When Scientific American writes that physicists are working on a theory of everything, does it sound ambitious enough to you? Do you lie awake at night thinking that a theory of everything should be able to explain, well, everything? What if that theory is founded on quantum mechanics and finds a way to explain gravitation through the microscopic laws of the quantum realm? Would that be a grand unified theory of everything?
The answer is no, for two different, but equally important reasons. First, there is the inherent assumption that quantum systems change in time according to Schrodinger’s evolution: 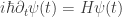 . Why? Where does that equation come from? Is it a fundamental law of nature, or is it an emergent relationship between different states of the universe? What if the parameter
. Why? Where does that equation come from? Is it a fundamental law of nature, or is it an emergent relationship between different states of the universe? What if the parameter  , which we call time, as well as the linear, self-adjoint operator
, which we call time, as well as the linear, self-adjoint operator  , which we call the Hamiltonian, are both emergent from a more fundamental, and highly typical phenomenon: the large amount of entanglement that is generically found when one decomposes the state space of a single, static quantum wavefunction, into two (different in size) subsystems: a clock and a space of configurations (on which our degrees of freedom live)? So many questions, so few answers.
, which we call the Hamiltonian, are both emergent from a more fundamental, and highly typical phenomenon: the large amount of entanglement that is generically found when one decomposes the state space of a single, static quantum wavefunction, into two (different in size) subsystems: a clock and a space of configurations (on which our degrees of freedom live)? So many questions, so few answers.
The static multiverse
The perceptive reader may have noticed that I italicized the word ‘static’ above, when referring to the quantum wavefunction of the multiverse. The emphasis on static is on purpose. I want to make clear from the beginning that a theory of everything can only be based on axioms that are truly fundamental, in the sense that they cannot be derived from more general principles as special cases. How would you know that your fundamental principles are irreducible? You start with set theory and go from there. If that assumes too much already, then you work on your set theory axioms. On the other hand, if you can exhibit a more general principle from which your original concept derives, then you are on the right path towards more fundamentalness.
In that sense, time and space as we understand them, are not fundamental concepts. We can imagine an object that can only be in one state, like a switch that is stuck at the OFF position, never changing or evolving in any way, and we can certainly consider a complete graph of interactions between subsystems (the equivalent of a black hole in what we think of as space) with no local geometry in our space of configurations. So what would be more fundamental than time and space? Let’s start with time: The notion of an unordered set of numbers, such as  , is a generalization of a clock, since we are only keeping the labels, but not their ordering. If we can show that a particular ordering emerges from a more fundamental assumption about the very existence of a theory of everything, then we have an understanding of time as a set of ordered labels, where each label corresponds to a particular configuration in the mathematical space containing our degrees of freedom. In that sense, the existence of the labels in the first place corresponds to a fundamental notion of potential for change, which is a prerequisite for the concept of time, which itself corresponds to constrained (ordered in some way) change from one label to the next. Our task is first to figure out where the labels of the clock come from, then where the illusion of evolution comes from in a static universe (Heisenberg evolution), and finally, where the arrow of time comes from in a macroscopic world (the illusion of irreversible evolution).
, is a generalization of a clock, since we are only keeping the labels, but not their ordering. If we can show that a particular ordering emerges from a more fundamental assumption about the very existence of a theory of everything, then we have an understanding of time as a set of ordered labels, where each label corresponds to a particular configuration in the mathematical space containing our degrees of freedom. In that sense, the existence of the labels in the first place corresponds to a fundamental notion of potential for change, which is a prerequisite for the concept of time, which itself corresponds to constrained (ordered in some way) change from one label to the next. Our task is first to figure out where the labels of the clock come from, then where the illusion of evolution comes from in a static universe (Heisenberg evolution), and finally, where the arrow of time comes from in a macroscopic world (the illusion of irreversible evolution).
