind of guy. He wants to give you the straight stuff. He doesn’t want to water it down for you. But he’s very gifted when it comes to making analogies and creating the illusion that you’re understanding what he’s saying. He has … if you just go to YouTube and search Leonard Susskind you’ll see lectures that he’s given at Stanford where they have some kind of extension school for people who are not Stanford students, people in the community. A lot of them in the tech community because it’s Stanford, and he’s giving courses. Yeah, and on quite sophisticated topics, but also on more basic topics, and he’s in the process of turning those into books. I’m not sure how many of those have appeared, but he has a series called The Theoretical Minimum
John Preskill [01:29:19] – which is supposed to be the gentle introduction to different topics like classical physics, quantum physics, and so on. He’s pretty special I think in his ability to do that.
Craig Cannon [01:29:32] – I need to subscribe. Actually, here’s a question then. In the things you’ve relearned while teaching over the past, I guess it’s 35 years now.
John Preskill [01:29:46] – Shit, is that right?
Craig Cannon [01:29:47] – Something like that.
John Preskill [01:29:48] – That’s true. Yeah.
Craig Cannon [01:29:51] – What were the big thing, what were the revelations?
John Preskill [01:29:55] – That’s how I learned quantum computing, for one thing. I was not at all knowledgeable about information science. That wasn’t my training. Back when I was in school, physicists didn’t learn much about things like information theory, computer science, complexity theory. One of the great things about quantum computing is its interdisciplinary character, that it brings these different things into contact, which traditionally had not been part of the common curriculum of any community of scholars. I decided 20 years ago that I should teach a quantum information class at Caltech, and I worked very hard on it that year. Not that I’m an expert, or anything, but I learned a lot about information theory, and things like channel capacity, and computational complexity — how we classify the hardness of problems — and algorithms. Things like that, which I didn’t really know very well. I had sort of a passing familiarity with some of those things from reading some of the quantum computing literature. That’s no substitute for teaching a class because then you really have to synthesize it and figure out your way of presenting it. Most of the notes are typed up and you can still get to them on my website.That was pretty transformative for me … and it was easier then, 20 years ago, I guess than it is now because it was such a new topic.
John Preskill [01:31:49] – But I really felt I was kind of close enough to the cutting edge on most of those topics by the time I’d finished the class that I wasn’t intimidated by another paper I’d read or a new thing I’d hear about those things. That was probably the one case where it really made a difference in my foundation of knowledge which enabled me to do things. But I had the same experience in particle physics. When I was a student, I read a lot. I was very broadly interested in physics. But when the first time, I was still at Harvard at the time –later I taught a similar course here — I’m in my late 20s, I’m just a year or two out of graduate school, and I decide to teach a very comprehensive class on elementary particles … in particular, quantum chromodynamics, the theory of nuclear forces like we talked about before. It just really expanded my knowledge to have that experience of teaching that class. I still draw on that. I can still remember that experience and I think I get ideas that I might not otherwise have because I went through that.
Craig Cannon [01:33:23] – I want to get involved now. I want to go back to school, or maybe teach a class. I don’t know.
John Preskill [01:33:27] – Well, what’s stopping you?
Two weeks ago I attended an exciting workshop at Stanford, organized by the It from Qubit collaboration, which I covered enthusiastically on Twitter. Many of the talks at the workshop provided fodder for possible blog posts, but one in particular especially struck my fancy. In explaining how to recover information that has fallen into a black hole (under just the right conditions), Juan Maldacena offered a new perspective on a problem that has worried me for many years. I am eagerly awaiting Juan’s paper, with Douglas Stanford and Zhenbin Yang, which will provide more details.
My cell-phone photo of Juan Maldacena lecturing at Stanford, 22 March 2017.
Almost 10 years ago I visited the Perimeter Institute to attend a conference, and by chance was assigned an office shared with Patrick Hayden. Patrick was a professor at McGill at that time, but I knew him well from his years at Caltech as a Sherman Fairchild Prize Fellow, and deeply respected him. Our proximity that week ignited a collaboration which turned out to be one of the most satisfying of my career.