The axioms we ultimately choose must satisfy the following conditions simultaneously: 1. the implications stemming from these assumptions are not contradicted by observations, 2. replacing any one of these assumptions by its negation would lead to observable contradictions, and 3. the assumptions contain enough power to specify non-trivial structures in our theory. In short, as Immanuel Kant put it in his accessible bedtime story The critique of Pure Reason, we are looking for synthetic a priori knowledge that can explain space and time, which ironically were Kant’s answer to that same question.
The fundamental ingredients of the ultimate theory
Before someone decides to delve into the math behind the emergence of unitarity (Heisenberg evolution) and the nature of time, there is another reason why the grand unified theory of everything has to do more than just give a complete theory of how the most elementary subsystems in our universe interact and evolve. What is missing is the fact that quantity has a quality all its own. In other words, patterns emerge from seemingly complex data when we zoom out enough. This “zooming out” procedure manifests itself in two ways in physics: as coarse-graining of the data and as truncation and renormalization. These simple ideas allow us to reduce the computational complexity of evaluating the next state of a complex system: If most of the complexity of the system is hidden at a level you cannot even observe (think pre retina-display era), then all you have to keep track of is information at the macroscopic, coarse-grained level. On top of that, you can use truncation and renormalization to zero in on the most likely/ highest weight configurations your coarse-grained data can be in – you can safely throw away a billion configurations, if their combined weight is less than 0.1% of the total, because your super-compressed data will still give you the right answer with a fidelity of 99.9%. This is how you get to reduce a 9 GB raw video file down to a 300 MB Youtube video that streams over your WiFi connection without losing too much of the video quality.
I will not focus on the second requirement for the “theory of everything”, the dynamics of apparent complexity. I think that this fundamental task is the purview of other sciences, such as chemistry, biology, anthropology and sociology, which look at the “laws” of physics from higher and higher vantage points (increasingly coarse-graining the topology of the space of possible configurations). Here, I would like to argue that the foundation on which a theory of everything rests, at the basement level if such a thing exists, consists of four ingredients: Math, Hilbert spaces with tensor decompositions into subsystems, stability and compressibility. Now, you know about math (though maybe not of Zermelo-Fraenkel set theory), you may have heard of Hilbert spaces if you majored in math and/or physics, but you don’t know what stability, or compressibility mean in this context. So let me motivate the last two with a question and then explain in more detail below: What are the most fundamental assumptions that we sweep under the rug whenever we set out to create a theory of anything that can fit in a book – or ten thousand books – and still have predictive power? Stability and compressibility.
Math and Hilbert spaces are fundamental in the following sense: A theory needs a Language in order to encode the data one can extract from that theory through synthesis and analysis. The data will be statistical in the most general case (with every configuration/state we attach a probability/weight of that state conditional on an ambient configuration space, which will often be a subset of the total configuration space), since any observer creating a theory of the universe around them only has access to a subset of the total degrees of freedom. The remaining degrees of freedom, what quantum physicists group as the Environment, affect our own observations through entanglement with our own degrees of freedom. To capture this richness of correlations between seemingly uncorrelated degrees of freedom, the mathematical space encoding our data requires more than just a metric (i.e. an ability to measure distances between objects in that space) – it requires an inner-product: a way to measure angles between different objects, or equivalently, the ability to measure the amount of overlap between an input configuration and an output configuration, thus quantifying the notion of incremental change. Such mathematical spaces are precisely the Hilbert spaces mentioned above and contain states (with wavefunctions being a special case of such states) and operators acting on the states (with measurements, rotations and general observables being special cases of such operators). But, let’s get back to stability and compressibility, since these two concepts are not standard in physics.
Stability
Stability is that quality that says that if the theory makes a prediction about something observable, then we can test our theory by making observations on the state of the world and, more importantly, new observations do not contradict our theory. How can a theory fall apart if it is unstable? One simple way is to make predictions that are untestable, since they are metaphysical in nature (think of religious tenets). Another way is to make predictions that work for one level of coarse-grained observations and fail for a lower level of finer coarse-graining (think of Newtonian Mechanics). A more extreme case involves quantum mechanics assumed to be the true underlying theory of physics, which could still fail to produce a stable theory of how the world works from our point of view. For example, say that your measurement apparatus here on earth is strongly entangled with the current state of a star that happens to go supernova 100 light-years from Earth during the time of your experiment. If there is no bound on the propagation speed of the information between these two subsystems, then your apparatus is engulfed in flames for no apparent reason and you get random data, where you expected to get the same “reproducible” statistics as last week. With no bound on the speed with which information can travel between subsystems of the universe, our ability to explain and/or predict certain observations goes out the window, since our data on these subsystems will look like white noise, an illusion of randomness stemming from the influence of inaccessible degrees of freedom acting on our measurement device. But stability has another dimension; that of continuity. We take for granted our ability to extrapolate the curve that fits 1000 data points on a plot. If we don’t assume continuity (and maybe even a certain level of smoothness) of the data, then all bets are off until we make more measurements and gather additional data points. But even then, we can never gather an infinite (let alone, uncountable) number of data points – we must extrapolate from what we have and assume that the full distribution of the data is close in norm to our current dataset (a norm is a measure of distance between states in the Hilbert space).
The emergence of the speed of light
The assumption of stability may seem trivial, but it holds within it an anthropic-style explanation for the bound on the speed of light. If there is no finite speed of propagation for the information between subsystems that are “far apart”, from our point of view, then we will most likely see randomness where there is order. A theory needs order. So, what does it mean to be “far apart” if we have made no assumption for the existence of an underlying geometry, or spacetime for that matter? There is a very important concept in mathematical physics that generalizes the concept of the speed of light for non-relativistic quantum systems whose subsystems live on a graph (i.e. where there may be no spatial locality or apparent geometry): the Lieb-Robinson velocity. Those of us working at the intersection of mathematical physics and quantum many-body physics, have seen first-hand the powerful results one can get from the existence of such an effective and emergent finite speed of propagation of information between quantum subsystems that, in principle, can signal to each other instantaneously through the action of a non-local unitary operator (rotation of the full system under Heisenberg evolution). It turns out that under certain natural assumptions on the graph of interactions between the different subsystems of a many-body quantum system, such a finite speed of light emerges naturally. The main requirement on the graph comes from the following intuitive picture: If each node in your graph is connected to only a few other nodes and the number of paths between any two nodes is bounded above in some nice way (say, polynomially in the distance between the nodes), then communication between two distant nodes will take time proportional to the distance between the nodes (in graph distance units, the smallest number of nodes among all paths connecting the two nodes). Why? Because at each time step you can only communicate with your neighbors and in the next time step they will communicate with theirs and so on, until one (and then another, and another) of these communication cascades reaches the other node. Since you have a bound on how many of these cascades will eventually reach the target node, the intensity of the communication wave is bounded by the effective action of a single messenger traveling along a typical path with a bounded speed towards the destination. There should be generalizations to weighted graphs, but this area of mathematical physics is still really active and new results on bounds on the Lieb-Robinson velocity gather attention very quickly.
Escaping black holes
If this idea holds any water, then black holes are indeed nearly complete graphs, where the notion of space and time breaks down, since there is no effective bound on the speed with which information propagates from one node to another. The only way to escape is to find yourself at the boundary of the complete graph, where the nodes of the black hole’s apparent horizon are connected to low-degree nodes outside. Once you get to a low-degree node, you need to keep moving towards other low-degree nodes in order to escape the “gravitational pull” of the black hole’s super-connectivity. In other words, gravitation in this picture is an entropic force: we gravitate towards massive objects for the same reason that we “gravitate” towards the direction of the arrow of time: we tend towards higher entropy configurations – the probability of reaching the neighborhood of a set of highly connected nodes is much, much higher than hanging out for long near a set of low-degree nodes in the same connected component of the graph. If a graph has disconnected components, then their is no way to communicate between the corresponding spacetimes – their states are in a tensor product with each other. One has to carefully define entanglement between components of a graph, before giving a unified picture of how spatial geometry arises from entanglement. Somebody get to it.