To my surprise, Patrick revealed he had been thinking about black holes, a long-time passion of mine but not previously a research interest of his, and that he had already arrived at a startling insight which would be central to the paper we later wrote together. Patrick wondered what would happen if Alice possessed a black hole which happened to be highly entangled with a quantum computer held by Bob. He imagined Alice throwing a qubit into the black hole, after which Bob would collect the black hole’s Hawking radiation and feed it into his quantum computer for processing. Drawing on his knowledge about quantum communication through noisy channels, Patrick argued that Bob would only need to grab a few qubits from the radiation in order to salvage Alice’s qubit successfully by doing an appropriate quantum computation.
Alice tosses a qubit into a black hole, which is entangled with Bob’s quantum computer. Bob grabs some Hawking radiation, then does a quantum computation to decode Alice’s qubit.
This idea got my adrenaline pumping, stirring a vigorous dialogue. Patrick had initially assumed that the subsystem of the black hole ejected in the Hawking radiation had been randomly chosen, but we eventually decided (based on a simple picture of the quantum computation performed by the black hole) that it should take a time scaling like M log M (where M is the black hole mass expressed in Planck units) for Alice’s qubit to get scrambled up with the rest of her black hole. Only after this scrambling time would her qubit leak out in the Hawking radiation. This time is actually shockingly short, about a millisecond for a solar mass black hole. The best previous estimate for how long it would take for Alice’s qubit to emerge (scaling like M3), had been about 1067 years.
This short time scale aroused memories of discussions with Lenny Susskind back in 1993, vividly recreated in Lenny’s engaging book The Black Hole War. Because of the black hole’s peculiar geometry, it seemed conceivable that Bob could distill a copy of Alice’s qubit from the Hawking radiation and then leap into the black hole, joining Alice, who could then toss her copy of the qubit to Bob. It disturbed me that Bob would then hold two perfect copies of Alice’s qubit; I was a quantum information novice at the time, but I knew enough to realize that making a perfect clone of a qubit would violate the rules of quantum mechanics. I proposed to Lenny a possible resolution of this “cloning puzzle”: If Bob has to wait outside the black hole for too long in order to distill Alice’s qubit, then when he finally jumps in it may be too late for Alice’s qubit to catch up to Bob inside the black hole before Bob is destroyed by the powerful gravitational forces inside. Revisiting that scenario, I realized that the scrambling time M log M, though short, was just barely long enough for the story to be self-consistent. It was gratifying that things seemed to fit together so nicely, as though a deep truth were being affirmed.
If Bob decodes the Hawking radiation and then jumps into the black hole, can he acquire two identical copies of Alice’s qubit?
Patrick and I viewed our paper as a welcome opportunity to draw the quantum information and quantum gravity communities closer together, and we wrote it with both audiences in mind. We had fun writing it, adding rhetorical flourishes which we hoped would draw in readers who might otherwise be put off by unfamiliar ideas and terminology.
In their recent work, Juan and his collaborators propose a different way to think about the problem. They stripped down our Hawking radiation decoding scenario to a model so simple that it can be analyzed quite explicitly, yielding a pleasing result. What had worried me so much was that there seemed to be two copies of the same qubit, one carried into the black hole by Alice and the other residing outside the black hole in the Hawking radiation. I was alarmed by the prospect of a rendezvous of the two copies. Maldacena et al. argue that my concern was based on a misconception. There is just one copy, either inside the black hole or outside, but not both. In effect, as Bob extracts his copy of the qubit on the outside, he destroys Alice’s copy on the inside!