Erik Verlinde has introduced the idea of gravity as an entropic force and Fotini Markopoulou, et al. have introduced the notion of quantum graphity (gravity emerging from graph models). I think these approaches must be taken seriously, if only because they work with more fundamental principles than the ones found in Quantum Field Theory and General Relativity. After all, this type of blue sky thinking has led to other beautiful connections, such as ER=EPR (the idea that whenever two systems are entangled, they are connected by a wormhole). Even if we were to disagree with these ideas for some technical reason, we must admit that they are at least trying to figure out the fundamental principles that guide the things we take for granted. Of course, one may disagree with certain attempts at identifying unifying principles simply because the attempts lack the technical gravitas that allows for testing and calculations. Which is why a technical blog post on the emergence of time from entanglement is in the works.
Compressibility
So, what about that last assumption we seem to take for granted? How can you have a theory you can fit in a book about a sequence of events, or snapshots of the state of the observable universe, if these snapshots look like the static noise on a TV screen with no transmission signal? Well, you can’t! The fundamental concept here is Kolmogorov complexity and its connection to randomness/predictability. A sequence of data bits like:
10011010101101001110100001011010011101010111010100011010110111011110
has higher complexity (and hence looks more random/less predictable) than the sequence:
10101010101010101010101010101010101010101010101010101010101010101010
because there is a small computer program that can output each successive bit of the latter sequence (even if it had a million bits), but (most likely) not of the former. In particular, to get the second sequence with one million bits one can write the following short program:
string s = ’10’;
for n=1 to 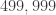 :
:
s.append(’10’);
n++;
end
print s;
As the number of bits grows, one may wonder if the number of iterations (given above by ), can be further compressed to make the program even smaller. The answer is yes: The number in binary requires 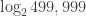 bits, but that binary number is a string of 0s and 1s, so it has its own Kolmogorov complexity, which may be smaller than . So, compressibility has a strong element of recursion, something that in physics we associate with scale invariance and fractals.
bits, but that binary number is a string of 0s and 1s, so it has its own Kolmogorov complexity, which may be smaller than . So, compressibility has a strong element of recursion, something that in physics we associate with scale invariance and fractals.
You may be wondering whether there are truly complex sequences of 0,1 bits, or if one can always find a really clever computer program to compress any N bit string down to, say, N/100 bits. The answer is interesting: There is no computer program that can compute the Kolmogorov complexity of an arbitrary string (the argument has roots in Berry’s Paradox), but there are strings of arbitrarily large Kolmogorov complexity (that is, no matter what program we use and what language we write it in, the smallest program (in bits) that outputs the N-bit string will be at least N bits long). In other words, there really are streams of data (in the form of bits) that are completely incompressible. In fact, a typical string of 0s and 1s will be almost completely incompressible!
Stability, compressibility and the arrow of time
So, what does compressibility have to do with the theory of everything? It has everything to do with it. Because, if we ever succeed in writing down such a theory in a physics textbook, we will have effectively produced a computer program that, given enough time, should be able to compute the next bit in the string that represents the data encoding the coarse-grained information we hope to extract from the state of the universe. In other words, the only reason the universe makes sense to us is because the data we gather about its state is highly compressible. This seems to imply that this universe is really, really special and completely atypical. Or is it the other way around? What if the laws of physics were non-existent? Would there be any consistent gravitational pull between matter to form galaxies and stars and planets? Would there be any predictability in the motion of the planets around suns? Forget about life, let alone intelligent life and the anthropic principle. Would the Earth, or Jupiter even know where to go next if it had no sense that it was part of a non-random plot in the movie that is spacetime? Would there be any notion of spacetime to begin with? Or an arrow of time? When you are given one thousand frames from one thousand different movies, there is no way to make a single coherent plot. Even the frames of a single movie would make little sense upon reshuffling.
What if the arrow of time emerged from the notions of stability and compressibility, through coarse-graining that acts as a compression algorithm for data that is inherently highly-complex and, hence, highly typical as the next move to make? If two strings of data look equally complex upon coarse-graining, but one of them has a billion more ways of appearing from the underlying raw data, then which one will be more likely to appear in the theory-of-everything book of our coarse-grained universe? Note that we need both high compressibility after coarse-graining in order to write down the theory, as well as large entropy before coarse-graining (from a large number of raw strings that all map to one string after coarse-graining), in order to have an arrow of time. It seems that we need highly-typical, highly complex strings that become easy to write down once we coarse grain the data in some clever way. Doesn’t that seem like a contradiction? How can a bunch of incompressible data become easily compressible upon coarse-graining? Here is one way: Take an N-bit string and define its 1-bit coarse-graining as the boolean AND of its digits. All but one strings will default to 0. The all 1s string will default to 1. Equally compressible, but the probability of seeing the 1 after coarse-graining is 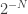 . With only 300 bits, finding the coarse-grained 1 is harder than looking for a specific atom in the observable universe. In other words, if the coarse-graining rule at time t is the one given above, then you can be pretty sure you will be seeing a 0 come up next in your data. Notice that before coarse-graining, all
. With only 300 bits, finding the coarse-grained 1 is harder than looking for a specific atom in the observable universe. In other words, if the coarse-graining rule at time t is the one given above, then you can be pretty sure you will be seeing a 0 come up next in your data. Notice that before coarse-graining, all 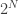 strings are equally likely, so there is no arrow of time, since there is no preferred string from a probabilistic point of view.
strings are equally likely, so there is no arrow of time, since there is no preferred string from a probabilistic point of view.
Conclusion, for now
When we think about the world around us, we go to our intuitions first as a starting point for any theory describing the multitude of possible experiences (observable states of the world). If we are to really get to the bottom of this process, it seems fruitful to ask “why do I assume this?” and “is that truly fundamental or can I derive it from something else that I already assumed was an independent axiom?” One of the postulates of quantum mechanics is the axiom corresponding to the evolution of states under Schrodinger’s equation. We will attempt to derive that equation from the other postulates in an upcoming post. Until then, your help is wanted with the march towards more fundamental principles that explain our seemingly self-evident truths. Question everything, especially when you think you really figured things out. Start with this post. After all, a theory of everything should be able to explain itself.
UP NEXT: Entanglement, Schmidt decomposition, concentration measure bounds and the emergence of discrete time and unitary evolution.



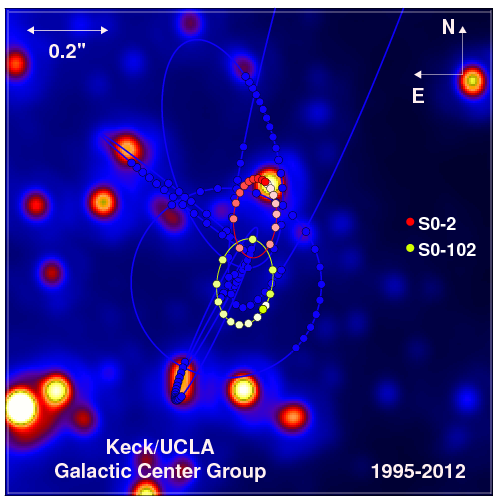
 solar masses. Some of the most convincing evidence comes from the picture below.
solar masses. Some of the most convincing evidence comes from the picture below.  solar masses. Measurements in the radio spectrum show that there is a radio source located in the same location which we call Sagittarius A* (Sgr A*). Sgr A* is moving at less than
solar masses. Measurements in the radio spectrum show that there is a radio source located in the same location which we call Sagittarius A* (Sgr A*). Sgr A* is moving at less than  and has a mass of at least
and has a mass of at least 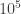 solar masses. These bounds make it pretty clear that Sgr A* is the same object as what is at the focus of these orbits. A radio source is exactly what you would expect for this system because as
solar masses. These bounds make it pretty clear that Sgr A* is the same object as what is at the focus of these orbits. A radio source is exactly what you would expect for this system because as