To reach this conclusion, several ideas are invoked. First, we analyze the problem in the case where we understand quantum gravity best, the case of a negatively curved spacetime called anti-de Sitter space. In effect, this trick allows us to trap a black hole inside a bottle, which is very advantageous because we can study the physics of the black hole by considering what happens on the walls of the bottle. Second, we envision Bob’s quantum computer as another black hole which is entangled with Alice’s black hole. When two black holes in anti-de Sitter space are entangled, the resulting geometry has a “wormhole” which connects together the interiors of the two black holes. Third, we chose the entangled pair of black holes to be in a very special quantum state, called the “thermofield double” state. This just means that the wormhole connecting the black holes is as short as possible. Fourth, to make the analysis even simpler, we suppose there is just one spatial dimension, which makes it easier to draw a picture of the spacetime. Now each wall of the bottle is just a point in space, with the left wall lying outside Bob’s side of the wormhole, and the right wall lying outside Alice’s side.
An important property of the wormhole is that it is not traversable. That is, when Alice throws her qubit into her black hole and it enters her end of the wormhole, the qubit cannot emerge from the other end. Instead it is stuck inside, unable to get out on either Alice’s side or Bob’s side. Most ways of manipulating the black holes from the outside would just make the wormhole longer and exacerbate the situation, but in a clever recent paper Ping Gao, Daniel Jafferis, and Aron Wall pointed out an exception. We can imagine a quantum wire connecting the left wall and right wall, which simulates a process in which Bob extracts a small amount of Hawking radiation from the right wall (that is, from Alice’s black hole), and carefully deposits it on the left wall (inserting it into Bob’s quantum computer). Gao, Jafferis, and Wall find that this procedure, by altering the trajectories of Alice’s and Bob’s walls, can actually make the wormhole traversable!
(a) A nontraversable wormhole. Alice’s qubit, thrown into the black hole, never reaches Bob. (b) Stealing some Hawking radiation from Alice’s side and inserting it on Bob’s side makes the wormhole traversable. Now Alice’s qubit reaches Bob, who can easily “decode” it.
This picture gives us a beautiful geometric interpretation of the decoding protocol that Patrick and I had described. It is the interaction between Alice’s wall and Bob’s wall that brings Alice’s qubit within Bob’s grasp. By allowing Alice’s qubit to reach Bob at the other end of the wormhole, that interaction suffices to perform Bob’s decoding task, which is especially easy in this case because Bob’s quantum computer was connected to Alice’s black hole by a short wormhole when she threw her qubit inside.
If, after a delay, Bob’s jumps into the black hole, he might find Alice’s qubit inside. But if he does, that qubit cannot be decoded by Bob’s quantum computer. Bob has no way to attain two copies of the qubit.
And what if Bob conducts his daring experiment, in which he decodes Alice’s qubit while still outside the black hole, and then jumps into the black hole to check whether the same qubit is also still inside? The above spacetime diagram contrasts two possible outcomes of Bob’s experiment. After entering the black hole, Alice might throw her qubit toward Bob so he can catch it inside the black hole. But if she does, then the qubit never reaches Bob’s quantum computer, and he won’t be able to decode it from the outside. On the other hand, Alice might allow her qubit to reach Bob’s quantum computer at the other end of the (now traversable) wormhole. But if she does, Bob won’t find the qubit when he enters the black hole. Either way, there is just one copy of the qubit, and no way to clone it. I shouldn’t have been so worried!
Granted, we have only described what happens in an oversimplified model of a black hole, but the lessons learned may be more broadly applicable. The case for broader applicability rests on a highly speculative idea, what Maldacena and Susskind called the ER=EPR conjecture, which I wrote about in this earlier blog post. One consequence of the conjecture is that a black hole highly entangled with a quantum computer is equivalent, after a transformation acting only on the computer, to two black holes connected by a short wormhole (though it might be difficult to actually execute that transformation). The insights of Gao-Jafferis-Wall and Maldacena-Stanford-Yang, together with the ER=EPR viewpoint, indicate that we don’t have to worry about the same quantum information being in two places at once. Quantum mechanics can survive the attack of the clones. Whew!
Thanks to Juan, Douglas, and Lenny for ongoing discussions and correspondence which have helped me to understand their ideas (including a lucid explanation from Douglas at our Caltech group meeting last Wednesday). This story is still unfolding and there will be more to say. These are exciting times!